 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASVspoof 2019: spoofing countermeasures for the detection of synthesized, converted and replayed speech
Feb 11, 2021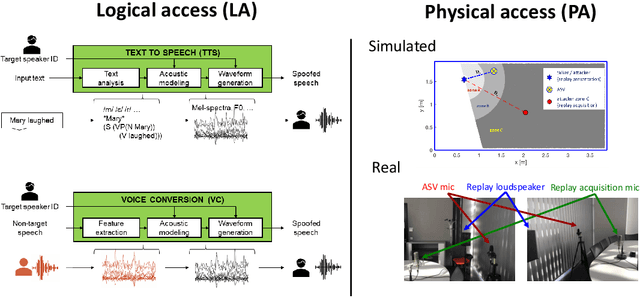
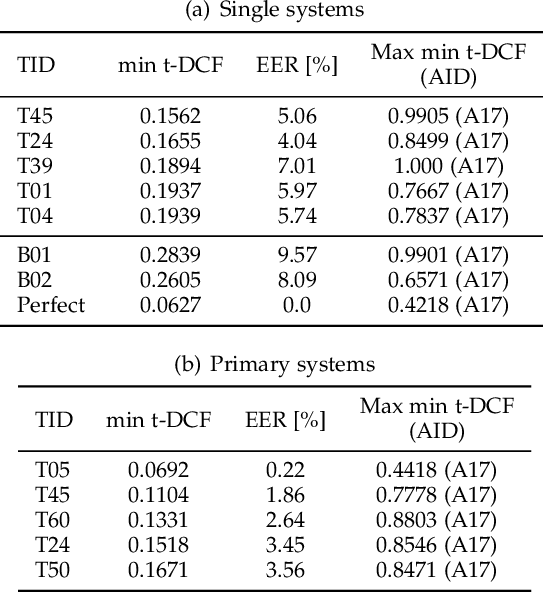
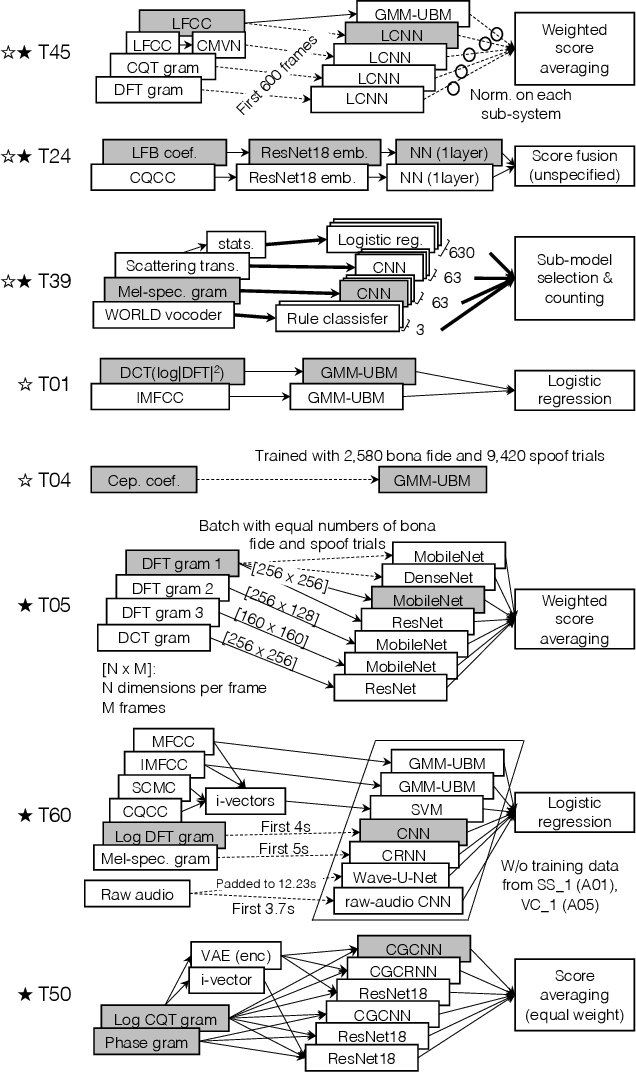
The ASVspoof initiative was conceived to spearhead research in anti-spoofing for automatic speaker verification (ASV). This paper describes the third in a series of bi-annual challenges: ASVspoof 2019. With the challenge database and protocols being described elsewhere, the focus of this paper is on results and the top performing single and ensemble system submissions from 62 teams, all of which out-perform the two baseline systems, often by a substantial margin. Deeper analyses shows that performance is dominated by specific conditions involving either specific spoofing attacks or specific acoustic environments. While fusion is shown to be particularly effective for the logical access scenario involving speech synthesis and voice conversion attacks, participants largely struggled to apply fusion successfully for the physical access scenario involving simulated replay attacks. This is likely the result of a lack of system complementarity, while oracle fusion experiments show clear potential to improve performance. Furthermore, while results for simulated data are promising, experiments with real replay data show a substantial gap, most likely due to the presence of additive noise in the latter. This finding, among others, leads to a number of ideas for further research and directions for future editions of the ASVspoof challenge.
