 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe distribution of calibrated likelihood functions on the probability-likelihood Aitchison simplex
Sep 03, 2025



While calibration of probabilistic predictions has been widely studied, this paper rather addresses calibration of likelihood functions. This has been discussed, especially in biometrics, in cases with only two exhaustive and mutually exclusive hypotheses (classes) where likelihood functions can be written as log-likelihood-ratios (LLRs). After defining calibration for LLRs and its connection with the concept of weight-of-evidence, we present the idempotence property and its associated constraint on the distribution of the LLRs. Although these results have been known for decades, they have been limited to the binary case. Here, we extend them to cases with more than two hypotheses by using the Aitchison geometry of the simplex, which allows us to recover, in a vector form, the additive form of the Bayes' rule; extending therefore the LLR and the weight-of-evidence to any number of hypotheses. Especially, we extend the definition of calibration, the idempotence, and the constraint on the distribution of likelihood functions to this multiple hypotheses and multiclass counterpart of the LLR: the isometric-log-ratio transformed likelihood function. This work is mainly conceptual, but we still provide one application to machine learning by presenting a non-linear discriminant analysis where the discriminant components form a calibrated likelihood function over the classes, improving therefore the interpretability and the reliability of the method.
Open-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024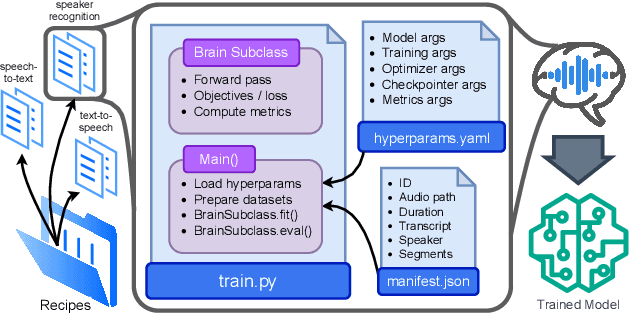

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
t-EER: Parameter-Free Tandem Evaluation of Countermeasures and Biometric Comparators
Sep 21, 2023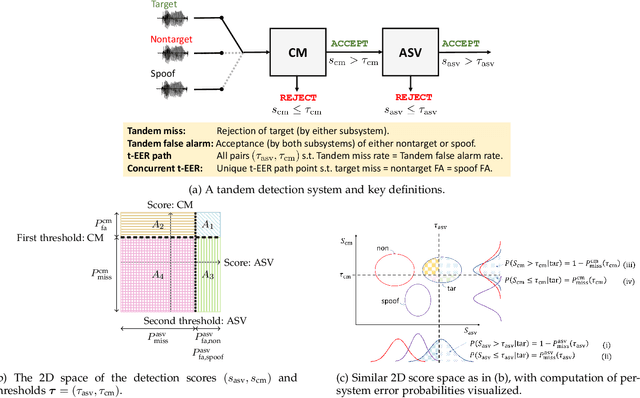

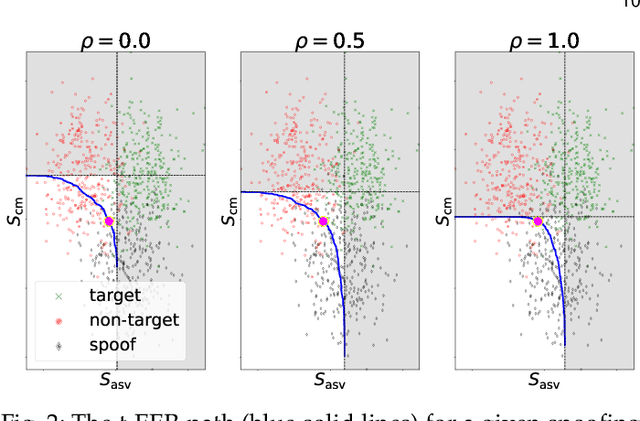

Presentation attack (spoofing) detection (PAD) typically operates alongside biometric verification to improve reliablity in the face of spoofing attacks. Even though the two sub-systems operate in tandem to solve the single task of reliable biometric verification, they address different detection tasks and are hence typically evaluated separately. Evidence shows that this approach is suboptimal. We introduce a new metric for the joint evaluation of PAD solutions operating in situ with biometric verification. In contrast to the tandem detection cost function proposed recently, the new tandem equal error rate (t-EER) is parameter free. The combination of two classifiers nonetheless leads to a \emph{set} of operating points at which false alarm and miss rates are equal and also dependent upon the prevalence of attacks. We therefore introduce the \emph{concurrent} t-EER, a unique operating point which is invariable to the prevalence of attacks. Using both modality (and even application) agnostic simulated scores, as well as real scores for a voice biometrics application, we demonstrate application of the t-EER to a wide range of biometric system evaluations under attack. The proposed approach is a strong candidate metric for the tandem evaluation of PAD systems and biometric comparators.
