 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploratory Evaluation of Speech Content Masking
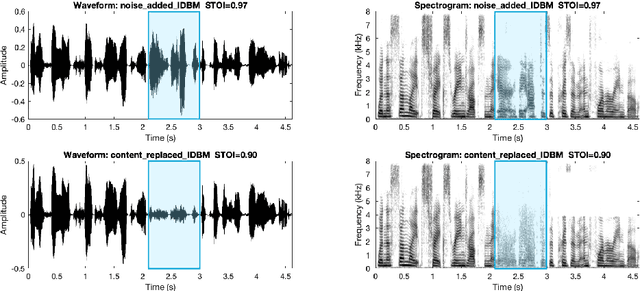
Jan 08, 2024Most recent speech privacy efforts have focused on anonymizing acoustic speaker attributes but there has not been as much research into protecting information from speech content. We introduce a toy problem that explores an emerging type of privacy called "content masking" which conceals selected words and phrases in speech. In our efforts to define this problem space, we evaluate an introductory baseline masking technique based on modifying sequences of discrete phone representations (phone codes) produced from a pre-trained vector-quantized variational autoencoder (VQ-VAE) and re-synthesized using WaveRNN. We investigate three different masking locations and three types of masking strategies: noise substitution, word deletion, and phone sequence reversal. Our work attempts to characterize how masking affects two downstream tasks: automatic speech recognition (ASR) and automatic speaker verification (ASV). We observe how the different masks types and locations impact these downstream tasks and discuss how these issues may influence privacy goals.
New Challenges for Content Privacy in Speech and Audio
Jan 21, 2023Privacy in speech and audio has many facets. A particularly under-developed area of privacy in this domain involves consideration for information related to content and context. Speech content can include words and their meaning or even stylistic markers, pathological speech, intonation patterns, or emotion. More generally, audio captured in-the-wild may contain background speech or reveal contextual information such as markers of location, room characteristics, paralinguistic sounds, or other audible events. Audio recording devices and speech technologies are becoming increasingly commonplace in everyday life. At the same time, commercialised speech and audio technologies do not provide consumers with a range of privacy choices. Even where privacy is regulated or protected by law, technical solutions to privacy assurance and enforcement fall short. This position paper introduces three important and timely research challenges for content privacy in speech and audio. We highlight current gaps and opportunities, and identify focus areas, that could have significant implications for developing ethical and safer speech technologies.
Revisiting Speech Content Privacy
Oct 13, 2021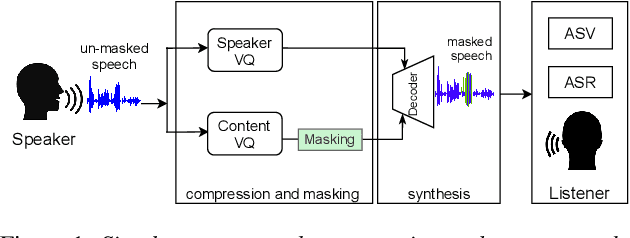
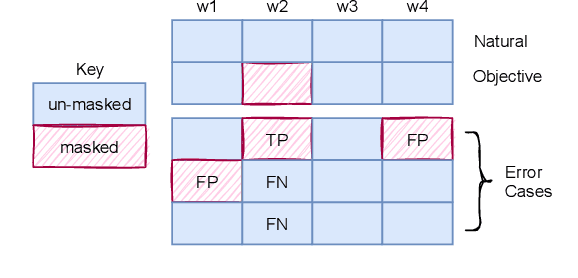
In this paper, we discuss an important aspect of speech privacy: protecting spoken content. New capabilities from the field of machine learning provide a unique and timely opportunity to revisit speech content protection. There are many different applications of content privacy, even though this area has been under-explored in speech technology research. This paper presents several scenarios that indicate a need for speech content privacy even as the specific techniques to achieve content privacy may necessarily vary. Our discussion includes several different types of content privacy including recoverable and non-recoverable content. Finally, we introduce evaluation strategies as well as describe some of the difficulties that may be encountered.