Extrapolating false alarm rates in automatic speaker verification
Aug 08, 2020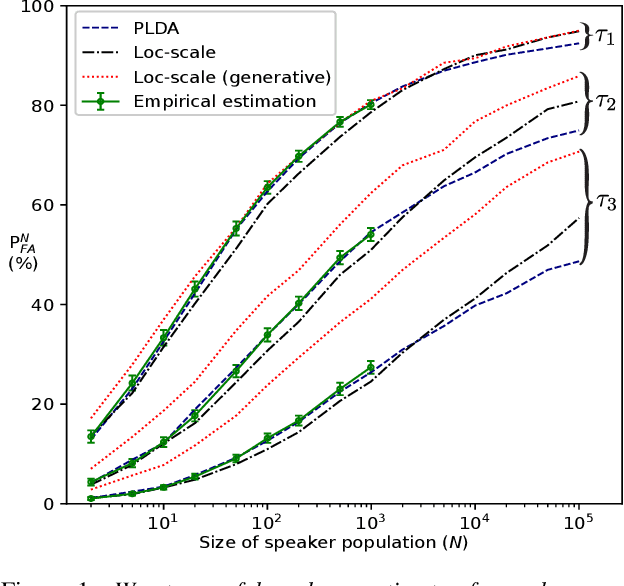

Automatic speaker verification (ASV) vendors and corpus providers would both benefit from tools to reliably extrapolate performance metrics for large speaker populations without collecting new speakers. We address false alarm rate extrapolation under a worst-case model whereby an adversary identifies the closest impostor for a given target speaker from a large population. Our models are generative and allow sampling new speakers. The models are formulated in the ASV detection score space to facilitate analysis of arbitrary ASV systems.
