 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHetCCL: Enabling Collective Communication For Mixed-Vendor Heterogeneous Clusters
May 29, 2026Training Large Language Models (LLMs) on heterogeneous clusters presents significant challenges for collective communication, as hardware from multiple vendors introduces diverse network and computational characteristics. Existing collective communication frameworks (e.g., NCCL, RCCL) designed for homogeneous environments fail to address mixed-hardware setups, while communication libraries with heterogeneous support (e.g., Gloo, OpenMPI) incur heavy overhead in the data path. This paper presents HetCCL, a framework that enables heterogeneous collective communication by efficient P2P transport across heterogeneous devices (e.g., GPUs), eliminating the host-device memory copy overhead while offloading the control to the CPUs. For combining collectives (e.g., AllReduce, ReduceScatter), HetCCL introduces a border-communicator mechanism that achieves vendor independence by using the intrinsic reduction in the combining collectives in vendor collective communication libraries. With efficient heterogeneous P2P transport and portable reduction mechanism, HetCCL proposes a hierarchical topology abstraction for heterogeneous clusters, dissecting collective communication into cluster-level primitives that guarantee optimal cross-cluster data transfer volume and optimal bandwidth utilization. We implement HetCCL with 4 different vendor support and evaluate it in 4 heterogeneous settings with benchmarks and end-to-end LLM tasks. Our evaluation shows that HetCCL achieves 17-19x higher bandwidth than Gloo in heterogeneous communications, and speeds up end-to-end training by up to 16.9% in the per-step-time.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Device Feature based on Graph Fourier Transformation with Logarithmic Processing For Detection of Replay Speech Attacks
Apr 26, 2024

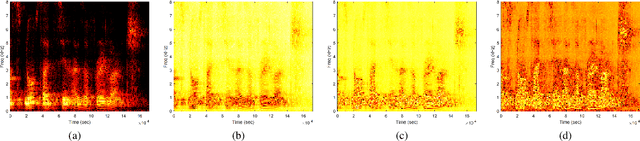
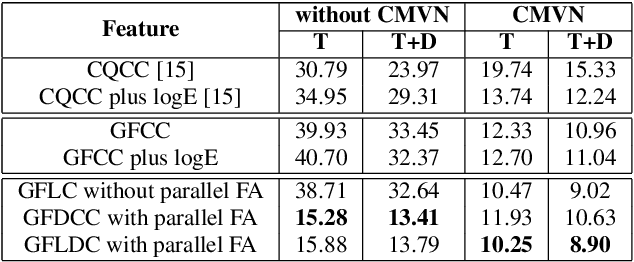
The most common spoofing attacks on automatic speaker verification systems are replay speech attacks. Detection of replay speech heavily relies on replay configuration information. Previous studies have shown that graph Fourier transform-derived features can effectively detect replay speech but ignore device and environmental noise effects. In this work, we propose a new feature, the graph frequency device cepstral coefficient, derived from the graph frequency domain using a device-related linear transformation. We also introduce two novel representations: graph frequency logarithmic coefficient and graph frequency logarithmic device coefficient. We evaluate our methods using traditional Gaussian mixture model and light convolutional neural network systems as classifiers. On the ASVspoof 2017 V2, ASVspoof 2019 physical access, and ASVspoof 2021 physical access datasets, our proposed features outperform known front-ends, demonstrating their effectiveness for replay speech detection.
Domain Similarity-Perceived Label Assignment for Domain Generalized Underwater Object Detection
Dec 20, 2023The inherent characteristics and light fluctuations of water bodies give rise to the huge difference between different layers and regions in underwater environments. When the test set is collected in a different marine area from the training set, the issue of domain shift emerges, significantly compromising the model's ability to generalize. The Domain Adversarial Learning (DAL) training strategy has been previously utilized to tackle such challenges. However, DAL heavily depends on manually one-hot domain labels, which implies no difference among the samples in the same domain. Such an assumption results in the instability of DAL. This paper introduces the concept of Domain Similarity-Perceived Label Assignment (DSP). The domain label for each image is regarded as its similarity to the specified domains. Through domain-specific data augmentation techniques, we achieved state-of-the-art results on the underwater cross-domain object detection benchmark S-UODAC2020. Furthermore, we validated the effectiveness of our method in the Cityscapes dataset.