 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain a Multi-Task Diffusion Policy on RLBench-18 in One Day with One GPU
May 14, 2025We present a method for training multi-task vision-language robotic diffusion policies that reduces training time and memory usage by an order of magnitude. This improvement arises from a previously underexplored distinction between action diffusion and the image diffusion techniques that inspired it: image generation targets are high-dimensional, while robot actions lie in a much lower-dimensional space. Meanwhile, the vision-language conditions for action generation remain high-dimensional. Our approach, Mini-Diffuser, exploits this asymmetry by introducing Level-2 minibatching, which pairs multiple noised action samples with each vision-language condition, instead of the conventional one-to-one sampling strategy. To support this batching scheme, we introduce architectural adaptations to the diffusion transformer that prevent information leakage across samples while maintaining full conditioning access. In RLBench simulations, Mini-Diffuser achieves 95\% of the performance of state-of-the-art multi-task diffusion policies, while using only 5\% of the training time and 7\% of the memory. Real-world experiments further validate that Mini-Diffuser preserves the key strengths of diffusion-based policies, including the ability to model multimodal action distributions and produce behavior conditioned on diverse perceptual inputs. Code available at github.com/utomm/mini-diffuse-actor.
M$^3$PC: Test-time Model Predictive Control for Pretrained Masked Trajectory Model
Dec 07, 2024



Recent work in Offline Reinforcement Learning (RL) has shown that a unified Transformer trained under a masked auto-encoding objective can effectively capture the relationships between different modalities (e.g., states, actions, rewards) within given trajectory datasets. However, this information has not been fully exploited during the inference phase, where the agent needs to generate an optimal policy instead of just reconstructing masked components from unmasked ones. Given that a pretrained trajectory model can act as both a Policy Model and a World Model with appropriate mask patterns, we propose using Model Predictive Control (MPC) at test time to leverage the model's own predictive capability to guide its action selection. Empirical results on D4RL and RoboMimic show that our inference-phase MPC significantly improves the decision-making performance of a pretrained trajectory model without any additional parameter training. Furthermore, our framework can be adapted to Offline to Online (O2O) RL and Goal Reaching RL, resulting in more substantial performance gains when an additional online interaction budget is provided, and better generalization capabilities when different task targets are specified. Code is available: https://github.com/wkh923/m3pc.
DexDribbler: Learning Dexterous Soccer Manipulation via Dynamic Supervision
Mar 21, 2024
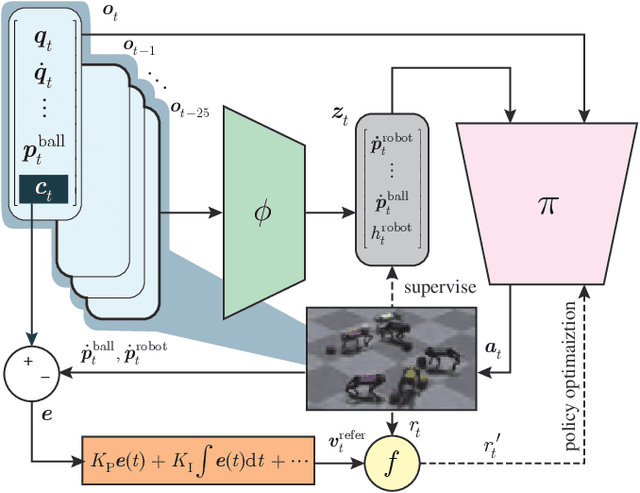
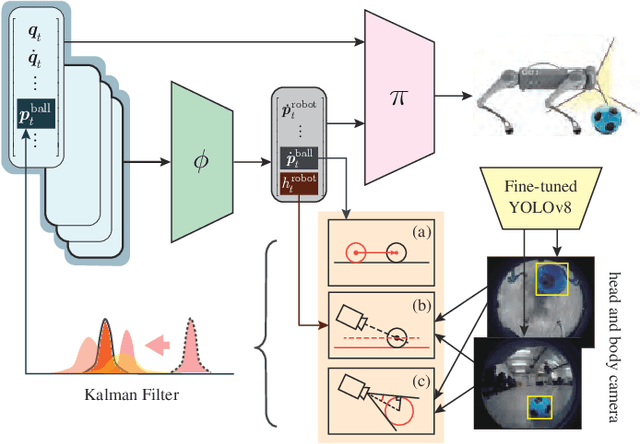
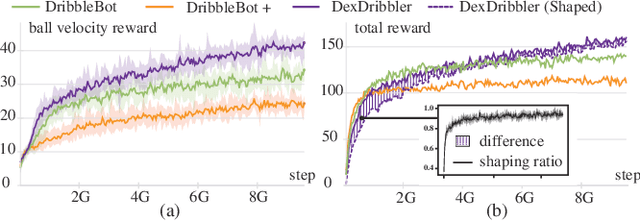
Learning dexterous locomotion policy for legged robots is becoming increasingly popular due to its ability to handle diverse terrains and resemble intelligent behaviors. However, joint manipulation of moving objects and locomotion with legs, such as playing soccer, receive scant attention in the learning community, although it is natural for humans and smart animals. A key challenge to solve this multitask problem is to infer the objectives of locomotion from the states and targets of the manipulated objects. The implicit relation between the object states and robot locomotion can be hard to capture directly from the training experience. We propose adding a feedback control block to compute the necessary body-level movement accurately and using the outputs as dynamic joint-level locomotion supervision explicitly. We further utilize an improved ball dynamic model, an extended context-aided estimator, and a comprehensive ball observer to facilitate transferring policy learned in simulation to the real world. We observe that our learning scheme can not only make the policy network converge faster but also enable soccer robots to perform sophisticated maneuvers like sharp cuts and turns on flat surfaces, a capability that was lacking in previous methods. Video and code are available at https://github.com/SysCV/soccer-player