I4U System Description for NIST SRE'20 CTS Challenge
Nov 02, 2022



This manuscript describes the I4U submission to the 2020 NIST Speaker Recognition Evaluation (SRE'20) Conversational Telephone Speech (CTS) Challenge. The I4U's submission was resulted from active collaboration among researchers across eight research teams - I$^2$R (Singapore), UEF (Finland), VALPT (Italy, Spain), NEC (Japan), THUEE (China), LIA (France), NUS (Singapore), INRIA (France) and TJU (China). The submission was based on the fusion of top performing sub-systems and sub-fusion systems contributed by individual teams. Efforts have been spent on the use of common development and validation sets, submission schedule and milestone, minimizing inconsistency in trial list and score file format across sites.
ASVspoof 2021: Towards Spoofed and Deepfake Speech Detection in the Wild
Oct 05, 2022
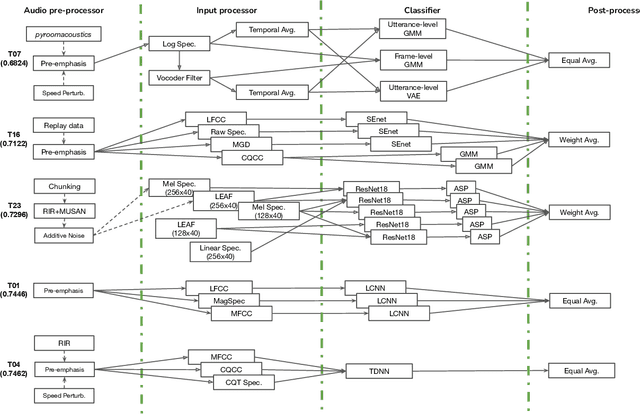
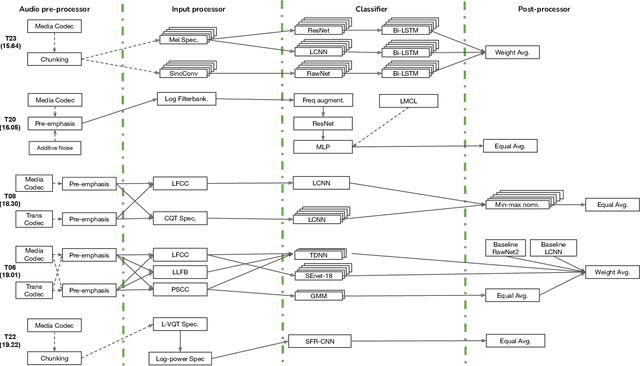
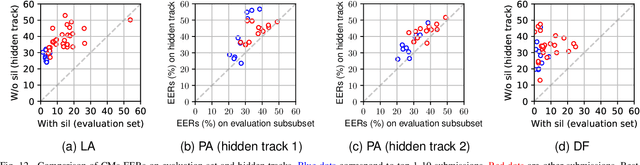
Benchmarking initiatives support the meaningful comparison of competing solutions to prominent problems in speech and language processing. Successive benchmarking evaluations typically reflect a progressive evolution from ideal lab conditions towards to those encountered in the wild. ASVspoof, the spoofing and deepfake detection initiative and challenge series, has followed the same trend. This article provides a summary of the ASVspoof 2021 challenge and the results of 37 participating teams. For the logical access task, results indicate that countermeasures solutions are robust to newly introduced encoding and transmission effects. Results