 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Vision to Text: A Compact Multimodal Approach for Robust, Cross-Domain Presentation Attack Detection on ID Cards
Jun 05, 2026Cross-domain shifts challenge Presentation Attack Detection (PAD) on ID Cards, given the restricted data available due to privacy concerns. This work proposes a compact multimodal model, based on new generative and discriminative blocks, which combines visual and textual data for PAD on genuine and synthetic ID images. While multimodal models exhibit strong generalisation after supervised fine-tuning, they fail in zero-shot settings. Our findings underscore that model capacity and real-world data are essential for reliable PAD, while existing synthetic datasets may not reflect real-world challenges. We argue for a re-evaluation of synthetic data as a benchmark and emphasise the need for more realistic, diverse datasets to advance PAD research.
Modelling Emotions is an Elusive Pursuit in Affective Computing
Mar 24, 2026Affective computing - combining sensor technology, machine learning, and psychology - have been studied for over three decades and is employed in AI-powered technologies to enhance emotional awareness in AI systems, and detect symptoms of mental health disorders such as anxiety and depression. However, the uncertainty in such systems remains high, and the application areas are limited by categorical definitions of emotions and emotional concepts. This paper argues that categorical emotion labels obscure emotional nuance in affective computing, and therefore continuous dimensional definitions are needed to advance the field, increase application usefulness, and lower uncertainties.
Beyond Word Error Rate: Auditing the Diversity Tax in Speech Recognition through Dataset Cartography
Mar 05, 2026Automatic speech recognition (ASR) systems are predominantly evaluated using the Word Error Rate (WER). However, raw token-level metrics fail to capture semantic fidelity and routinely obscures the `diversity tax', the disproportionate burden on marginalized and atypical speaker due to systematic recognition failures. In this paper, we explore the limitations of relying solely on lexical counts by systematically evaluating a broader class of non-linear and semantic metrics. To enable rigorous model auditing, we introduce the sample difficulty index (SDI), a novel metric that quantifies how intrinsic demographic and acoustic factors drive model failure. By mapping SDI on data cartography, we demonstrate that metrics EmbER and SemDist expose hidden systemic biases and inter-model disagreements that WER ignores. Finally, our findings are the first steps towards a robust audit framework for prospective safety analysis, empowering developers to audit and mitigate ASR disparities prior to deployment.
Measuring What VLMs Don't Say: Validation Metrics Hide Clinical Terminology Erasure in Radiology Report Generation
Mar 02, 2026Reliable deployment of Vision-Language Models (VLMs) in radiology requires validation metrics that go beyond surface-level text similarity to ensure clinical fidelity and demographic fairness. This paper investigates a critical blind spot in current model evaluation: the use of decoding strategies that lead to high aggregate token-overlap scores despite succumbing to template collapse, in which models generate only repetitive, safe generic text and omit clinical terminology. Unaddressed, this blind spot can lead to metric gaming, where models that perform well on benchmarks prove clinically uninformative. Instead, we advocate for lexical diversity measures to check model generations for clinical specificity. We introduce Clinical Association Displacement (CAD), a vocabulary-level framework that quantifies shifts in demographic-based word associations in generated reports. Weighted Association Erasure (WAE) aggregates these shifts to measure the clinical signal loss across demographic groups. We show that deterministic decoding produces high levels of semantic erasure, while stochastic sampling generates diverse outputs but risks introducing new bias, motivating a fundamental rethink of how "optimal" reporting is defined.
