 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssistron: Bayesian Shared Autonomy with Off-the-shelf Vision-Language-Action Models
Jun 22, 2026We propose Assistron, a shared autonomy model that leverages Vision-Language-Action (VLA) models to assist the user in daily activities. Our approach is grounded in two core principles: (1)~minimizing human cognitive and physical effort by leveraging VLA-driven autonomy for macro-movements, and (2)~prioritizing human intervention specifically at critical failure points. Driven by the user's verbal language commands, Assistron utilizes the VLA to autonomously execute macro-reaching trajectories, saving users' effort. In contact-rich interactions where VLAs tend to fail, Assistron employs a phase-aware interaction detection mechanism and solicits the user to intervene, in turn adjusting the VLA's action generation via flow matching guidance. Critically, our formulation eliminates the need for VLA fine-tuning, protecting its broad behavioral priors from catastrophic forgetting and ensuring the model does not become a narrow specialist. We validate our approach on a comprehensive multi-task scene recovery benchmark encompassing diverse daily manipulation skills. Empirical results demonstrate that Assistron significantly improves task success rates over pure autonomous baselines while significantly reducing human cognitive and physical workload compared to traditional teleoperation, offering a scalable, smooth, and effortless paradigm for assistive manipulation. The code is available in https://github.com/mousecpn/Assistron.git.
ELVIS: Ensemble-Calibrated Latent Imagination for Long-Horizon Visual MPC
May 06, 2026A central challenge of visual control with model-based reinforcement learning (RL) is reliable long-horizon planning: long rollouts with learned latent dynamics exhibit branching futures and multi-modal action-value distributions. In addition, compounding model errors amplified by visual occlusions make deep imagination brittle. We present ELVIS, a latent model predictive controller (MPC) designed to make long-horizon planning practical. ELVIS plans in a Dreamer-style recurrent state space model (RSSM) and replaces standard unimodal model predictive path integral (MPPI) with a Gaussian-mixture MPPI that maintains multiple coherent hypotheses over long horizons, avoiding mode averaging under branching rollouts. In parallel, ELVIS stabilizes deep imagination with a shared uncertainty-aware lambda-return: an ensemble of latent critics defines an upper-confidence-bound (UCB) score that gates a time-varying lambda, adaptively trading off bootstrapping versus look-ahead to limit compounding error during planning. The same return is used both to train an actor-critic prior from imagined rollouts and to score candidate trajectories inside GMM-MPPI, aligning RL objectives with the planner's long-horizon optimization. On fourteen DeepMind Control Suite visual tasks, ELVIS establishes state-of-the-art performance compared with TD-MPC2 and DreamerV3. Finally, ELVIS transfers zero-shot to a real-world sand-spraying task with severe occlusions, improving surface-quality metrics and demonstrating robustness beyond simulation.
See&Trek: Training-Free Spatial Prompting for Multimodal Large Language Model
Sep 19, 2025We introduce SEE&TREK, the first training-free prompting framework tailored to enhance the spatial understanding of Multimodal Large Language Models (MLLMS) under vision-only constraints. While prior efforts have incorporated modalities like depth or point clouds to improve spatial reasoning, purely visualspatial understanding remains underexplored. SEE&TREK addresses this gap by focusing on two core principles: increasing visual diversity and motion reconstruction. For visual diversity, we conduct Maximum Semantic Richness Sampling, which employs an off-the-shell perception model to extract semantically rich keyframes that capture scene structure. For motion reconstruction, we simulate visual trajectories and encode relative spatial positions into keyframes to preserve both spatial relations and temporal coherence. Our method is training&GPU-free, requiring only a single forward pass, and can be seamlessly integrated into existing MLLM'S. Extensive experiments on the VSI-B ENCH and STI-B ENCH show that S EE &T REK consistently boosts various MLLM S performance across diverse spatial reasoning tasks with the most +3.5% improvement, offering a promising path toward stronger spatial intelligence.