UIAI System for Short-Duration Speaker Verification Challenge 2020
Jul 26, 2020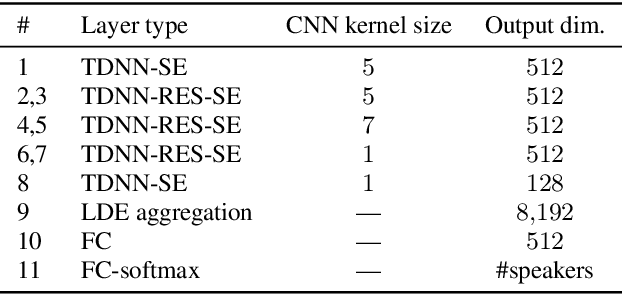
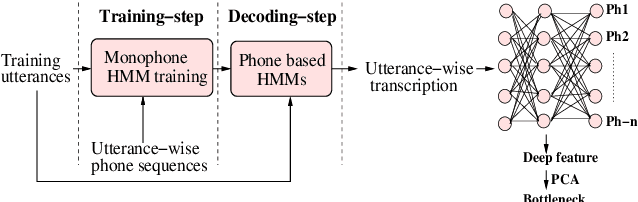
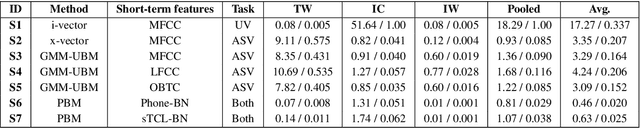
In this work, we present the system description of the UIAI entry for the short-duration speaker verification (SdSV) challenge 2020. Our focus is on Task 1 dedicated to text-dependent speaker verification. We investigate different feature extraction and modeling approaches for automatic speaker verification (ASV) and utterance verification (UV). We have also studied different fusion strategies for combining UV and ASV modules. Our primary submission to the challenge is the fusion of seven subsystems which yields a normalized minimum detection cost function (minDCF) of 0.072 and an equal error rate (EER) of 2.14% on the evaluation set. The single system consisting of a pass-phrase identification based model with phone-discriminative bottleneck features gives a normalized minDCF of 0.118 and achieves 19% relative improvement over the state-of-the-art challenge baseline.
Tandem Assessment of Spoofing Countermeasures and Automatic Speaker Verification: Fundamentals
Jul 12, 2020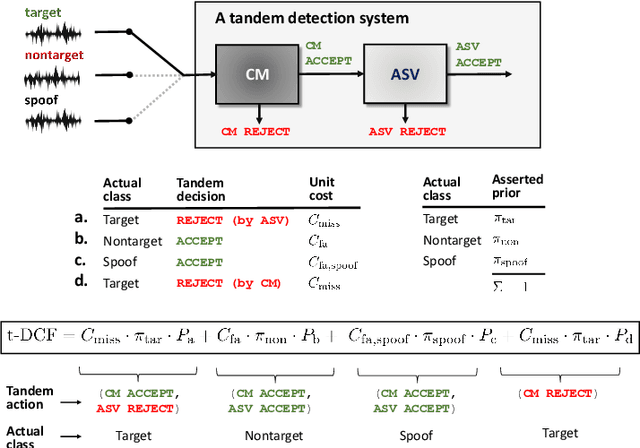
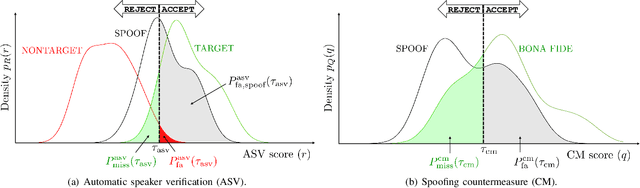
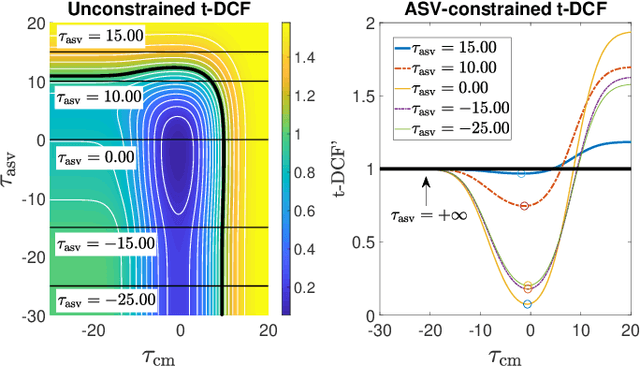
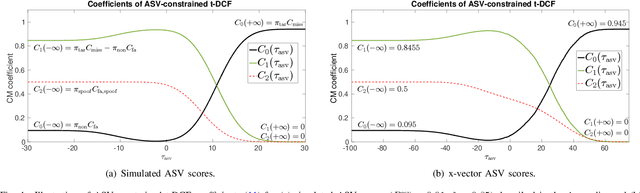
Recent years have seen growing efforts to develop spoofing countermeasures (CMs) to protect automatic speaker verification (ASV) systems from being deceived by manipulated or artificial inputs. The reliability of spoofing CMs is typically gauged using the equal error rate (EER) metric. The primitive EER fails to reflect application requirements and the impact of spoofing and CMs upon ASV and its use as a primary metric in traditional ASV research has long been abandoned in favour of risk-based approaches to assessment. This paper presents several new extensions to the tandem detection cost function (t-DCF), a recent risk-based approach to assess the reliability of spoofing CMs deployed in tandem with an ASV system. Extensions include a simplified version of the t-DCF with fewer parameters, an analysis of a special case for a fixed ASV system, simulations which give original insights into its interpretation and new analyses using the ASVspoof 2019 database. It is hoped that adoption of the t-DCF for the CM assessment will help to foster closer collaboration between the anti-spoofing and ASV research communities.