for the physical access task indicate the potential to detect replay attacks in real, as opposed to simulated physical spaces, but a lack of robustness to variations between simulated and real acoustic environments. The DF task, new to the 2021 edition, targets solutions to the detection of manipulated, compressed speech data posted online. While detection solutions offer some resilience to compression effects, they lack generalization across different source datasets. In addition to a summary of the top-performing systems for each task, new analyses of influential data factors and results for hidden data subsets, the article includes a review of post-challenge results, an outline of the principal challenge limitations and a road-map for the future of ASVspoof. Link to the ASVspoof challenge and related resources: https://www.asvspoof.org/index2021.html
The VoicePrivacy 2020 Challenge Evaluation Plan
May 14, 2022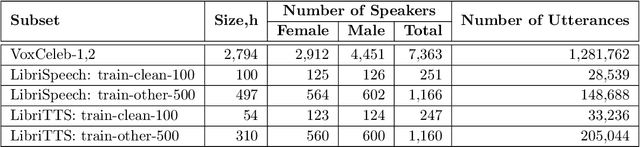
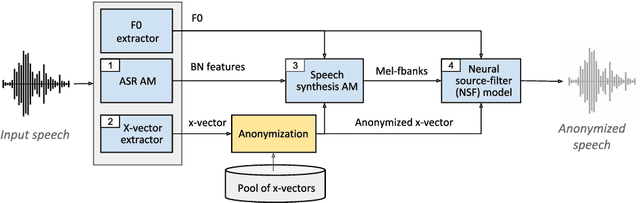
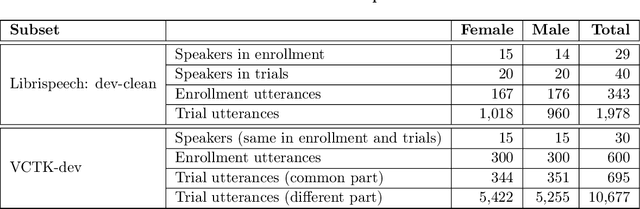
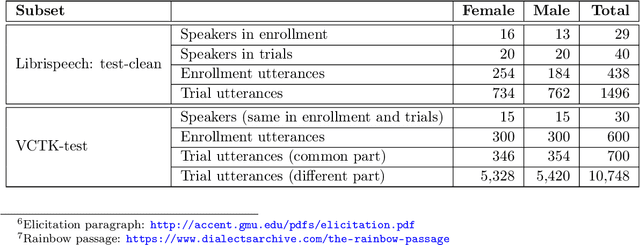
The VoicePrivacy Challenge aims to promote the development of privacy preservation tools for speech technology by gathering a new community to define the tasks of interest and the evaluation methodology, and benchmarking solutions through a series of challenges. In this document, we formulate the voice anonymization task selected for the VoicePrivacy 2020 Challenge and describe the datasets used for system development and evaluation. We also present the attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and report objective evaluation results.