Train a Multi-Task Diffusion Policy on RLBench-18 in One Day with One GPU
May 14, 2025We present a method for training multi-task vision-language robotic diffusion policies that reduces training time and memory usage by an order of magnitude. This improvement arises from a previously underexplored distinction between action diffusion and the image diffusion techniques that inspired it: image generation targets are high-dimensional, while robot actions lie in a much lower-dimensional space. Meanwhile, the vision-language conditions for action generation remain high-dimensional. Our approach, Mini-Diffuser, exploits this asymmetry by introducing Level-2 minibatching, which pairs multiple noised action samples with each vision-language condition, instead of the conventional one-to-one sampling strategy. To support this batching scheme, we introduce architectural adaptations to the diffusion transformer that prevent information leakage across samples while maintaining full conditioning access. In RLBench simulations, Mini-Diffuser achieves 95\% of the performance of state-of-the-art multi-task diffusion policies, while using only 5\% of the training time and 7\% of the memory. Real-world experiments further validate that Mini-Diffuser preserves the key strengths of diffusion-based policies, including the ability to model multimodal action distributions and produce behavior conditioned on diverse perceptual inputs. Code available at github.com/utomm/mini-diffuse-actor.
Robot Trajectron: Trajectory Prediction-based Shared Control for Robot Manipulation
Feb 04, 2024



We address the problem of (a) predicting the trajectory of an arm reaching motion, based on a few seconds of the motion's onset, and (b) leveraging this predictor to facilitate shared-control manipulation tasks, easing the cognitive load of the operator by assisting them in their anticipated direction of motion. Our novel intent estimator, dubbed the \emph{Robot Trajectron} (RT), produces a probabilistic representation of the robot's anticipated trajectory based on its recent position, velocity and acceleration history. Taking arm dynamics into account allows RT to capture the operator's intent better than other SOTA models that only use the arm's position, making it particularly well-suited to assist in tasks where the operator's intent is susceptible to change. We derive a novel shared-control solution that combines RT's predictive capacity to a representation of the locations of potential reaching targets. Our experiments demonstrate RT's effectiveness in both intent estimation and shared-control tasks. We will make the code and data supporting our experiments publicly available at https://github.com/mousecpn/Robot-Trajectron.git.
Domain Similarity-Perceived Label Assignment for Domain Generalized Underwater Object Detection
Dec 20, 2023The inherent characteristics and light fluctuations of water bodies give rise to the huge difference between different layers and regions in underwater environments. When the test set is collected in a different marine area from the training set, the issue of domain shift emerges, significantly compromising the model's ability to generalize. The Domain Adversarial Learning (DAL) training strategy has been previously utilized to tackle such challenges. However, DAL heavily depends on manually one-hot domain labels, which implies no difference among the samples in the same domain. Such an assumption results in the instability of DAL. This paper introduces the concept of Domain Similarity-Perceived Label Assignment (DSP). The domain label for each image is regarded as its similarity to the specified domains. Through domain-specific data augmentation techniques, we achieved state-of-the-art results on the underwater cross-domain object detection benchmark S-UODAC2020. Furthermore, we validated the effectiveness of our method in the Cityscapes dataset.
