 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Speaker Embedding Self-Augmentation for Personal Voice Activity Detection with Short Enrollment Speech
Jan 19, 2026Personal Voice Activity Detection (PVAD) is crucial for identifying target speaker segments in the mixture, yet its performance heavily depends on the quality of speaker embeddings. A key practical limitation is the short enrollment speech--such as a wake-up word--which provides limited cues. This paper proposes a novel adaptive speaker embedding self-augmentation strategy that enhances PVAD performance by augmenting the original enrollment embeddings through additive fusion of keyframe embeddings extracted from mixed speech. Furthermore, we introduce a long-term adaptation strategy to iteratively refine embeddings during detection, mitigating speaker temporal variability. Experiments show significant gains in recall, precision, and F1-score under short enrollment conditions, matching full-length enrollment performance after five iterative updates. The source code is available at https://anonymous.4open.science/r/ASE-PVAD-E5D6 .
Multi-modal Speech Enhancement with Limited Electromyography Channels
Jan 11, 2025


Speech enhancement (SE) aims to improve the clarity, intelligibility, and quality of speech signals for various speech enabled applications. However, air-conducted (AC) speech is highly susceptible to ambient noise, particularly in low signal-to-noise ratio (SNR) and non-stationary noise environments. Incorporating multi-modal information has shown promise in enhancing speech in such challenging scenarios. Electromyography (EMG) signals, which capture muscle activity during speech production, offer noise-resistant properties beneficial for SE in adverse conditions. Most previous EMG-based SE methods required 35 EMG channels, limiting their practicality. To address this, we propose a novel method that considers only 8-channel EMG signals with acoustic signals using a modified SEMamba network with added cross-modality modules. Our experiments demonstrate substantial improvements in speech quality and intelligibility over traditional approaches, especially in extremely low SNR settings. Notably, compared to the SE (AC) approach, our method achieves a significant PESQ gain of 0.235 under matched low SNR conditions and 0.527 under mismatched conditions, highlighting its robustness.
Device Feature based on Graph Fourier Transformation with Logarithmic Processing For Detection of Replay Speech Attacks
Apr 26, 2024

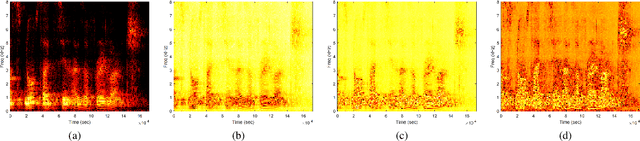
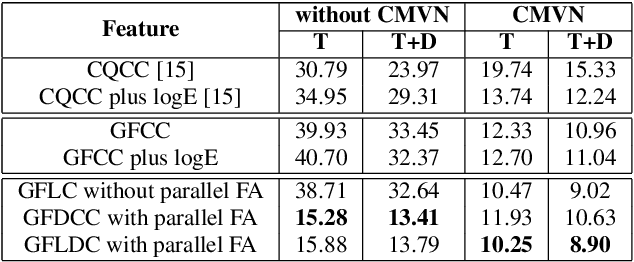
The most common spoofing attacks on automatic speaker verification systems are replay speech attacks. Detection of replay speech heavily relies on replay configuration information. Previous studies have shown that graph Fourier transform-derived features can effectively detect replay speech but ignore device and environmental noise effects. In this work, we propose a new feature, the graph frequency device cepstral coefficient, derived from the graph frequency domain using a device-related linear transformation. We also introduce two novel representations: graph frequency logarithmic coefficient and graph frequency logarithmic device coefficient. We evaluate our methods using traditional Gaussian mixture model and light convolutional neural network systems as classifiers. On the ASVspoof 2017 V2, ASVspoof 2019 physical access, and ASVspoof 2021 physical access datasets, our proposed features outperform known front-ends, demonstrating their effectiveness for replay speech detection.
Graph Fourier Transform based Audio Zero-watermarking
Sep 16, 2021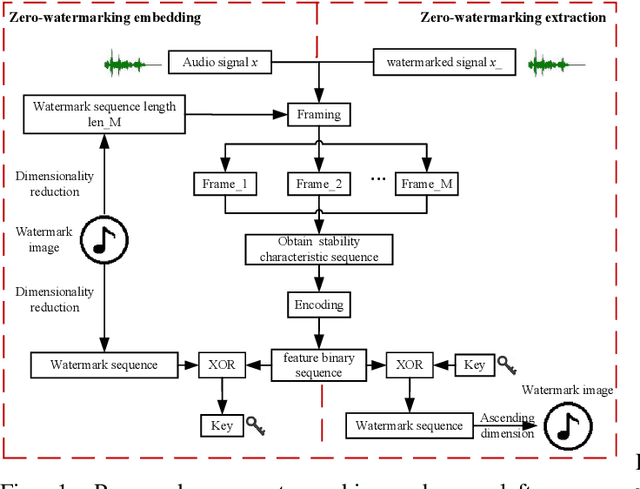



