 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Kinds of Tokens Benefit from Distant Text? An Analysis on Long Context Language Modeling
Paper and Code
Jun 17, 2024

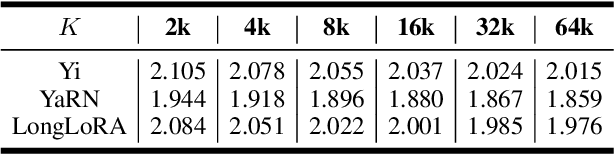

As the context length that large language models can handle continues to increase, these models demonstrate an enhanced ability to utilize distant information for tasks such as language modeling. This capability contrasts with human reading and writing habits, where it is uncommon to remember and use particularly distant information, except in cases of foreshadowing. In this paper, we aim to explore which kinds of words benefit more from long contexts in language models. By analyzing the changes in token probabilities with increasing context length, we find that content words (e.g., nouns, adjectives) and the initial tokens of words benefit the most. Frequent patterns in the context (N-grams) also significantly impact predictions. Additionally, the model's prior knowledge plays a crucial role in influencing predictions, especially for rare tokens. We also observe that language models become more confident with longer contexts, resulting in sharper probability distributions. This overconfidence may contribute to the increasing probabilities of tokens with distant contextual information. We hope that our analysis will help the community better understand long-text language modeling and contribute to the design of more reliable long-context models.