 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Generation Using Pass-phrase-dependent Deep Auto-encoders for Text-Dependent Speaker Verification
Feb 03, 2021
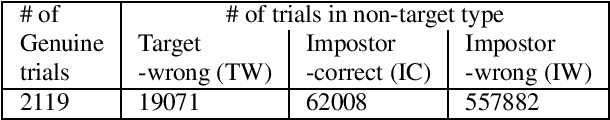

In this paper, we propose a novel method that trains pass-phrase specific deep neural network (PP-DNN) based auto-encoders for creating augmented data for text-dependent speaker verification (TD-SV). Each PP-DNN auto-encoder is trained using the utterances of a particular pass-phrase available in the target enrollment set with two methods: (i) transfer learning and (ii) training from scratch. Next, feature vectors of a given utterance are fed to the PP-DNNs and the output from each PP-DNN at frame-level is considered one new set of generated data. The generated data from each PP-DNN is then used for building a TD-SV system in contrast to the conventional method that considers only the evaluation data available. The proposed approach can be considered as the transformation of data to the pass-phrase specific space using a non-linear transformation learned by each PP-DNN. The method develops several TD-SV systems with the number equal to the number of PP-DNNs separately trained for each pass-phrases for the evaluation. Finally, the scores of the different TD-SV systems are fused for decision making. Experiments are conducted on the RedDots challenge 2016 database for TD-SV using short utterances. Results show that the proposed method improves the performance for both conventional cepstral feature and deep bottleneck feature using both Gaussian mixture model - universal background model (GMM-UBM) and i-vector framework.
UIAI System for Short-Duration Speaker Verification Challenge 2020
Jul 26, 2020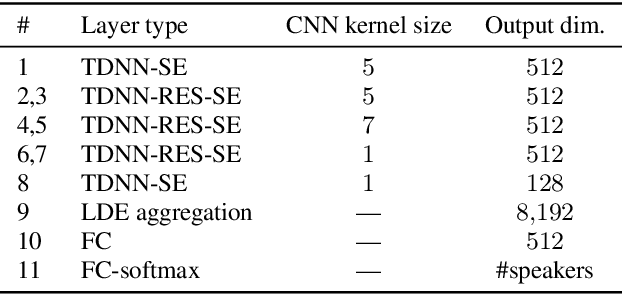
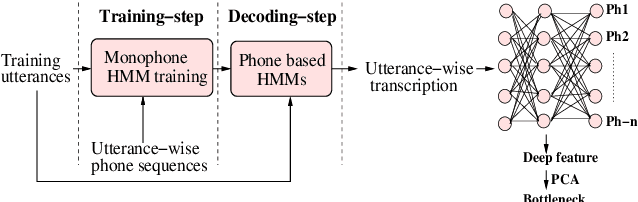
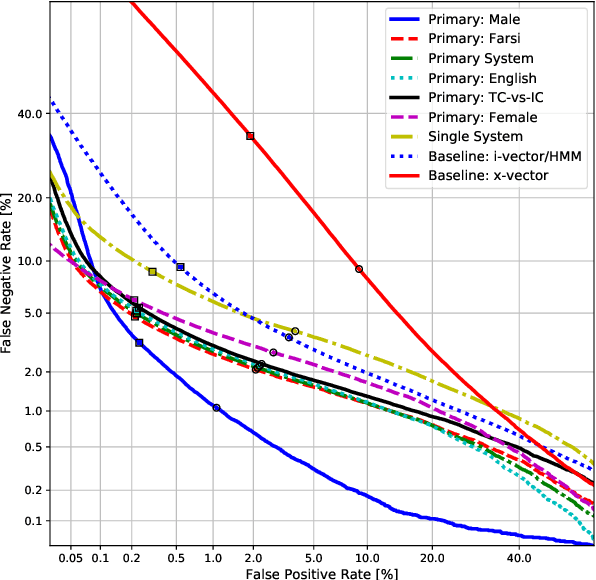
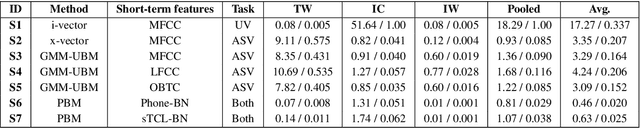
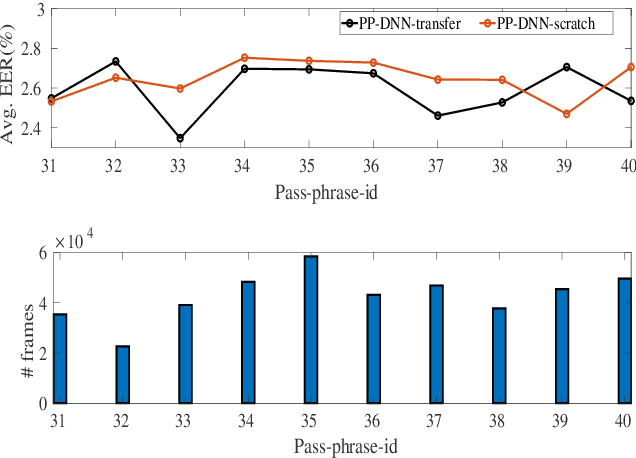
