 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Legal Concept Interpretation with LLMs: Retrieval, Generation, and Evaluation
Jan 03, 2025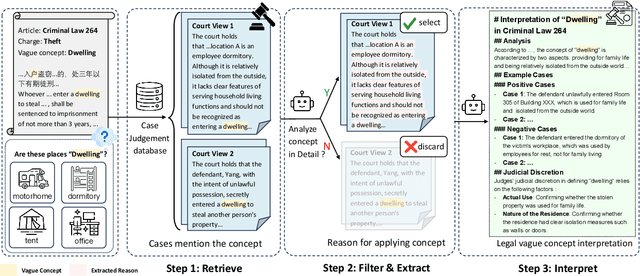
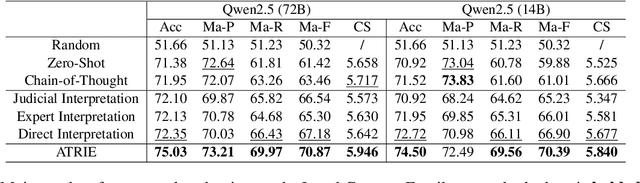


Legal articles often include vague concepts to adapt to the ever-changing society. Providing detailed interpretations of these concepts is a critical task for legal practitioners, which requires meticulous and professional annotations by legal experts, admittedly time-consuming and expensive to collect at scale. In this paper, we introduce a novel retrieval-augmented generation framework, ATRI, for AuTomatically Retrieving relevant information from past judicial precedents and Interpreting vague legal concepts. We further propose a new benchmark, Legal Concept Entailment, to automate the evaluation of generated concept interpretations without expert involvement. Automatic evaluations indicate that our generated interpretations can effectively assist large language models (LLMs) in understanding vague legal concepts. Multi-faceted evaluations by legal experts indicate that the quality of our concept interpretations is comparable to those written by human experts. Our work has strong implications for leveraging LLMs to support legal practitioners in interpreting vague legal concepts and beyond.
Agents on the Bench: Large Language Model Based Multi Agent Framework for Trustworthy Digital Justice
Dec 24, 2024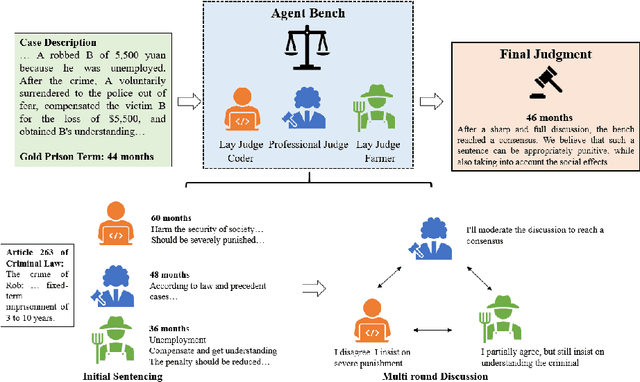
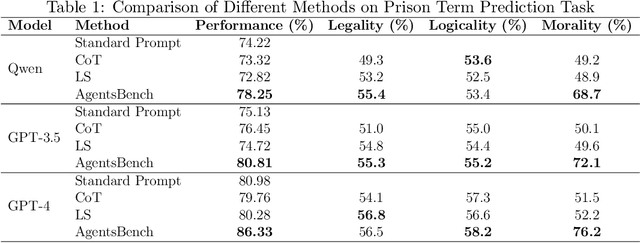
The justice system has increasingly employed AI techniques to enhance efficiency, yet limitations remain in improving the quality of decision-making, particularly regarding transparency and explainability needed to uphold public trust in legal AI. To address these challenges, we propose a large language model based multi-agent framework named AgentsBench, which aims to simultaneously improve both efficiency and quality in judicial decision-making. Our approach leverages multiple LLM-driven agents that simulate the collaborative deliberation and decision making process of a judicial bench. We conducted experiments on legal judgment prediction task, and the results show that our framework outperforms existing LLM based methods in terms of performance and decision quality. By incorporating these elements, our framework reflects real-world judicial processes more closely, enhancing accuracy, fairness, and society consideration. AgentsBench provides a more nuanced and realistic methods of trustworthy AI decision-making, with strong potential for application across various case types and legal scenarios.
TNDDR: Efficient and doubly robust estimation of COVID-19 vaccine effectiveness under the test-negative design
Oct 06, 2023While the test-negative design (TND), which is routinely used for monitoring seasonal flu vaccine effectiveness (VE), has recently become integral to COVID-19 vaccine surveillance, it is susceptible to selection bias due to outcome-dependent sampling. Some studies have addressed the identifiability and estimation of causal parameters under the TND, but efficiency bounds for nonparametric estimators of the target parameter under the unconfoundedness assumption have not yet been investigated. We propose a one-step doubly robust and locally efficient estimator called TNDDR (TND doubly robust), which utilizes sample splitting and can incorporate machine learning techniques to estimate the nuisance functions. We derive the efficient influence function (EIF) for the marginal expectation of the outcome under a vaccination intervention, explore the von Mises expansion, and establish the conditions for $\sqrt{n}-$consistency, asymptotic normality and double robustness of TNDDR. The proposed TNDDR is supported by both theoretical and empirical justifications, and we apply it to estimate COVID-19 VE in an administrative dataset of community-dwelling older people (aged $\geq 60$y) in the province of Qu\'ebec, Canada.
Legal Syllogism Prompting: Teaching Large Language Models for Legal Judgment Prediction
Jul 17, 2023