Intra-Fairness Dynamics: The Bias Spillover Effect in Targeted LLM Alignment
Feb 18, 2026Conventional large language model (LLM) fairness alignment largely focuses on mitigating bias along single sensitive attributes, overlooking fairness as an inherently multidimensional and context-specific value. This approach risks creating systems that achieve narrow fairness metrics while exacerbating disparities along untargeted attributes, a phenomenon known as bias spillover. While extensively studied in machine learning, bias spillover remains critically underexplored in LLM alignment. In this work, we investigate how targeted gender alignment affects fairness across nine sensitive attributes in three state-of-the-art LLMs (Mistral 7B, Llama 3.1 8B, Qwen 2.5 7B). Using Direct Preference Optimization and the BBQ benchmark, we evaluate fairness under ambiguous and disambiguous contexts. Our findings reveal noticeable bias spillover: while aggregate results show improvements, context-aware analysis exposes significant degradations in ambiguous contexts, particularly for physical appearance ($p< 0.001$ across all models), sexual orientation, and disability status. We demonstrate that improving fairness along one attribute can inadvertently worsen disparities in others under uncertainty, highlighting the necessity of context-aware, multi-attribute fairness evaluation frameworks.
Who Does Your Algorithm Fail? Investigating Age and Ethnic Bias in the MAMA-MIA Dataset
Oct 31, 2025Deep learning models aim to improve diagnostic workflows, but fairness evaluation remains underexplored beyond classification, e.g., in image segmentation. Unaddressed segmentation bias can lead to disparities in the quality of care for certain populations, potentially compounded across clinical decision points and amplified through iterative model development. Here, we audit the fairness of the automated segmentation labels provided in the breast cancer tumor segmentation dataset MAMA-MIA. We evaluate automated segmentation quality across age, ethnicity, and data source. Our analysis reveals an intrinsic age-related bias against younger patients that continues to persist even after controlling for confounding factors, such as data source. We hypothesize that this bias may be linked to physiological factors, a known challenge for both radiologists and automated systems. Finally, we show how aggregating data from multiple data sources influences site-specific ethnic biases, underscoring the necessity of investigating data at a granular level.
EmoTale: An Enacted Speech-emotion Dataset in Danish
Aug 20, 2025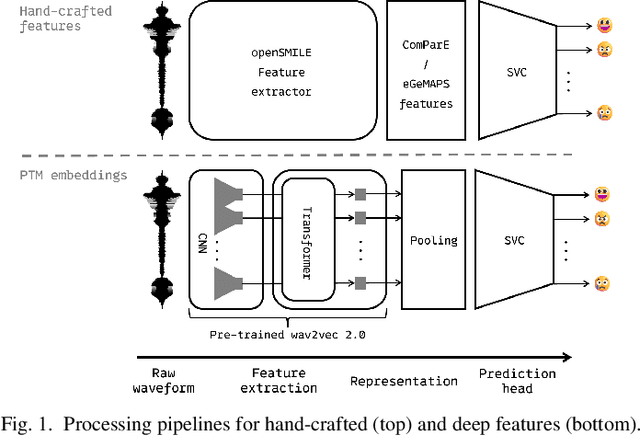
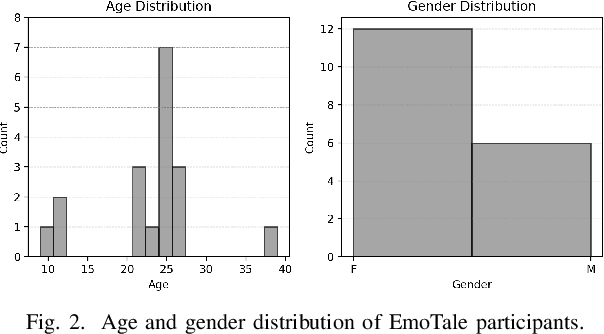
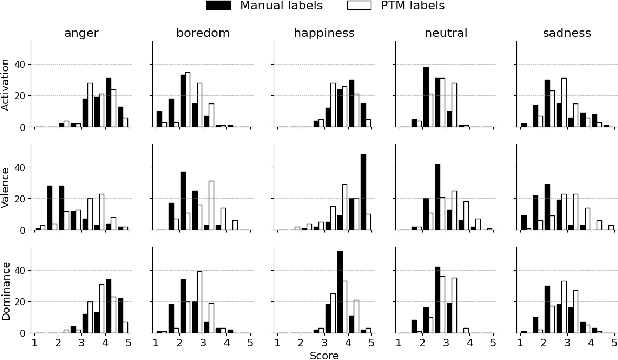
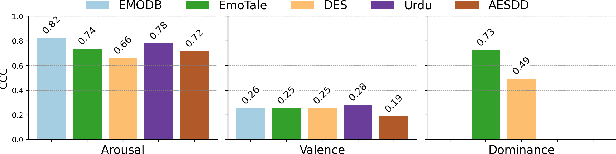
While multiple emotional speech corpora exist for commonly spoken languages, there is a lack of functional datasets for smaller (spoken) languages, such as Danish. To our knowledge, Danish Emotional Speech (DES), published in 1997, is the only other database of Danish emotional speech. We present EmoTale; a corpus comprising Danish and English speech recordings with their associated enacted emotion annotations. We demonstrate the validity of the dataset by investigating and presenting its predictive power using speech emotion recognition (SER) models. We develop SER models for EmoTale and the reference datasets using self-supervised speech model (SSLM) embeddings and the openSMILE feature extractor. We find the embeddings superior to the hand-crafted features. The best model achieves an unweighted average recall (UAR) of 64.1% on the EmoTale corpus using leave-one-speaker-out cross-validation, comparable to the performance on DES.