The frequent exchange of multimedia information in the present era projects an increasing demand for copyright protection. In this work, we propose a novel audio zero-watermarking technology based on graph Fourier transform for enhancing the robustness with respect to copyright protection. In this approach, the combined shift operator is used to construct the graph signal, upon which the graph Fourier analysis is performed. The selected maximum absolute graph Fourier coefficients representing the characteristics of the audio segment are then encoded into a feature binary sequence using K-means algorithm. Finally, the resultant feature binary sequence is XOR-ed with the watermark binary sequence to realize the embedding of the zero-watermarking. The experimental studies show that the proposed approach performs more effectively in resisting common or synchronization attacks than the existing state-of-the-art methods.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019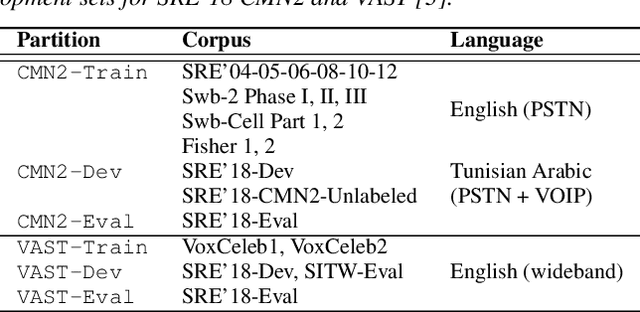
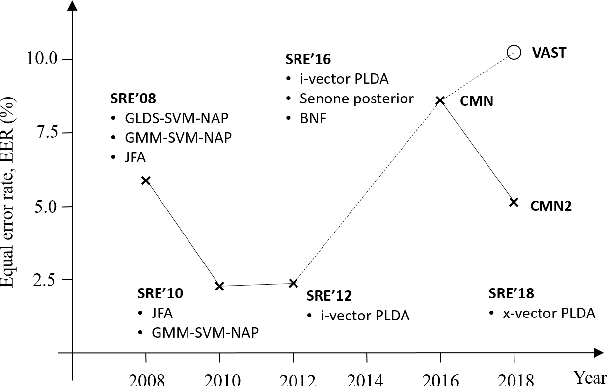
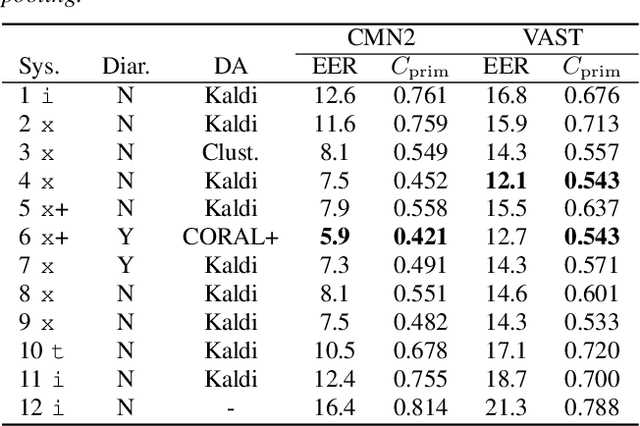
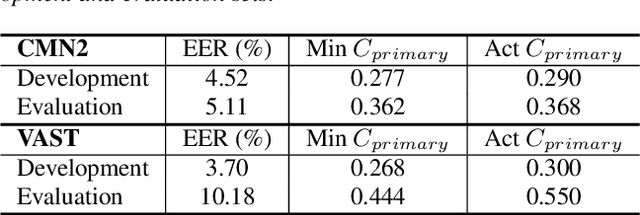
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.
Generative x-vectors for text-independent speaker verification
Sep 17, 2018



Speaker verification (SV) systems using deep neural network embeddings, so-called the x-vector systems, are becoming popular due to its good performance superior to the i-vector systems. The fusion of these systems provides improved performance benefiting both from the discriminatively trained x-vectors and generative i-vectors capturing distinct speaker characteristics. In this paper, we propose a novel method to include the complementary information of i-vector and x-vector, that is called generative x-vector. The generative x-vector utilizes a transformation model learned from the i-vector and x-vector representations of the background data. Canonical correlation analysis is applied to derive this transformation model, which is later used to transform the standard x-vectors of the enrollment and test segments to the corresponding generative x-vectors. The SV experiments performed on the NIST SRE 2010 dataset demonstrate that the system using generative x-vectors provides considerably better performance than the baseline i-vector and x-vector systems. Furthermore, the generative x-vectors outperform the fusion of i-vector and x-vector systems for long-duration utterances, while yielding comparable results for short-duration utterances.