 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain a Multi-Task Diffusion Policy on RLBench-18 in One Day with One GPU
May 14, 2025We present a method for training multi-task vision-language robotic diffusion policies that reduces training time and memory usage by an order of magnitude. This improvement arises from a previously underexplored distinction between action diffusion and the image diffusion techniques that inspired it: image generation targets are high-dimensional, while robot actions lie in a much lower-dimensional space. Meanwhile, the vision-language conditions for action generation remain high-dimensional. Our approach, Mini-Diffuser, exploits this asymmetry by introducing Level-2 minibatching, which pairs multiple noised action samples with each vision-language condition, instead of the conventional one-to-one sampling strategy. To support this batching scheme, we introduce architectural adaptations to the diffusion transformer that prevent information leakage across samples while maintaining full conditioning access. In RLBench simulations, Mini-Diffuser achieves 95\% of the performance of state-of-the-art multi-task diffusion policies, while using only 5\% of the training time and 7\% of the memory. Real-world experiments further validate that Mini-Diffuser preserves the key strengths of diffusion-based policies, including the ability to model multimodal action distributions and produce behavior conditioned on diverse perceptual inputs. Code available at github.com/utomm/mini-diffuse-actor.
M$^3$PC: Test-time Model Predictive Control for Pretrained Masked Trajectory Model
Dec 07, 2024



Recent work in Offline Reinforcement Learning (RL) has shown that a unified Transformer trained under a masked auto-encoding objective can effectively capture the relationships between different modalities (e.g., states, actions, rewards) within given trajectory datasets. However, this information has not been fully exploited during the inference phase, where the agent needs to generate an optimal policy instead of just reconstructing masked components from unmasked ones. Given that a pretrained trajectory model can act as both a Policy Model and a World Model with appropriate mask patterns, we propose using Model Predictive Control (MPC) at test time to leverage the model's own predictive capability to guide its action selection. Empirical results on D4RL and RoboMimic show that our inference-phase MPC significantly improves the decision-making performance of a pretrained trajectory model without any additional parameter training. Furthermore, our framework can be adapted to Offline to Online (O2O) RL and Goal Reaching RL, resulting in more substantial performance gains when an additional online interaction budget is provided, and better generalization capabilities when different task targets are specified. Code is available: https://github.com/wkh923/m3pc.
Only One Relation Possible? Modeling the Ambiguity in Event Temporal Relation Extraction
Aug 14, 2024Event Temporal Relation Extraction (ETRE) aims to identify the temporal relationship between two events, which plays an important role in natural language understanding. Most previous works follow a single-label classification style, classifying an event pair into either a specific temporal relation (e.g., \textit{Before}, \textit{After}), or a special label \textit{Vague} when there may be multiple possible temporal relations between the pair. In our work, instead of directly making predictions on \textit{Vague}, we propose a multi-label classification solution for ETRE (METRE) to infer the possibility of each temporal relation independently, where we treat \textit{Vague} as the cases when there is more than one possible relation between two events. We design a speculation mechanism to explore the possible relations hidden behind \textit{Vague}, which enables the latent information to be used efficiently. Experiments on TB-Dense, MATRES and UDS-T show that our method can effectively utilize the \textit{Vague} instances to improve the recognition for specific temporal relations and outperforms most state-of-the-art methods.