Neural i-vectors
Apr 18, 2020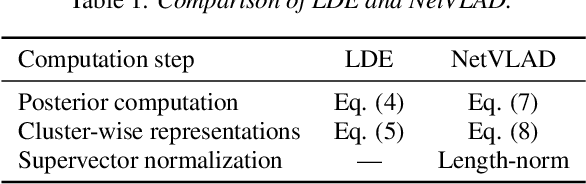
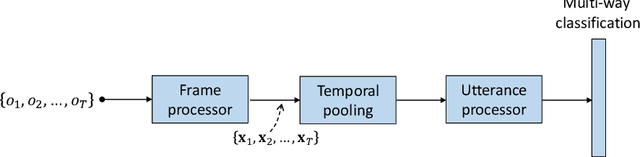
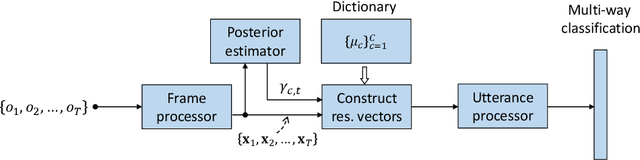
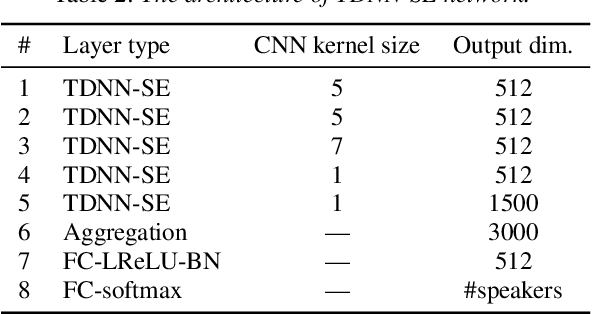
Deep speaker embeddings have been demonstrated to outperform their generative counterparts, i-vectors, in recent speaker verification evaluations. To combine the benefits of high performance and generative interpretation, we investigate the use of deep embedding extractor and i-vector extractor in succession. To bundle the deep embedding extractor with an i-vector extractor, we adopt aggregation layers inspired by the Gaussian mixture model (GMM) to the embedding extractor networks. The inclusion of GMM-like layer allows the discriminatively trained network to be used as a provider of sufficient statistics for the i-vector extractor to extract what we call neural i-vectors. We compare the deep embeddings to the proposed neural i-vectors on the Speakers in the Wild (SITW) and the Speaker Recognition Evaluation (SRE) 2018 and 2019 datasets. On the core-core condition of SITW, our deep embeddings obtain performance comparative to the state-of-the-art. The neural i-vectors obtain about 50% worse performance than the deep embeddings, but on the other hand outperform the previous i-vector approaches reported in the literature by a clear margin.