Exploring Local Interpretable Model-Agnostic Explanations for Speech Emotion Recognition with Distribution-Shift
Apr 07, 2025We introduce EmoLIME, a version of local interpretable model-agnostic explanations (LIME) for black-box Speech Emotion Recognition (SER) models. To the best of our knowledge, this is the first attempt to apply LIME in SER. EmoLIME generates high-level interpretable explanations and identifies which specific frequency ranges are most influential in determining emotional states. The approach aids in interpreting complex, high-dimensional embeddings such as those generated by end-to-end speech models. We evaluate EmoLIME, qualitatively, quantitatively, and statistically, across three emotional speech datasets, using classifiers trained on both hand-crafted acoustic features and Wav2Vec 2.0 embeddings. We find that EmoLIME exhibits stronger robustness across different models than across datasets with distribution shifts, highlighting its potential for more consistent explanations in SER tasks within a dataset.
Is it the model or the metric -- On robustness measures of deeplearning models
Dec 13, 2024Determining the robustness of deep learning models is an established and ongoing challenge within automated decision-making systems. With the advent and success of techniques that enable advanced deep learning (DL), these models are being used in widespread applications, including high-stake ones like healthcare, education, border-control. Therefore, it is critical to understand the limitations of these models and predict their regions of failures, in order to create the necessary guardrails for their successful and safe deployment. In this work, we revisit robustness, specifically investigating the sufficiency of robust accuracy (RA), within the context of deepfake detection. We present robust ratio (RR) as a complementary metric, that can quantify the changes to the normalized or probability outcomes under input perturbation. We present a comparison of RA and RR and demonstrate that despite similar RA between models, the models show varying RR under different tolerance (perturbation) levels.
Examining the Interplay Between Privacy and Fairness for Speech Processing: A Review and Perspective
Sep 05, 2024Speech technology has been increasingly deployed in various areas of daily life including sensitive domains such as healthcare and law enforcement. For these technologies to be effective, they must work reliably for all users while preserving individual privacy. Although tradeoffs between privacy and utility, as well as fairness and utility, have been extensively researched, the specific interplay between privacy and fairness in speech processing remains underexplored. This review and position paper offers an overview of emerging privacy-fairness tradeoffs throughout the entire machine learning lifecycle for speech processing. By drawing on well-established frameworks on fairness and privacy, we examine existing biases and sources of privacy harm that coexist during the development of speech processing models. We then highlight how corresponding privacy-enhancing technologies have the potential to inadvertently increase these biases and how bias mitigation strategies may conversely reduce privacy. By raising open questions, we advocate for a comprehensive evaluation of privacy-fairness tradeoffs for speech technology and the development of privacy-enhancing and fairness-aware algorithms in this domain.