ELLA: Empowering LLMs for Interpretable, Accurate and Informative Legal Advice
Aug 13, 2024
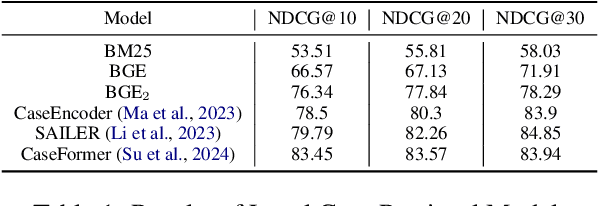
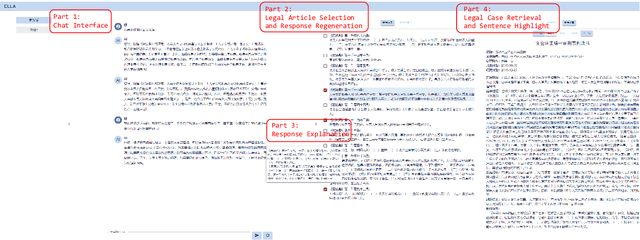

Despite remarkable performance in legal consultation exhibited by legal Large Language Models(LLMs) combined with legal article retrieval components, there are still cases when the advice given is incorrect or baseless. To alleviate these problems, we propose {\bf ELLA}, a tool for {\bf E}mpowering {\bf L}LMs for interpretable, accurate, and informative {\bf L}egal {\bf A}dvice. ELLA visually presents the correlation between legal articles and LLM's response by calculating their similarities, providing users with an intuitive legal basis for the responses. Besides, based on the users' queries, ELLA retrieves relevant legal articles and displays them to users. Users can interactively select legal articles for LLM to generate more accurate responses. ELLA also retrieves relevant legal cases for user reference. Our user study shows that presenting the legal basis for the response helps users understand better. The accuracy of LLM's responses also improves when users intervene in selecting legal articles for LLM. Providing relevant legal cases also aids individuals in obtaining comprehensive information.
Secondary Structure-Guided Novel Protein Sequence Generation with Latent Graph Diffusion
Jul 10, 2024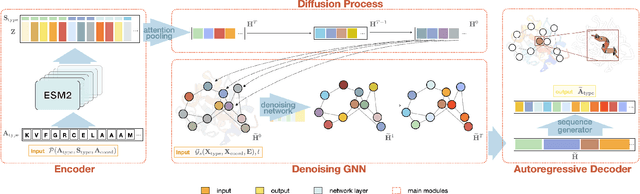
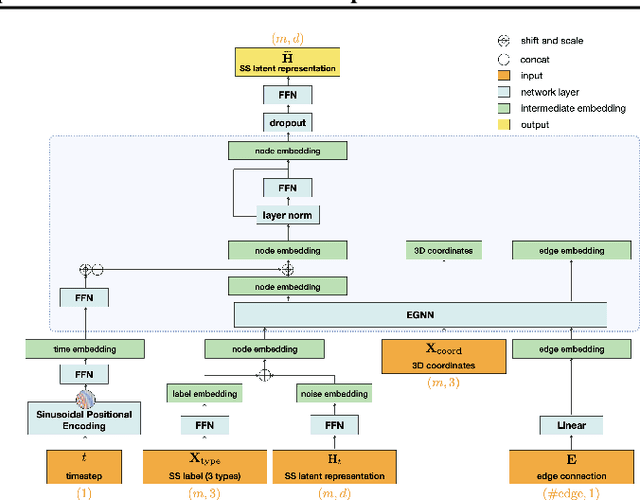

The advent of deep learning has introduced efficient approaches for de novo protein sequence design, significantly improving success rates and reducing development costs compared to computational or experimental methods. However, existing methods face challenges in generating proteins with diverse lengths and shapes while maintaining key structural features. To address these challenges, we introduce CPDiffusion-SS, a latent graph diffusion model that generates protein sequences based on coarse-grained secondary structural information. CPDiffusion-SS offers greater flexibility in producing a variety of novel amino acid sequences while preserving overall structural constraints, thus enhancing the reliability and diversity of generated proteins. Experimental analyses demonstrate the significant superiority of the proposed method in producing diverse and novel sequences, with CPDiffusion-SS surpassing popular baseline methods on open benchmarks across various quantitative measurements. Furthermore, we provide a series of case studies to highlight the biological significance of the generation performance by the proposed method. The source code is publicly available at https://github.com/riacd/CPDiffusion-SS
What Kinds of Tokens Benefit from Distant Text? An Analysis on Long Context Language Modeling
Jun 17, 2024As the context length that large language models can handle continues to increase, these models demonstrate an enhanced ability to utilize distant information for tasks such as language modeling. This capability contrasts with human reading and writing habits, where it is uncommon to remember and use particularly distant information, except in cases of foreshadowing. In this paper, we aim to explore which kinds of words benefit more from long contexts in language models. By analyzing the changes in token probabilities with increasing context length, we find that content words (e.g., nouns, adjectives) and the initial tokens of words benefit the most. Frequent patterns in the context (N-grams) also significantly impact predictions. Additionally, the model's prior knowledge plays a crucial role in influencing predictions, especially for rare tokens. We also observe that language models become more confident with longer contexts, resulting in sharper probability distributions. This overconfidence may contribute to the increasing probabilities of tokens with distant contextual information. We hope that our analysis will help the community better understand long-text language modeling and contribute to the design of more reliable long-context models.