A Gated Cross-domain Collaborative Network for Underwater Object Detection
Jun 25, 2023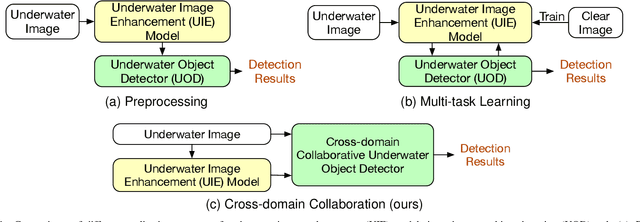
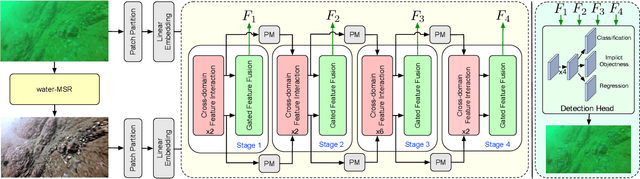
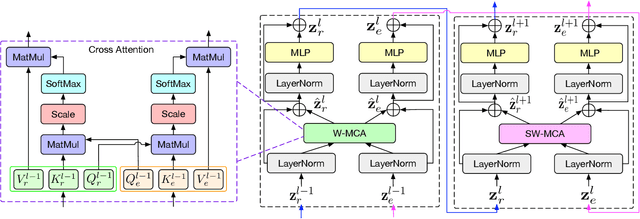

Underwater object detection (UOD) plays a significant role in aquaculture and marine environmental protection. Considering the challenges posed by low contrast and low-light conditions in underwater environments, several underwater image enhancement (UIE) methods have been proposed to improve the quality of underwater images. However, only using the enhanced images does not improve the performance of UOD, since it may unavoidably remove or alter critical patterns and details of underwater objects. In contrast, we believe that exploring the complementary information from the two domains is beneficial for UOD. The raw image preserves the natural characteristics of the scene and texture information of the objects, while the enhanced image improves the visibility of underwater objects. Based on this perspective, we propose a Gated Cross-domain Collaborative Network (GCC-Net) to address the challenges of poor visibility and low contrast in underwater environments, which comprises three dedicated components. Firstly, a real-time UIE method is employed to generate enhanced images, which can improve the visibility of objects in low-contrast areas. Secondly, a cross-domain feature interaction module is introduced to facilitate the interaction and mine complementary information between raw and enhanced image features. Thirdly, to prevent the contamination of unreliable generated results, a gated feature fusion module is proposed to adaptively control the fusion ratio of cross-domain information. Our method presents a new UOD paradigm from the perspective of cross-domain information interaction and fusion. Experimental results demonstrate that the proposed GCC-Net achieves state-of-the-art performance on four underwater datasets.
Edge-guided Representation Learning for Underwater Object Detection
Jun 01, 2023



Underwater object detection (UOD) is crucial for marine economic development, environmental protection, and the planet's sustainable development. The main challenges of this task arise from low-contrast, small objects, and mimicry of aquatic organisms. The key to addressing these challenges is to focus the model on obtaining more discriminative information. We observe that the edges of underwater objects are highly unique and can be distinguished from low-contrast or mimicry environments based on their edges. Motivated by this observation, we propose an Edge-guided Representation Learning Network, termed ERL-Net, that aims to achieve discriminative representation learning and aggregation under the guidance of edge cues. Firstly, we introduce an edge-guided attention module to model the explicit boundary information, which generates more discriminative features. Secondly, a feature aggregation module is proposed to aggregate the multi-scale discriminative features by regrouping them into three levels, effectively aggregating global and local information for locating and recognizing underwater objects. Finally, we propose a wide and asymmetric receptive field block to enable features to have a wider receptive field, allowing the model to focus on more small object information. Comprehensive experiments on three challenging underwater datasets show that our method achieves superior performance on the UOD task.