A bridge between features and evidence for binary attribute-driven perfect privacy
Oct 12, 2021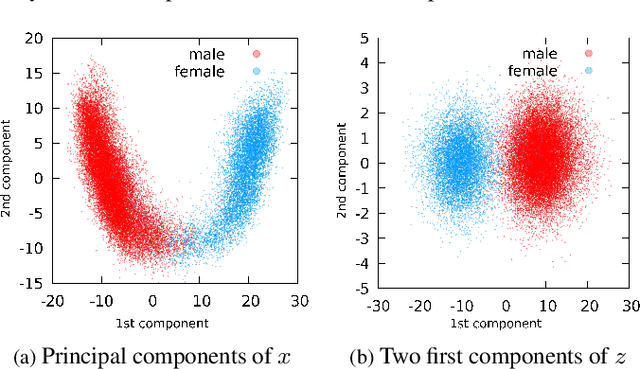
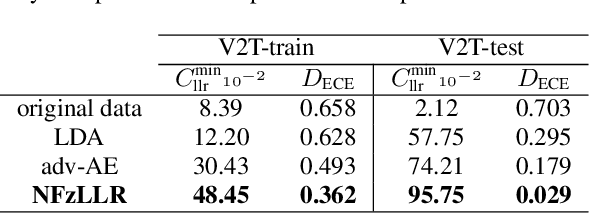
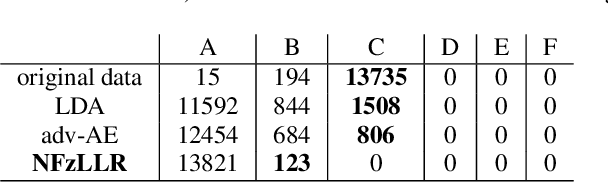
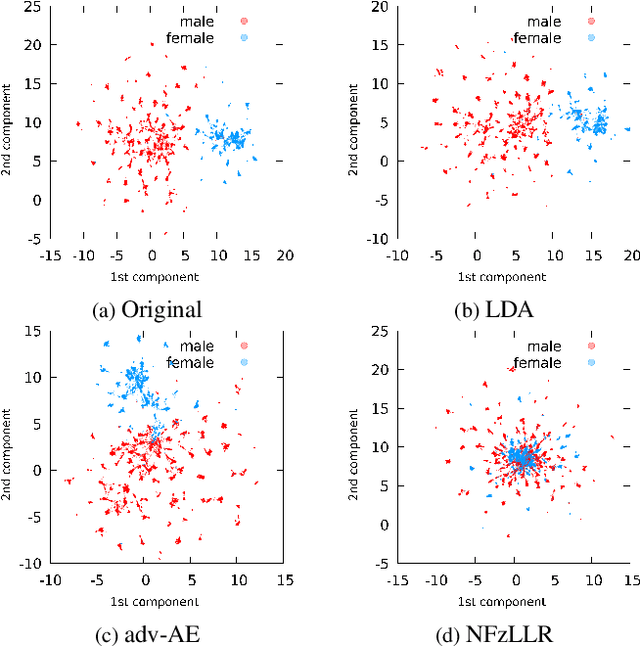
Attribute-driven privacy aims to conceal a single user's attribute, contrary to anonymisation that tries to hide the full identity of the user in some data. When the attribute to protect from malicious inferences is binary, perfect privacy requires the log-likelihood-ratio to be zero resulting in no strength-of-evidence. This work presents an approach based on normalizing flow that maps a feature vector into a latent space where the strength-of-evidence, related to the binary attribute, and an independent residual are disentangled. It can be seen as a non-linear discriminant analysis where the mapping is invertible allowing generation by mapping the latent variable back to the original space. This framework allows to manipulate the log-likelihood-ratio of the data and thus to set it to zero for privacy. We show the applicability of the approach on an attribute-driven privacy task where the sex information is removed from speaker embeddings. Results on VoxCeleb2 dataset show the efficiency of the method that outperforms in terms of privacy and utility our previous experiments based on adversarial disentanglement.