Voice Biometrics Security: Extrapolating False Alarm Rate via Hierarchical Bayesian Modeling of Speaker Verification Scores
Nov 04, 2019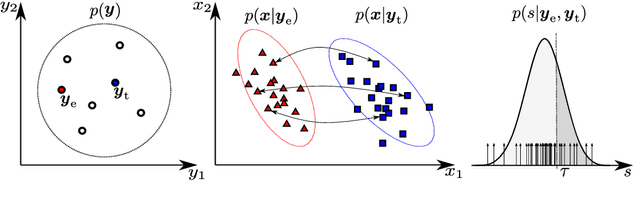
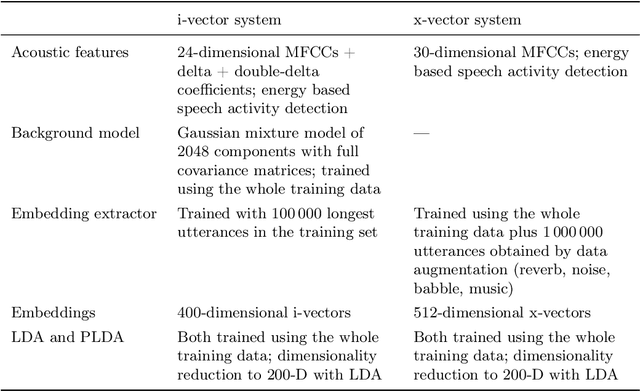
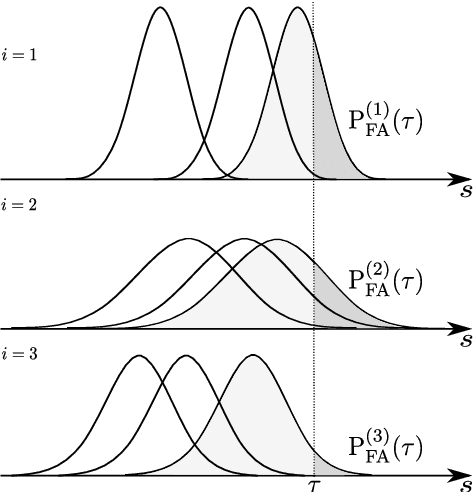

How secure automatic speaker verification (ASV) technology is? More concretely, given a specific target speaker, how likely is it to find another person who gets falsely accepted as that target? This question may be addressed empirically by studying naturally confusable pairs of speakers within a large enough corpus. To this end, one might expect to find at least some speaker pairs that are indistinguishable from each other in terms of ASV. To a certain extent, such aim is mirrored in the standardized ASV evaluation benchmarks. However, the number of speakers in such evaluation benchmarks represents only a small fraction of all possible human voices, making it challenging to extrapolate performance beyond a given corpus. Furthermore, the impostors used in performance evaluation are usually selected randomly. A potentially more meaningful definition of an impostor - at least in the context of security-driven ASV applications - would be closest (most confusable) other speaker to a given target. We put forward a novel performance assessment framework to address both the inadequacy of the random-impostor evaluation model and the size limitation of evaluation corpora by addressing ASV security against closest impostors on arbitrarily large datasets. The framework allows one to make a prediction of the safety of given ASV technology, in its current state, for arbitrarily large speaker database size consisting of virtual (sampled) speakers. As a proof-of-concept, we analyze the performance of two state-of-the-art ASV systems, based on i-vector and x-vector speaker embeddings (as implemented in the popular Kaldi toolkit), on the recent VoxCeleb 1 & 2 corpora. We found that neither the i-vector or x-vector system is immune to increased false alarm rate at increased impostor database size.