Can Perplexity Reflect Large Language Model's Ability in Long Text Understanding?
May 09, 2024Recent studies have shown that Large Language Models (LLMs) have the potential to process extremely long text. Many works only evaluate LLMs' long-text processing ability on the language modeling task, with perplexity (PPL) as the evaluation metric. However, in our study, we find that there is no correlation between PPL and LLMs' long-text understanding ability. Besides, PPL may only reflect the model's ability to model local information instead of catching long-range dependency. Therefore, only using PPL to prove the model could process long text is inappropriate. The local focus feature of PPL could also explain some existing phenomena, such as the great extrapolation ability of the position method ALiBi. When evaluating a model's ability in long text, we might pay more attention to PPL's limitation and avoid overly relying on it.
DexDribbler: Learning Dexterous Soccer Manipulation via Dynamic Supervision
Mar 21, 2024
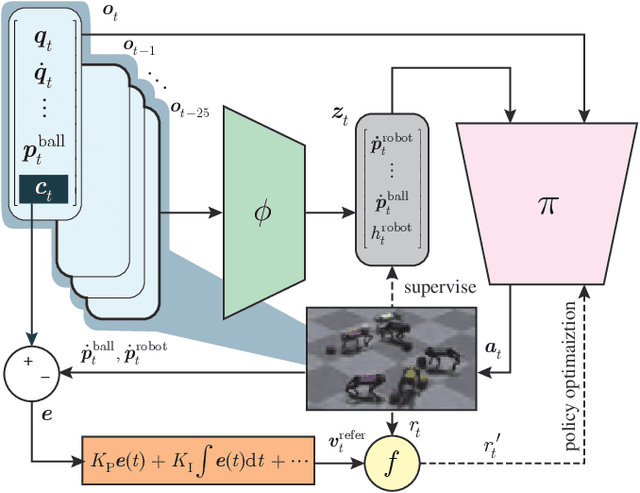
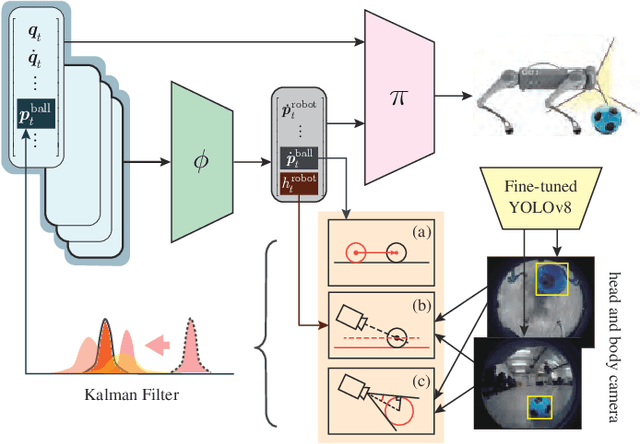
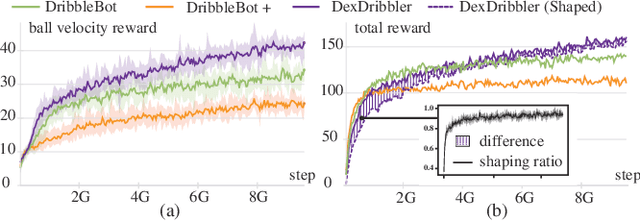
Learning dexterous locomotion policy for legged robots is becoming increasingly popular due to its ability to handle diverse terrains and resemble intelligent behaviors. However, joint manipulation of moving objects and locomotion with legs, such as playing soccer, receive scant attention in the learning community, although it is natural for humans and smart animals. A key challenge to solve this multitask problem is to infer the objectives of locomotion from the states and targets of the manipulated objects. The implicit relation between the object states and robot locomotion can be hard to capture directly from the training experience. We propose adding a feedback control block to compute the necessary body-level movement accurately and using the outputs as dynamic joint-level locomotion supervision explicitly. We further utilize an improved ball dynamic model, an extended context-aided estimator, and a comprehensive ball observer to facilitate transferring policy learned in simulation to the real world. We observe that our learning scheme can not only make the policy network converge faster but also enable soccer robots to perform sophisticated maneuvers like sharp cuts and turns on flat surfaces, a capability that was lacking in previous methods. Video and code are available at https://github.com/SysCV/soccer-player
More than Classification: A Unified Framework for Event Temporal Relation Extraction
May 28, 2023