Legal syllogism is a form of deductive reasoning commonly used by legal professionals to analyze cases. In this paper, we propose legal syllogism prompting (LoT), a simple prompting method to teach large language models (LLMs) for legal judgment prediction. LoT teaches only that in the legal syllogism the major premise is law, the minor premise is the fact, and the conclusion is judgment. Then the models can produce a syllogism reasoning of the case and give the judgment without any learning, fine-tuning, or examples. On CAIL2018, a Chinese criminal case dataset, we performed zero-shot judgment prediction experiments with GPT-3 models. Our results show that LLMs with LoT achieve better performance than the baseline and chain of thought prompting, the state-of-art prompting method on diverse reasoning tasks. LoT enables the model to concentrate on the key information relevant to the judgment and to correctly understand the legal meaning of acts, as compared to other methods. Our method enables LLMs to predict judgment along with law articles and justification, which significantly enhances the explainability of models.
Lawyer LLaMA Technical Report
May 24, 2023



Large Language Models (LLMs), like LLaMA, have exhibited remarkable performances across various tasks. Nevertheless, when deployed to specific domains such as law or medicine, the models still confront the challenge of a deficiency in domain-specific knowledge and an inadequate capability to leverage that knowledge to resolve domain-related problems. In this paper, we focus on the legal domain and explore how to inject domain knowledge during the continual training stage and how to design proper supervised finetune tasks to help the model tackle practical issues. Moreover, to alleviate the hallucination problem during model's generation, we add a retrieval module and extract relevant articles before the model answers any queries. Augmenting with the extracted evidence, our model could generate more reliable responses. We release our data and model at https://github.com/AndrewZhe/lawyer-llama.
Do Charge Prediction Models Learn Legal Theory?
Oct 31, 2022The charge prediction task aims to predict the charge for a case given its fact description. Recent models have already achieved impressive accuracy in this task, however, little is understood about the mechanisms they use to perform the judgment.For practical applications, a charge prediction model should conform to the certain legal theory in civil law countries, as under the framework of civil law, all cases are judged according to certain local legal theories. In China, for example, nearly all criminal judges make decisions based on the Four Elements Theory (FET).In this paper, we argue that trustworthy charge prediction models should take legal theories into consideration, and standing on prior studies in model interpretation, we propose three principles for trustworthy models should follow in this task, which are sensitive, selective, and presumption of innocence.We further design a new framework to evaluate whether existing charge prediction models learn legal theories. Our findings indicate that, while existing charge prediction models meet the selective principle on a benchmark dataset, most of them are still not sensitive enough and do not satisfy the presumption of innocence. Our code and dataset are released at https://github.com/ZhenweiAn/EXP_LJP.