In this work, we present the system description of the UIAI entry for the short-duration speaker verification (SdSV) challenge 2020. Our focus is on Task 1 dedicated to text-dependent speaker verification. We investigate different feature extraction and modeling approaches for automatic speaker verification (ASV) and utterance verification (UV). We have also studied different fusion strategies for combining UV and ASV modules. Our primary submission to the challenge is the fusion of seven subsystems which yields a normalized minimum detection cost function (minDCF) of 0.072 and an equal error rate (EER) of 2.14% on the evaluation set. The single system consisting of a pass-phrase identification based model with phone-discriminative bottleneck features gives a normalized minDCF of 0.118 and achieves 19% relative improvement over the state-of-the-art challenge baseline.
On Bottleneck Features for Text-Dependent Speaker Verification Using X-vectors
May 15, 2020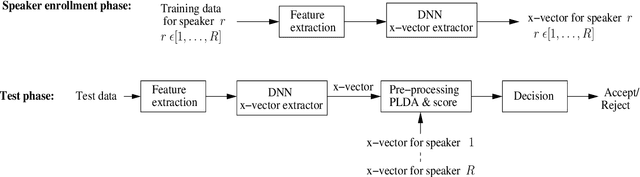

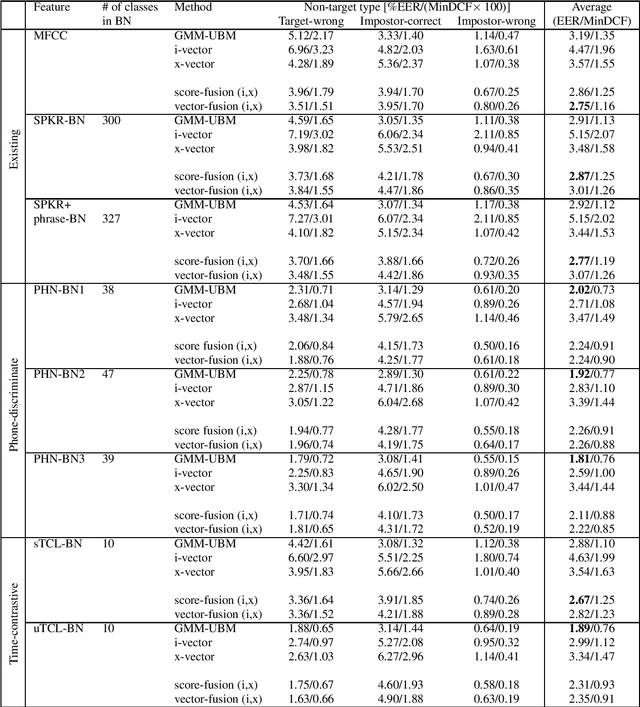
Applying x-vectors for speaker verification has recently attracted great interest, with the focus being on text-independent speaker verification. In this paper, we study x-vectors for text-dependent speaker verification (TD-SV), which remains unexplored. We further investigate the impact of the different bottleneck (BN) features on the performance of x-vectors, including the recently-introduced time-contrastive-learning (TCL) BN features and phone-discriminant BN features. TCL is a weakly supervised learning approach that constructs training data by uniformly partitioning each utterance into a predefined number of segments and then assigning each segment a class label depending on their position in the utterance. We also compare TD-SV performance for different modeling techniques, including the Gaussian mixture models-universal background model (GMM-UBM), i-vector, and x-vector. Experiments are conducted on the RedDots 2016 challenge database. It is found that the type of features has a marginal impact on the performance of x-vectors with the TCL BN feature achieving the lowest equal error rate, while the impact of features is significant for i-vector and GMM-UBM. The fusion of x-vector and i-vector systems gives a large gain in performance. The GMM-UBM technique shows its advantage for TD-SV using short utterances.