Event temporal relation extraction~(ETRE) is usually formulated as a multi-label classification task, where each type of relation is simply treated as a one-hot label. This formulation ignores the meaning of relations and wipes out their intrinsic dependency. After examining the relation definitions in various ETRE tasks, we observe that all relations can be interpreted using the start and end time points of events. For example, relation \textit{Includes} could be interpreted as event 1 starting no later than event 2 and ending no earlier than event 2. In this paper, we propose a unified event temporal relation extraction framework, which transforms temporal relations into logical expressions of time points and completes the ETRE by predicting the relations between certain time point pairs. Experiments on TB-Dense and MATRES show significant improvements over a strong baseline and outperform the state-of-the-art model by 0.3\% on both datasets. By representing all relations in a unified framework, we can leverage the relations with sufficient data to assist the learning of other relations, thus achieving stable improvement in low-data scenarios. When the relation definitions are changed, our method can quickly adapt to the new ones by simply modifying the logic expressions that map time points to new event relations. The code is released at \url{https://github.com/AndrewZhe/A-Unified-Framework-for-ETRE}.
Making Parameterization and Constrains of Object Landmark Globally Consistent via SPD(3) Manifold and Improved Cost Functions
Apr 22, 2022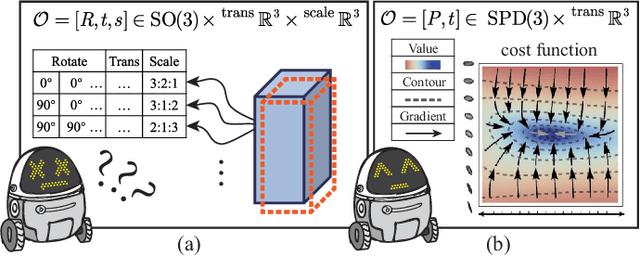

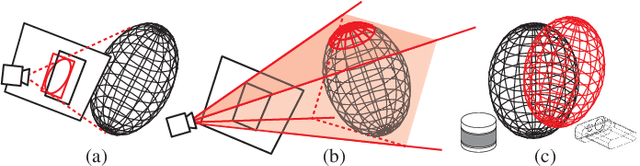
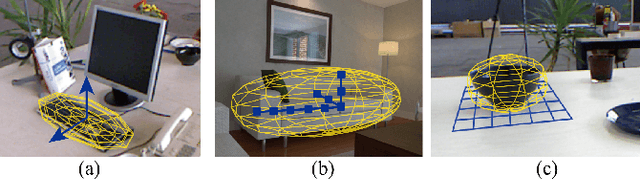
Object-level SLAM introduces semantic meaningful and compact object landmarks that help both indoor robot applications and outdoor autonomous driving tasks. However, the back end of object-level SLAM suffers from singularity problems because existing methods parameterize object landmark separately by their scales and poses. Under that parameterization method, the same abstract object can be represented by rotating the object coordinate frame by 90 deg and swapping its length with width value, making the pose of the same object landmark not globally consistent. To avoid the singularity problem, we first introduce the symmetric positive-definite (SPD) matrix manifold as an improved object-level landmark representation and further improve the cost functions in the back end to make them compatible with the representation. Our method demonstrates a faster convergence rate and more robustness in simulation experiments. Experiments on real datasets also reveal that using the same front-end data, our strategy improves the mapping accuracy by 22% on average.