Benchmarking and challenges in security and privacy for voice biometrics
Sep 01, 2021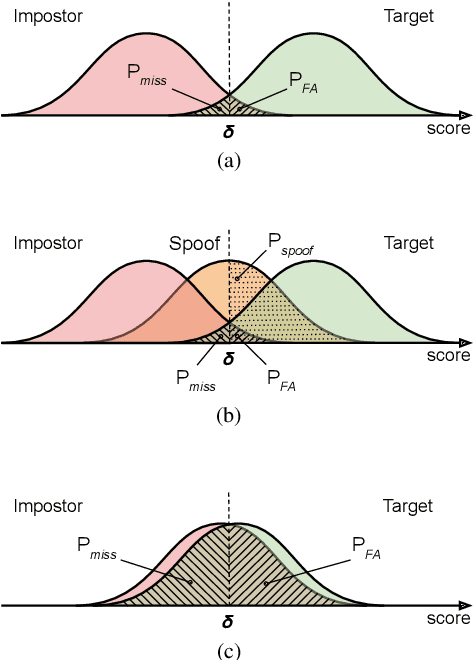
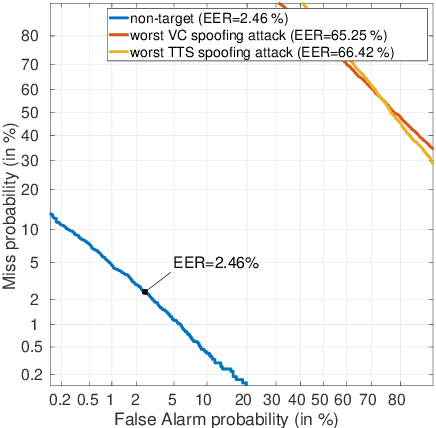
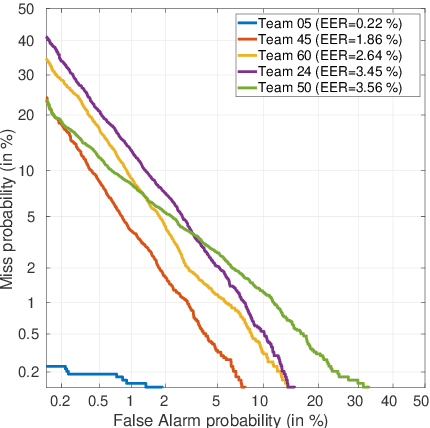
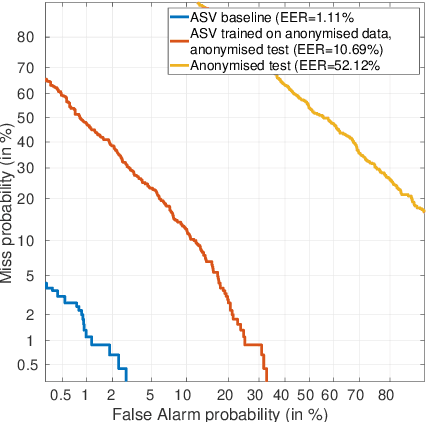
For many decades, research in speech technologies has focused upon improving reliability. With this now meeting user expectations for a range of diverse applications, speech technology is today omni-present. As result, a focus on security and privacy has now come to the fore. Here, the research effort is in its relative infancy and progress calls for greater, multidisciplinary collaboration with security, privacy, legal and ethical experts among others. Such collaboration is now underway. To help catalyse the efforts, this paper provides a high-level overview of some related research. It targets the non-speech audience and describes the benchmarking methodology that has spearheaded progress in traditional research and which now drives recent security and privacy initiatives related to voice biometrics. We describe: the ASVspoof challenge relating to the development of spoofing countermeasures; the VoicePrivacy initiative which promotes research in anonymisation for privacy preservation.