Unleashing the Unused Potential of I-Vectors Enabled by GPU Acceleration
Jun 20, 2019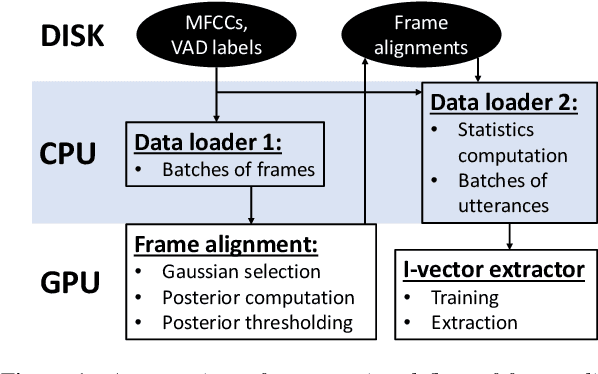
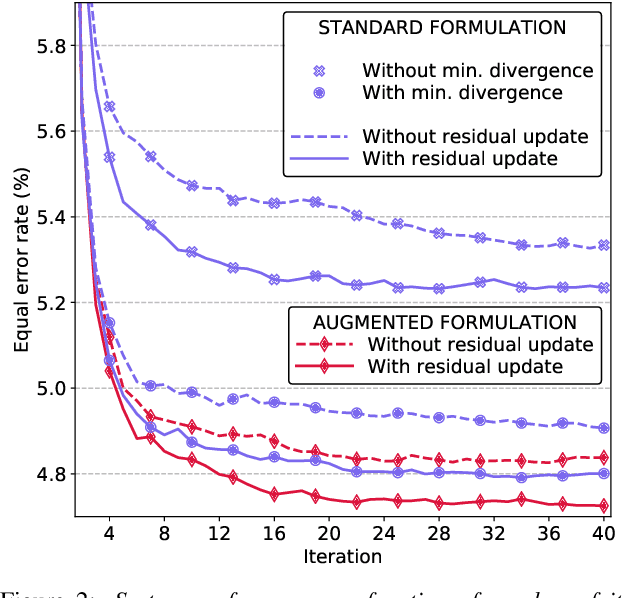
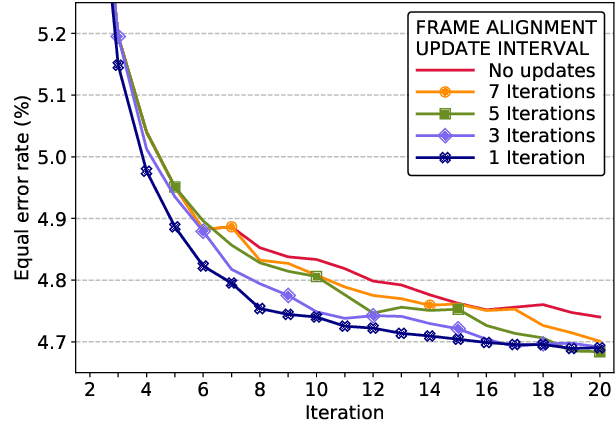
Speaker embeddings are continuous-value vector representations that allow easy comparison between voices of speakers with simple geometric operations. Among others, i-vector and x-vector have emerged as the mainstream methods for speaker embedding. In this paper, we illustrate the use of modern computation platform to harness the benefit of GPU acceleration for i-vector extraction. In particular, we achieve an acceleration of 3000 times in frame posterior computation compared to real time and 25 times in training the i-vector extractor compared to the CPU baseline from Kaldi toolkit. This significant speed-up allows the exploration of ideas that were hitherto impossible. In particular, we show that it is beneficial to update the universal background model (UBM) and re-compute frame alignments while training the i-vector extractor. Additionally, we are able to study different variations of i-vector extractors more rigorously than before. In this process, we reveal some undocumented details of Kaldi's i-vector extractor and show that it outperforms the standard formulation by a margin of 1 to 2% when tested with VoxCeleb speaker verification protocol. All of our findings are asserted by ensemble averaging the results from multiple runs with random start.
