 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJUREX-4E: Juridical Expert-Annotated Four-Element Knowledge Base for Legal Reasoning
Feb 24, 2025The Four-Element Theory is a fundamental framework in criminal law, defining the constitution of crime through four dimensions: Subject, Object, Subjective aspect, and Objective aspect. This theory is widely referenced in legal reasoning, and many Large Language Models (LLMs) attempt to incorporate it when handling legal tasks. However, current approaches rely on LLMs' internal knowledge to incorporate this theory, often lacking completeness and representativeness. To address this limitation, we introduce JUREX-4E, an expert-annotated knowledge base covering 155 criminal charges. It is structured through a progressive hierarchical annotation framework that prioritizes legal source validity and employs diverse legal interpretation methods to ensure comprehensiveness and authority. We evaluate JUREX-4E on the Similar Charge Distinction task and apply it to Legal Case Retrieval, demonstrating its effectiveness in improving LLM performance. Experimental results validate the high quality of JUREX-4E and its substantial impact on downstream legal tasks, underscoring its potential for advancing legal AI applications. Code: https://github.com/THUlawtech/JUREX
Automating Legal Concept Interpretation with LLMs: Retrieval, Generation, and Evaluation
Jan 03, 2025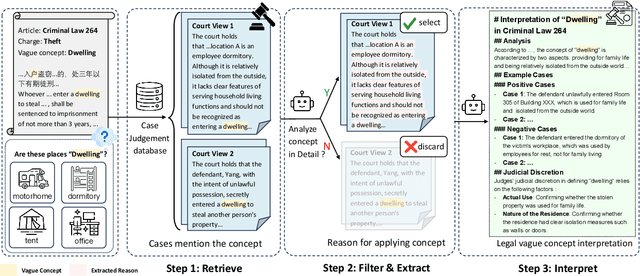
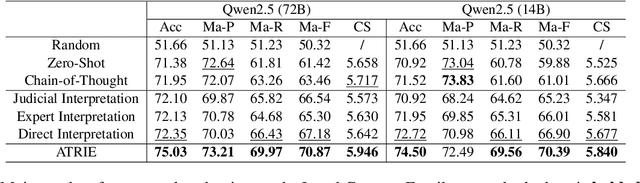


Legal articles often include vague concepts to adapt to the ever-changing society. Providing detailed interpretations of these concepts is a critical task for legal practitioners, which requires meticulous and professional annotations by legal experts, admittedly time-consuming and expensive to collect at scale. In this paper, we introduce a novel retrieval-augmented generation framework, ATRI, for AuTomatically Retrieving relevant information from past judicial precedents and Interpreting vague legal concepts. We further propose a new benchmark, Legal Concept Entailment, to automate the evaluation of generated concept interpretations without expert involvement. Automatic evaluations indicate that our generated interpretations can effectively assist large language models (LLMs) in understanding vague legal concepts. Multi-faceted evaluations by legal experts indicate that the quality of our concept interpretations is comparable to those written by human experts. Our work has strong implications for leveraging LLMs to support legal practitioners in interpreting vague legal concepts and beyond.
Pyramidal Flow Matching for Efficient Video Generative Modeling
Oct 08, 2024Video generation requires modeling a vast spatiotemporal space, which demands significant computational resources and data usage. To reduce the complexity, the prevailing approaches employ a cascaded architecture to avoid direct training with full resolution. Despite reducing computational demands, the separate optimization of each sub-stage hinders knowledge sharing and sacrifices flexibility. This work introduces a unified pyramidal flow matching algorithm. It reinterprets the original denoising trajectory as a series of pyramid stages, where only the final stage operates at the full resolution, thereby enabling more efficient video generative modeling. Through our sophisticated design, the flows of different pyramid stages can be interlinked to maintain continuity. Moreover, we craft autoregressive video generation with a temporal pyramid to compress the full-resolution history. The entire framework can be optimized in an end-to-end manner and with a single unified Diffusion Transformer (DiT). Extensive experiments demonstrate that our method supports generating high-quality 5-second (up to 10-second) videos at 768p resolution and 24 FPS within 20.7k A100 GPU training hours. All code and models will be open-sourced at https://pyramid-flow.github.io.
Only One Relation Possible? Modeling the Ambiguity in Event Temporal Relation Extraction
Aug 14, 2024Event Temporal Relation Extraction (ETRE) aims to identify the temporal relationship between two events, which plays an important role in natural language understanding. Most previous works follow a single-label classification style, classifying an event pair into either a specific temporal relation (e.g., \textit{Before}, \textit{After}), or a special label \textit{Vague} when there may be multiple possible temporal relations between the pair. In our work, instead of directly making predictions on \textit{Vague}, we propose a multi-label classification solution for ETRE (METRE) to infer the possibility of each temporal relation independently, where we treat \textit{Vague} as the cases when there is more than one possible relation between two events. We design a speculation mechanism to explore the possible relations hidden behind \textit{Vague}, which enables the latent information to be used efficiently. Experiments on TB-Dense, MATRES and UDS-T show that our method can effectively utilize the \textit{Vague} instances to improve the recognition for specific temporal relations and outperforms most state-of-the-art methods.
Unlocking the Potential of Model Merging for Low-Resource Languages
Jul 04, 2024



