 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents on the Bench: Large Language Model Based Multi Agent Framework for Trustworthy Digital Justice
Dec 24, 2024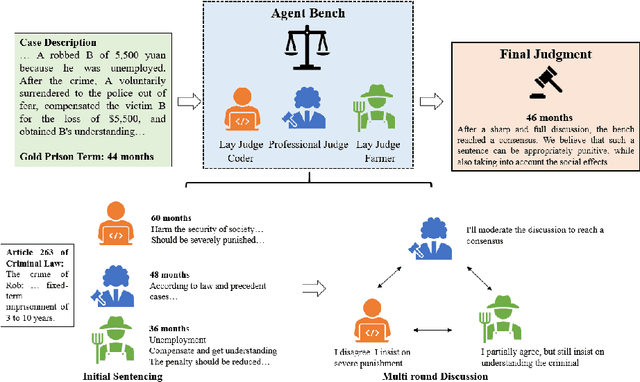
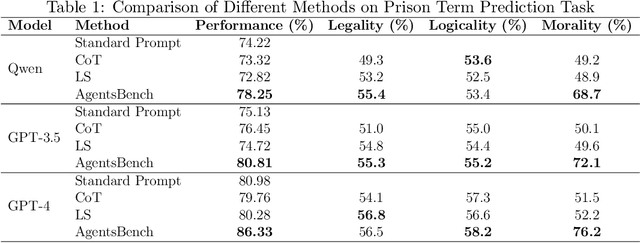
The justice system has increasingly employed AI techniques to enhance efficiency, yet limitations remain in improving the quality of decision-making, particularly regarding transparency and explainability needed to uphold public trust in legal AI. To address these challenges, we propose a large language model based multi-agent framework named AgentsBench, which aims to simultaneously improve both efficiency and quality in judicial decision-making. Our approach leverages multiple LLM-driven agents that simulate the collaborative deliberation and decision making process of a judicial bench. We conducted experiments on legal judgment prediction task, and the results show that our framework outperforms existing LLM based methods in terms of performance and decision quality. By incorporating these elements, our framework reflects real-world judicial processes more closely, enhancing accuracy, fairness, and society consideration. AgentsBench provides a more nuanced and realistic methods of trustworthy AI decision-making, with strong potential for application across various case types and legal scenarios.
Joint SIM Configuration and Power Allocation for Stacked Intelligent Metasurface-assisted MU-MISO Systems with TD3
Aug 11, 2024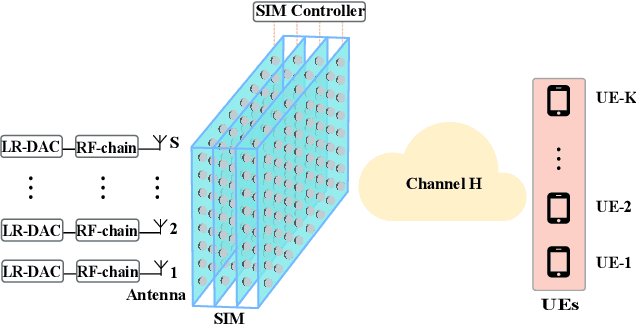
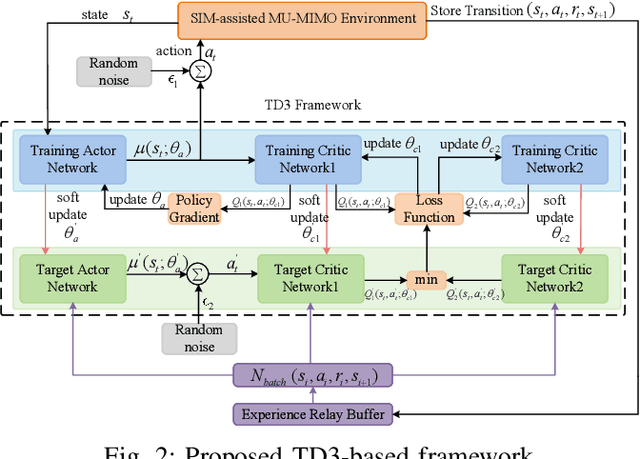
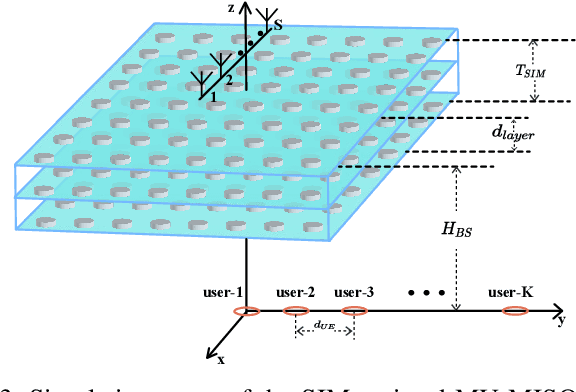
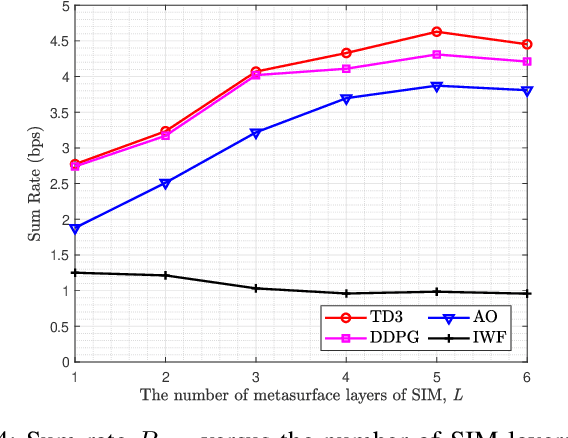
The stacked intelligent metasurface (SIM) emerges as an innovative technology with the ability to directly manipulate electromagnetic (EM) wave signals, drawing parallels to the operational principles of artificial neural networks (ANN). Leveraging its structure for direct EM signal processing alongside its low-power consumption, SIM holds promise for enhancing system performance within wireless communication systems. In this paper, we focus on SIM-assisted multi-user multi-input and single-output (MU-MISO) system downlink scenarios in the transmitter. We proposed a joint optimization method for SIM phase shift configuration and antenna power allocation based on the twin delayed deep deterministic policy gradient (TD3) algorithm to efficiently improve the sum rate. The results show that the proposed algorithm outperforms both deep deterministic policy gradient (DDPG) and alternating optimization (AO) algorithms. Furthermore, increasing the number of meta-atoms per layer of the SIM is always beneficial. However, continuously increasing the number of layers of SIM does not lead to sustained performance improvement.