Contrastive Learning from Spatio-Temporal Mixed Skeleton Sequences for Self-Supervised Skeleton-Based Action Recognition
Jul 07, 2022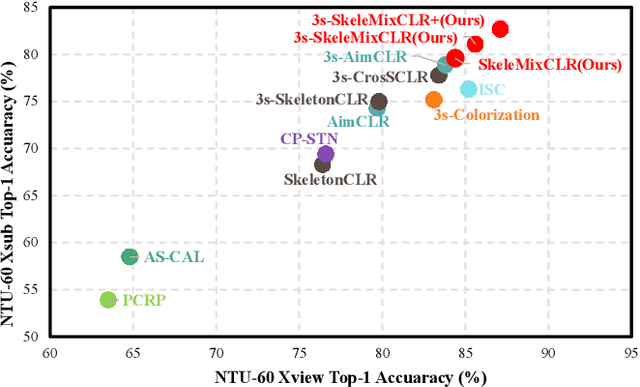
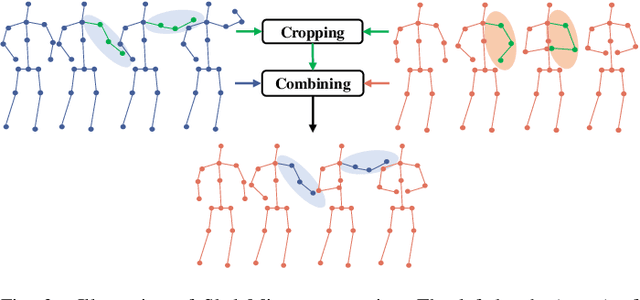
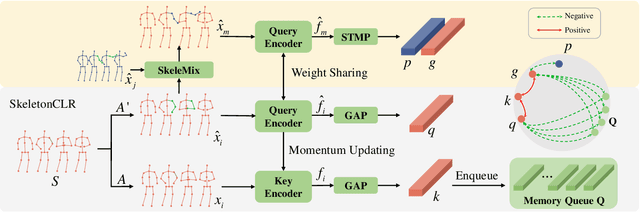
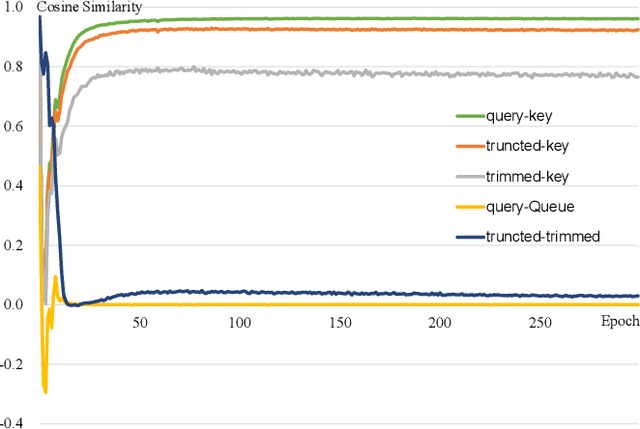
Self-supervised skeleton-based action recognition with contrastive learning has attracted much attention. Recent literature shows that data augmentation and large sets of contrastive pairs are crucial in learning such representations. In this paper, we found that directly extending contrastive pairs based on normal augmentations brings limited returns in terms of performance, because the contribution of contrastive pairs from the normal data augmentation to the loss get smaller as training progresses. Therefore, we delve into hard contrastive pairs for contrastive learning. Motivated by the success of mixing augmentation strategy which improves the performance of many tasks by synthesizing novel samples, we propose SkeleMixCLR: a contrastive learning framework with a spatio-temporal skeleton mixing augmentation (SkeleMix) to complement current contrastive learning approaches by providing hard contrastive samples. First, SkeleMix utilizes the topological information of skeleton data to mix two skeleton sequences by randomly combing the cropped skeleton fragments (the trimmed view) with the remaining skeleton sequences (the truncated view). Second, a spatio-temporal mask pooling is applied to separate these two views at the feature level. Third, we extend contrastive pairs with these two views. SkeleMixCLR leverages the trimmed and truncated views to provide abundant hard contrastive pairs since they involve some context information from each other due to the graph convolution operations, which allows the model to learn better motion representations for action recognition. Extensive experiments on NTU-RGB+D, NTU120-RGB+D, and PKU-MMD datasets show that SkeleMixCLR achieves state-of-the-art performance. Codes are available at https://github.com/czhaneva/SkeleMixCLR.
