 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD$^2$Plan: Dual-Agent Dynamic Global Planning for Complex Retrieval-Augmented Reasoning
Jan 13, 2026Recent search-augmented LLMs trained with reinforcement learning (RL) can interleave searching and reasoning for multi-hop reasoning tasks. However, they face two critical failure modes as the accumulating context becomes flooded with both crucial evidence and irrelevant information: (1) ineffective search chain construction that produces incorrect queries or omits retrieval of critical information, and (2) reasoning hijacking by peripheral evidence that causes models to misidentify distractors as valid evidence. To address these challenges, we propose **D$^2$Plan**, a **D**ual-agent **D**ynamic global **Plan**ning paradigm for complex retrieval-augmented reasoning. **D$^2$Plan** operates through the collaboration of a *Reasoner* and a *Purifier*: the *Reasoner* constructs explicit global plans during reasoning and dynamically adapts them based on retrieval feedback; the *Purifier* assesses retrieval relevance and condenses key information for the *Reasoner*. We further introduce a two-stage training framework consisting of supervised fine-tuning (SFT) cold-start on synthesized trajectories and RL with plan-oriented rewards to teach LLMs to master the **D$^2$Plan** paradigm. Extensive experiments demonstrate that **D$^2$Plan** enables more coherent multi-step reasoning and stronger resilience to irrelevant information, thereby achieving superior performance on challenging QA benchmarks.
Automating Legal Concept Interpretation with LLMs: Retrieval, Generation, and Evaluation
Jan 03, 2025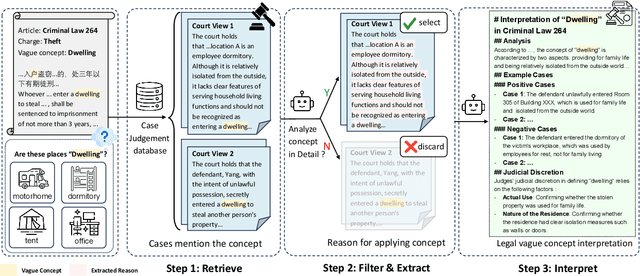
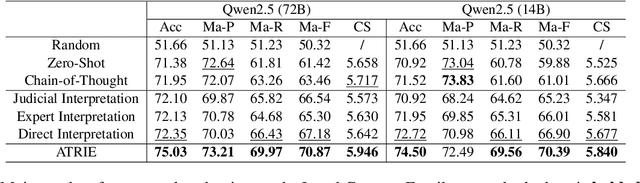


Legal articles often include vague concepts to adapt to the ever-changing society. Providing detailed interpretations of these concepts is a critical task for legal practitioners, which requires meticulous and professional annotations by legal experts, admittedly time-consuming and expensive to collect at scale. In this paper, we introduce a novel retrieval-augmented generation framework, ATRI, for AuTomatically Retrieving relevant information from past judicial precedents and Interpreting vague legal concepts. We further propose a new benchmark, Legal Concept Entailment, to automate the evaluation of generated concept interpretations without expert involvement. Automatic evaluations indicate that our generated interpretations can effectively assist large language models (LLMs) in understanding vague legal concepts. Multi-faceted evaluations by legal experts indicate that the quality of our concept interpretations is comparable to those written by human experts. Our work has strong implications for leveraging LLMs to support legal practitioners in interpreting vague legal concepts and beyond.
ELLA: Empowering LLMs for Interpretable, Accurate and Informative Legal Advice
Aug 13, 2024
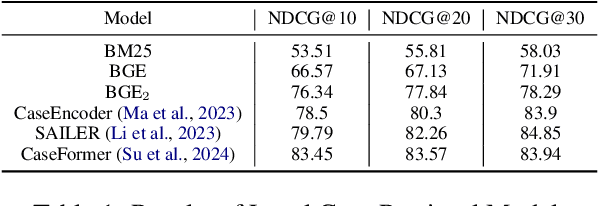
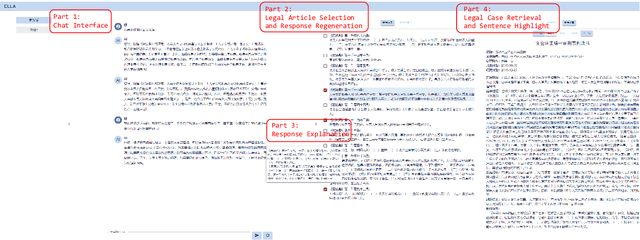

Despite remarkable performance in legal consultation exhibited by legal Large Language Models(LLMs) combined with legal article retrieval components, there are still cases when the advice given is incorrect or baseless. To alleviate these problems, we propose {\bf ELLA}, a tool for {\bf E}mpowering {\bf L}LMs for interpretable, accurate, and informative {\bf L}egal {\bf A}dvice. ELLA visually presents the correlation between legal articles and LLM's response by calculating their similarities, providing users with an intuitive legal basis for the responses. Besides, based on the users' queries, ELLA retrieves relevant legal articles and displays them to users. Users can interactively select legal articles for LLM to generate more accurate responses. ELLA also retrieves relevant legal cases for user reference. Our user study shows that presenting the legal basis for the response helps users understand better. The accuracy of LLM's responses also improves when users intervene in selecting legal articles for LLM. Providing relevant legal cases also aids individuals in obtaining comprehensive information.
What Kinds of Tokens Benefit from Distant Text? An Analysis on Long Context Language Modeling
Jun 17, 2024As the context length that large language models can handle continues to increase, these models demonstrate an enhanced ability to utilize distant information for tasks such as language modeling. This capability contrasts with human reading and writing habits, where it is uncommon to remember and use particularly distant information, except in cases of foreshadowing. In this paper, we aim to explore which kinds of words benefit more from long contexts in language models. By analyzing the changes in token probabilities with increasing context length, we find that content words (e.g., nouns, adjectives) and the initial tokens of words benefit the most. Frequent patterns in the context (N-grams) also significantly impact predictions. Additionally, the model's prior knowledge plays a crucial role in influencing predictions, especially for rare tokens. We also observe that language models become more confident with longer contexts, resulting in sharper probability distributions. This overconfidence may contribute to the increasing probabilities of tokens with distant contextual information. We hope that our analysis will help the community better understand long-text language modeling and contribute to the design of more reliable long-context models.
PACE: Improving Prompt with Actor-Critic Editing for Large Language Model
Aug 19, 2023



Large language models (LLMs) have showcased remarkable potential across various tasks by conditioning on prompts. However, the quality of different human-written prompts leads to substantial discrepancies in LLMs' performance, and improving prompts usually necessitates considerable human effort and expertise. To this end, this paper proposes Prompt with Actor-Critic Editing (PACE) for LLMs to enable automatic prompt editing. Drawing inspiration from the actor-critic algorithm in reinforcement learning, PACE leverages LLMs as the dual roles of actors and critics, conceptualizing prompt as a type of policy. PACE refines prompt, taking into account the feedback from both actors performing prompt and critics criticizing response. This process helps LLMs better align prompt to a specific task, thanks to real responses and thinking from LLMs. We conduct extensive experiments on 24 instruction induction tasks and 21 big-bench tasks. Experimental results indicate that PACE elevates the relative performance of medium/low-quality human-written prompts by up to 98\%, which has comparable performance to high-quality human-written prompts. Moreover, PACE also exhibits notable efficacy for prompt generation.