Adapting large language models (LLMs) to new languages typically involves continual pre-training (CT) followed by supervised fine-tuning (SFT). However, this CT-then-SFT approach struggles with limited data in the context of low-resource languages, failing to balance language modeling and task-solving capabilities. We thus propose model merging as an alternative for low-resource languages, combining models with distinct capabilities into a single model without additional training. We use model merging to develop task-solving LLMs for low-resource languages without SFT data in the target languages. Our experiments based on Llama-2-7B demonstrate that model merging effectively endows LLMs for low-resource languages with task-solving abilities, outperforming CT-then-SFT in scenarios with extremely scarce data. Observing performance saturation in model merging with more training tokens, we further analyze the merging process and introduce a slack variable to the model merging algorithm to mitigate the loss of important parameters, thereby enhancing performance. We hope that model merging can benefit more human languages suffering from data scarcity with its higher data efficiency.
What Kinds of Tokens Benefit from Distant Text? An Analysis on Long Context Language Modeling
Jun 17, 2024

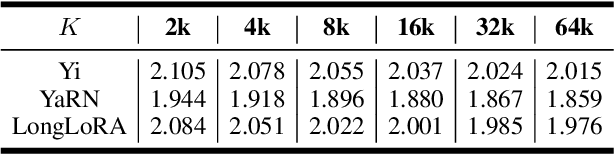

As the context length that large language models can handle continues to increase, these models demonstrate an enhanced ability to utilize distant information for tasks such as language modeling. This capability contrasts with human reading and writing habits, where it is uncommon to remember and use particularly distant information, except in cases of foreshadowing. In this paper, we aim to explore which kinds of words benefit more from long contexts in language models. By analyzing the changes in token probabilities with increasing context length, we find that content words (e.g., nouns, adjectives) and the initial tokens of words benefit the most. Frequent patterns in the context (N-grams) also significantly impact predictions. Additionally, the model's prior knowledge plays a crucial role in influencing predictions, especially for rare tokens. We also observe that language models become more confident with longer contexts, resulting in sharper probability distributions. This overconfidence may contribute to the increasing probabilities of tokens with distant contextual information. We hope that our analysis will help the community better understand long-text language modeling and contribute to the design of more reliable long-context models.
Can Perplexity Reflect Large Language Model's Ability in Long Text Understanding?
May 09, 2024
Recent studies have shown that Large Language Models (LLMs) have the potential to process extremely long text. Many works only evaluate LLMs' long-text processing ability on the language modeling task, with perplexity (PPL) as the evaluation metric. However, in our study, we find that there is no correlation between PPL and LLMs' long-text understanding ability. Besides, PPL may only reflect the model's ability to model local information instead of catching long-range dependency. Therefore, only using PPL to prove the model could process long text is inappropriate. The local focus feature of PPL could also explain some existing phenomena, such as the great extrapolation ability of the position method ALiBi. When evaluating a model's ability in long text, we might pay more attention to PPL's limitation and avoid overly relying on it.
Harder Tasks Need More Experts: Dynamic Routing in MoE Models
Mar 12, 2024In this paper, we introduce a novel dynamic expert selection framework for Mixture of Experts (MoE) models, aiming to enhance computational efficiency and model performance by adjusting the number of activated experts based on input difficulty. Unlike traditional MoE approaches that rely on fixed Top-K routing, which activates a predetermined number of experts regardless of the input's complexity, our method dynamically selects experts based on the confidence level in expert selection for each input. This allows for a more efficient utilization of computational resources, activating more experts for complex tasks requiring advanced reasoning and fewer for simpler tasks. Through extensive evaluations, our dynamic routing method demonstrates substantial improvements over conventional Top-2 routing across various benchmarks, achieving an average improvement of 0.7% with less than 90% activated parameters. Further analysis shows our model dispatches more experts to tasks requiring complex reasoning skills, like BBH, confirming its ability to dynamically allocate computational resources in alignment with the input's complexity. Our findings also highlight a variation in the number of experts needed across different layers of the transformer model, offering insights into the potential for designing heterogeneous MoE frameworks. The code and models are available at https://github.com/ZhenweiAn/Dynamic_MoE.
Probing Multimodal Large Language Models for Global and Local Semantic Representation
Feb 27, 2024



The success of large language models has inspired researchers to transfer their exceptional representing ability to other modalities. Several recent works leverage image-caption alignment datasets to train multimodal large language models (MLLMs), which achieve state-of-the-art performance on image-to-text tasks. However, there are very few studies exploring whether MLLMs truly understand the complete image information, i.e., global information, or if they can only capture some local object information. In this study, we find that the intermediate layers of models can encode more global semantic information, whose representation vectors perform better on visual-language entailment tasks, rather than the topmost layers. We further probe models for local semantic representation through object detection tasks. And we draw a conclusion that the topmost layers may excessively focus on local information, leading to a diminished ability to encode global information.
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization
Feb 06, 2024



In light of recent advances in multimodal Large Language Models (LLMs), there is increasing attention to scaling them from image-text data to more informative real-world videos. Compared to static images, video poses unique challenges for effective large-scale pre-training due to the modeling of its spatiotemporal dynamics. In this paper, we address such limitations in video-language pre-training with an efficient video decomposition that represents each video as keyframes and temporal motions. These are then adapted to an LLM using well-designed tokenizers that discretize visual and temporal information as a few tokens, thus enabling unified generative pre-training of videos, images, and text. At inference, the generated tokens from the LLM are carefully recovered to the original continuous pixel space to create various video content. Our proposed framework is both capable of comprehending and generating image and video content, as demonstrated by its competitive performance across 13 multimodal benchmarks in image and video understanding and generation. Our code and models will be available at https://video-lavit.github.io.