Voice Mimicry Attacks Assisted by Automatic Speaker Verification
Jun 03, 2019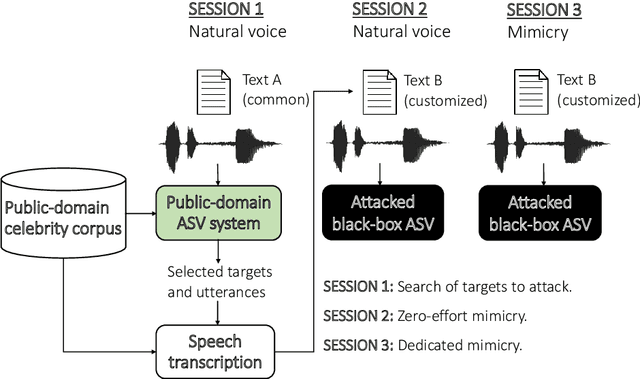

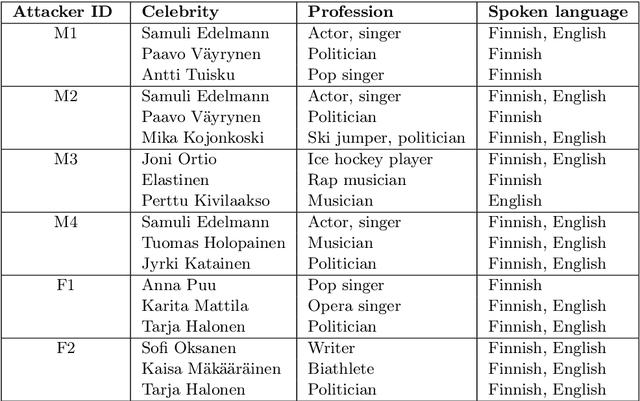
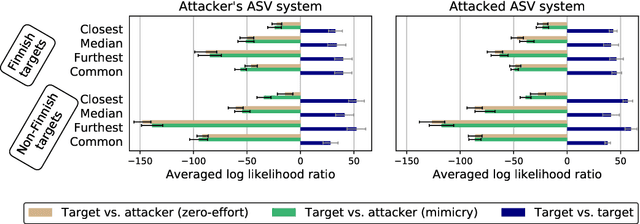
In this work, we simulate a scenario, where a publicly available ASV system is used to enhance mimicry attacks against another closed source ASV system. In specific, ASV technology is used to perform a similarity search between the voices of recruited attackers (6) and potential target speakers (7,365) from VoxCeleb corpora to find the closest targets for each of the attackers. In addition, we consider 'median', 'furthest', and 'common' targets to serve as a reference points. Our goal is to gain insights how well similarity rankings transfer from the attacker's ASV system to the attacked ASV system, whether the attackers are able to improve their attacks by mimicking, and how the properties of the voices of attackers change due to mimicking. We address these questions through ASV experiments, listening tests, and prosodic and formant analyses. For the ASV experiments, we use i-vector technology in the attacker side, and x-vectors in the attacked side. For the listening tests, we recruit listeners through crowdsourcing. The results of the ASV experiments indicate that the speaker similarity scores transfer well from one ASV system to another. Both the ASV experiments and the listening tests reveal that the mimicry attempts do not, in general, help in bringing attacker's scores closer to the target's. A detailed analysis shows that mimicking does not improve attacks, when the natural voices of attackers and targets are similar to each other. The analysis of prosody and