The VoicePrivacy 2020 Challenge: Results and findings
Sep 01, 2021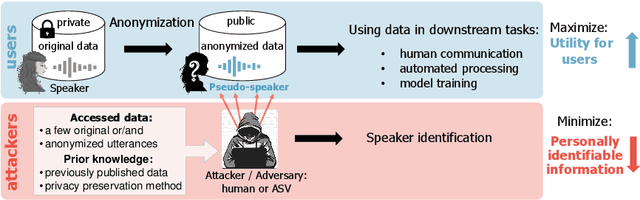
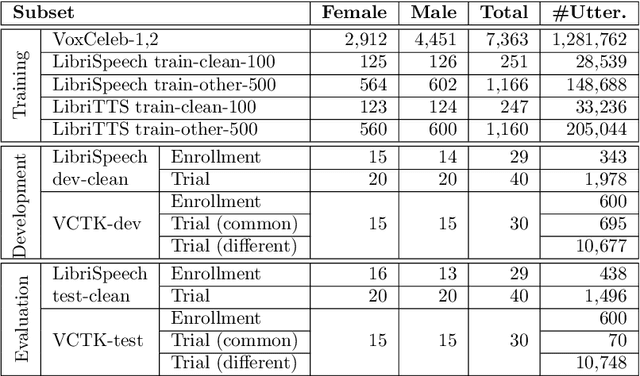
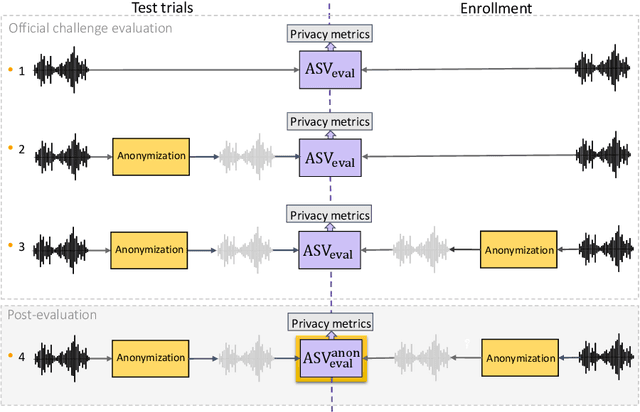
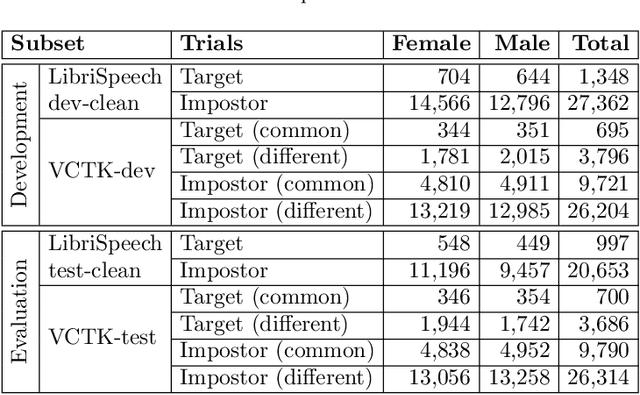
This paper presents the results and analyses stemming from the first VoicePrivacy 2020 Challenge which focuses on developing anonymization solutions for speech technology. We provide a systematic overview of the challenge design with an analysis of submitted systems and evaluation results. In particular, we describe the voice anonymization task and datasets used for system development and evaluation. Also, we present different attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and provide a summary description of the anonymization systems developed by the challenge participants. We report objective and subjective evaluation results for baseline and submitted systems. In addition, we present experimental results for alternative privacy metrics and attack models developed as a part of the post-evaluation analysis. Finally, we summarize our insights and observations that will influence the design of the next VoicePrivacy challenge edition and some directions for future voice anonymization research.
ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection
Sep 01, 2021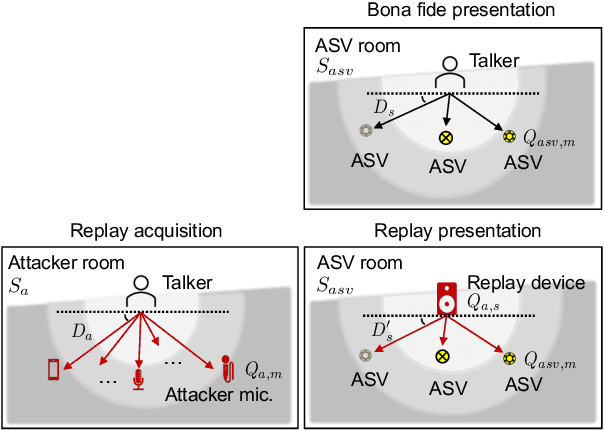
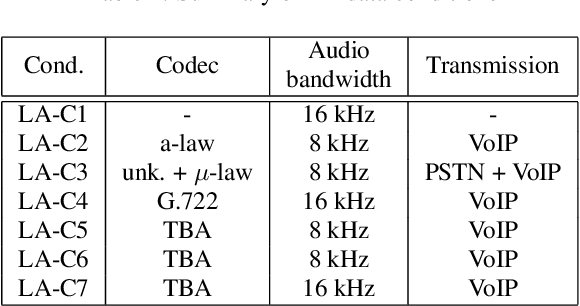
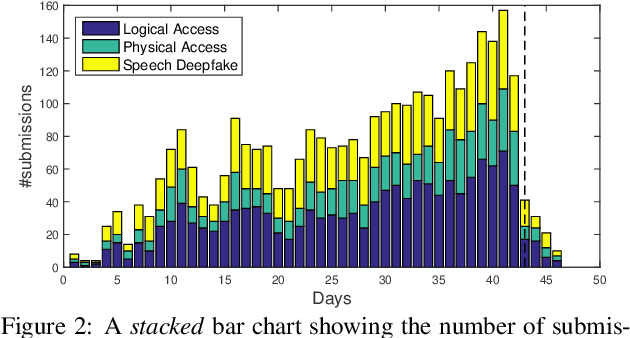
ASVspoof 2021 is the forth edition in the series of bi-annual challenges which aim to promote the study of spoofing and the design of countermeasures to protect automatic speaker verification systems from manipulation. In addition to a continued focus upon logical and physical access tasks in which there are a number of advances compared to previous editions, ASVspoof 2021 introduces a new task involving deepfake speech detection. This paper describes all three tasks, the new databases for each of them, the evaluation metrics, four challenge baselines, the evaluation platform and a summary of challenge results. Despite the introduction of channel and compression variability which compound the difficulty, results for the logical access and deepfake tasks are close to those from previous ASVspoof editions. Results for the physical access task show the difficulty in detecting attacks in real, variable physical spaces. With ASVspoof 2021 being the first edition for which participants were not provided with any matched training or development data and with this reflecting real conditions in which the nature of spoofed and deepfake speech can never be predicated with confidence, the results are extremely encouraging and demonstrate the substantial progress made in the field in recent years.
ASVspoof 2021: Automatic Speaker Verification Spoofing and Countermeasures Challenge Evaluation Plan
Sep 01, 2021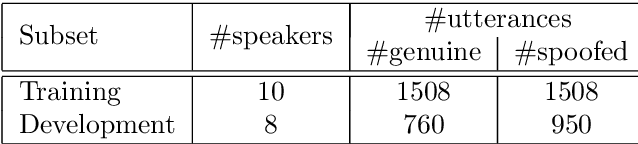
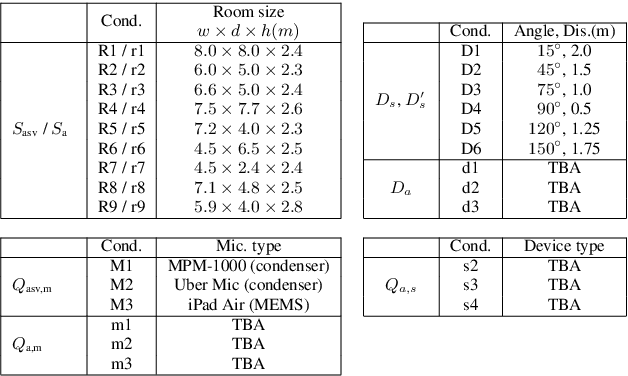
The automatic speaker verification spoofing and countermeasures (ASVspoof) challenge series is a community-led initiative which aims to promote the consideration of spoofing and the development of countermeasures. ASVspoof 2021 is the 4th in a series of bi-annual, competitive challenges where the goal is to develop countermeasures capable of discriminating between bona fide and spoofed or deepfake speech. This document provides a technical description of the ASVspoof 2021 challenge, including details of training, development and evaluation data, metrics, baselines, evaluation rules, submission procedures and the schedule.