Time integration schemes based on neural networks for solving partial differential equations on coarse grids
Oct 16, 2023



The accuracy of solving partial differential equations (PDEs) on coarse grids is greatly affected by the choice of discretization schemes. In this work, we propose to learn time integration schemes based on neural networks which satisfy three distinct sets of mathematical constraints, i.e., unconstrained, semi-constrained with the root condition, and fully-constrained with both root and consistency conditions. We focus on the learning of 3-step linear multistep methods, which we subsequently applied to solve three model PDEs, i.e., the one-dimensional heat equation, the one-dimensional wave equation, and the one-dimensional Burgers' equation. The results show that the prediction error of the learned fully-constrained scheme is close to that of the Runge-Kutta method and Adams-Bashforth method. Compared to the traditional methods, the learned unconstrained and semi-constrained schemes significantly reduce the prediction error on coarse grids. On a grid that is 4 times coarser than the reference grid, the mean square error shows a reduction of up to an order of magnitude for some of the heat equation cases, and a substantial improvement in phase prediction for the wave equation. On a 32 times coarser grid, the mean square error for the Burgers' equation can be reduced by up to 35% to 40%.
Legal Syllogism Prompting: Teaching Large Language Models for Legal Judgment Prediction
Jul 17, 2023


Legal syllogism is a form of deductive reasoning commonly used by legal professionals to analyze cases. In this paper, we propose legal syllogism prompting (LoT), a simple prompting method to teach large language models (LLMs) for legal judgment prediction. LoT teaches only that in the legal syllogism the major premise is law, the minor premise is the fact, and the conclusion is judgment. Then the models can produce a syllogism reasoning of the case and give the judgment without any learning, fine-tuning, or examples. On CAIL2018, a Chinese criminal case dataset, we performed zero-shot judgment prediction experiments with GPT-3 models. Our results show that LLMs with LoT achieve better performance than the baseline and chain of thought prompting, the state-of-art prompting method on diverse reasoning tasks. LoT enables the model to concentrate on the key information relevant to the judgment and to correctly understand the legal meaning of acts, as compared to other methods. Our method enables LLMs to predict judgment along with law articles and justification, which significantly enhances the explainability of models.