formants suggests that the attackers were able to considerably change their speaking rates when mimicking, but the changes in F0 and formants were modest. Overall, the results suggest that untrained impersonators do not pose a high threat towards ASV systems, but the use of ASV systems to attack other ASV systems is a potential threat.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019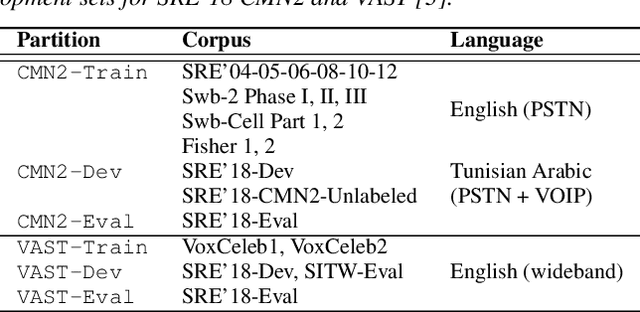
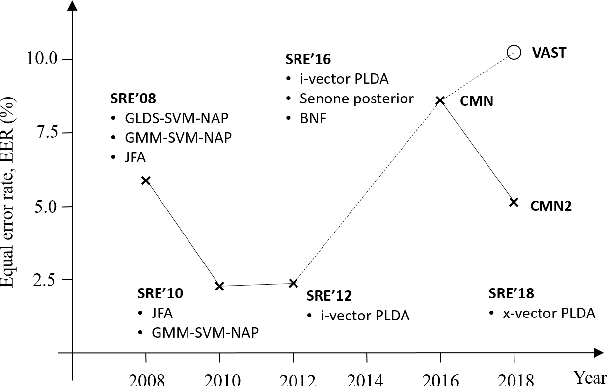
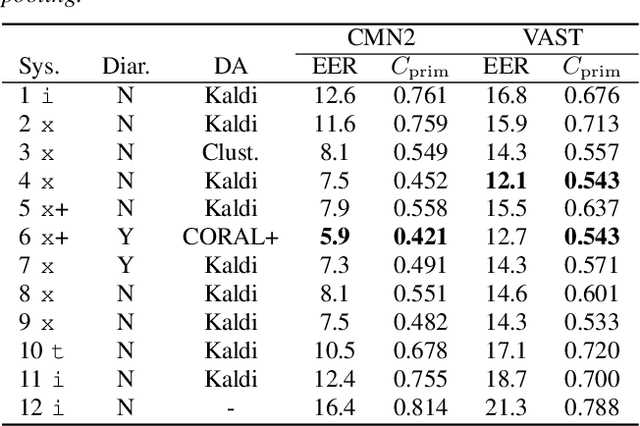
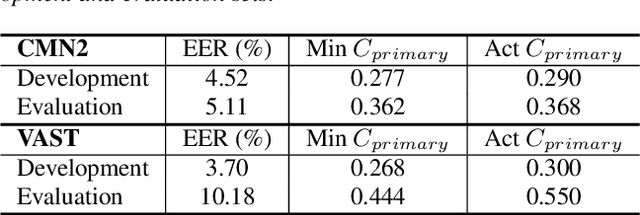
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.
Can We Use Speaker Recognition Technology to Attack Itself? Enhancing Mimicry Attacks Using Automatic Target Speaker Selection
Nov 09, 2018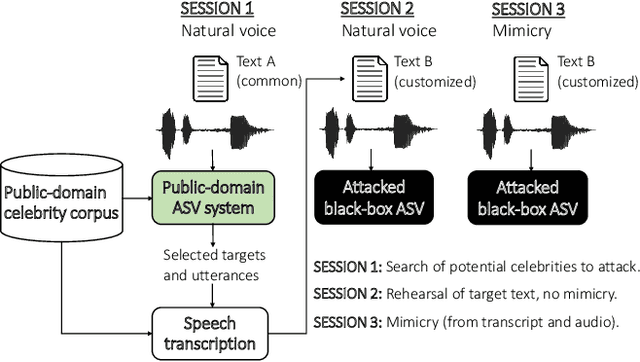

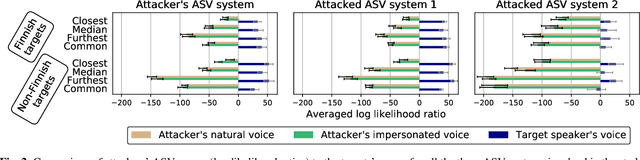

We consider technology-assisted mimicry attacks in the context of automatic speaker verification (ASV). We use ASV itself to select targeted speakers to be attacked by human-based mimicry. We recorded 6 naive mimics for whom we select target celebrities from VoxCeleb1 and VoxCeleb2 corpora (7,365 potential targets) using an i-vector system. The attacker attempts to mimic the selected target, with the utterances subjected to ASV tests using an independently developed x-vector system. Our main finding is negative: even if some of the attacker scores against the target speakers were slightly increased, our mimics did not succeed in spoofing the x-vector system. Interestingly, however, the relative ordering of the selected targets (closest, furthest, median) are consistent between the systems, which suggests some level of transferability between the systems.