Boosting R-CNN: Reweighting R-CNN Samples by RPN's Error for Underwater Object Detection
Jun 28, 2022
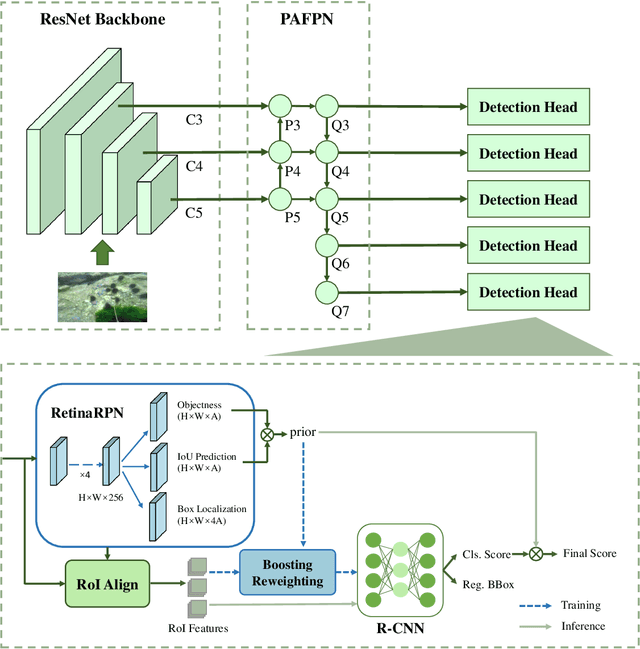
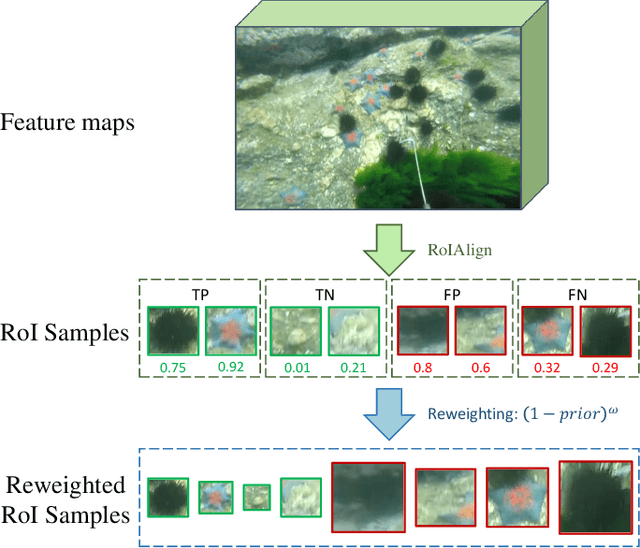
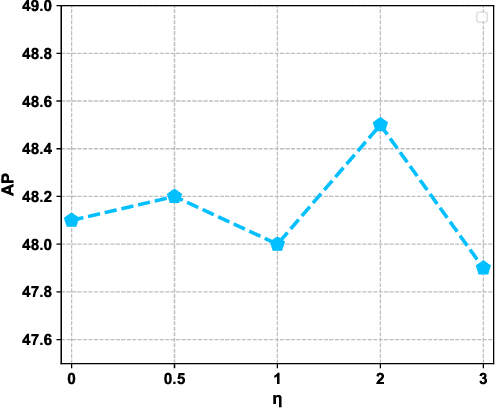
Complicated underwater environments bring new challenges to object detection, such as unbalanced light conditions, low contrast, occlusion, and mimicry of aquatic organisms. Under these circumstances, the objects captured by the underwater camera will become vague, and the generic detectors often fail on these vague objects. This work aims to solve the problem from two perspectives: uncertainty modeling and hard example mining. We propose a two-stage underwater detector named boosting R-CNN, which comprises three key components. First, a new region proposal network named RetinaRPN is proposed, which provides high-quality proposals and considers objectness and IoU prediction for uncertainty to model the object prior probability. Second, the probabilistic inference pipeline is introduced to combine the first-stage prior uncertainty and the second-stage classification score to model the final detection score. Finally, we propose a new hard example mining method named boosting reweighting. Specifically, when the region proposal network miscalculates the object prior probability for a sample, boosting reweighting will increase the classification loss of the sample in the R-CNN head during training, while reducing the loss of easy samples with accurately estimated priors. Thus, a robust detection head in the second stage can be obtained. During the inference stage, the R-CNN has the capability to rectify the error of the first stage to improve the performance. Comprehensive experiments on two underwater datasets and two generic object detection datasets demonstrate the effectiveness and robustness of our method.