 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Detection For Child-Clinician Conversations In Danish For Low-Resource In-The-Wild Conditions: A Case Study
Apr 25, 2022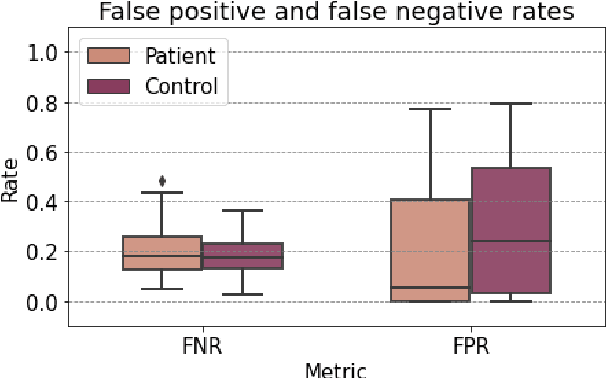
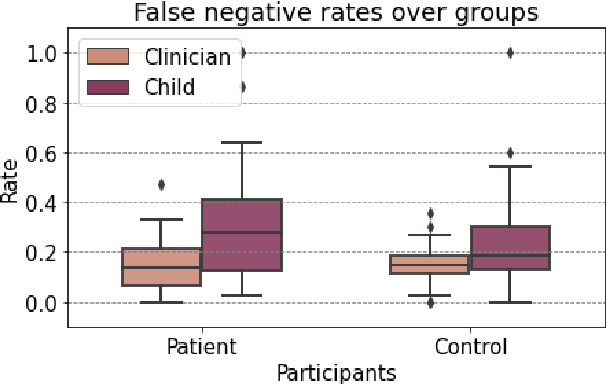

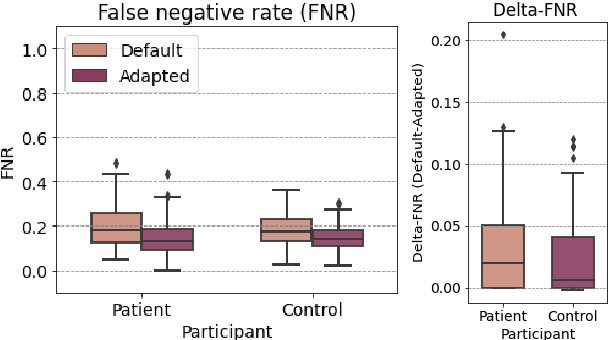
Use of speech models for automatic speech processing tasks can improve efficiency in the screening, analysis, diagnosis and treatment in medicine and psychiatry. However, the performance of pre-processing speech tasks like segmentation and diarization can drop considerably on in-the-wild clinical data, specifically when the target dataset comprises of atypical speech. In this paper we study the performance of a pre-trained speech model on a dataset comprising of child-clinician conversations in Danish with respect to the classification threshold. Since we do not have access to sufficient labelled data, we propose few-instance threshold adaptation, wherein we employ the first minutes of the speech conversation to obtain the optimum classification threshold. Through our work in this paper, we learned that the model with default classification threshold performs worse on children from the patient group. Furthermore, the error rates of the model is directly correlated to the severity of diagnosis in the patients. Lastly, our study on few-instance adaptation shows that three-minutes of clinician-child conversation is sufficient to obtain the optimum classification threshold.
Continuous Metric Learning For Transferable Speech Emotion Recognition and Embedding Across Low-resource Languages
Mar 28, 2022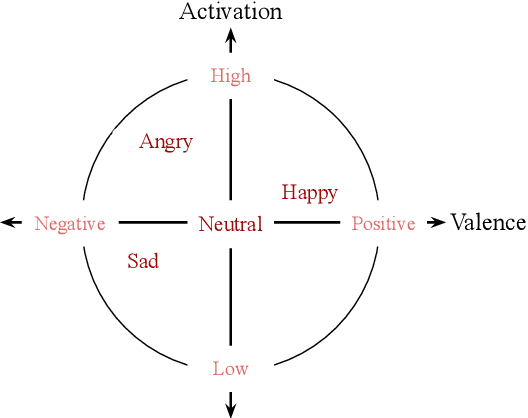


Speech emotion recognition~(SER) refers to the technique of inferring the emotional state of an individual from speech signals. SERs continue to garner interest due to their wide applicability. Although the domain is mainly founded on signal processing, machine learning, and deep learning, generalizing over languages continues to remain a challenge. However, developing generalizable and transferable models are critical due to a lack of sufficient resources in terms of data and labels for languages beyond the most commonly spoken ones. To improve performance over languages, we propose a denoising autoencoder with semi-supervision using a continuous metric loss based on either activation or valence. The novelty of this work lies in our proposal of continuous metric learning, which is among the first proposals on the topic to the best of our knowledge. Furthermore, to address the lack of activation and valence labels in the transfer datasets, we annotate the signal samples with activation and valence levels corresponding to a dimensional model of emotions, which were then used to evaluate the quality of the embedding over the transfer datasets. We show that the proposed semi-supervised model consistently outperforms the baseline unsupervised method, which is a conventional denoising autoencoder, in terms of emotion classification accuracy as well as correlation with respect to the dimensional variables. Further evaluation of classification accuracy with respect to the reference, a BERT based speech representation model, shows that the proposed method is comparable to the reference method in classifying specific emotion classes at a much lower complexity.
Towards Transferable Speech Emotion Representation: On loss functions for cross-lingual latent representations
Mar 28, 2022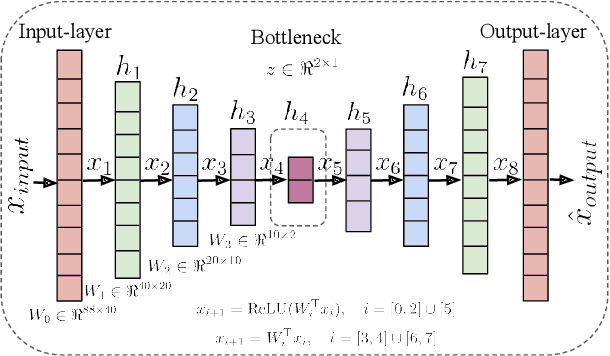

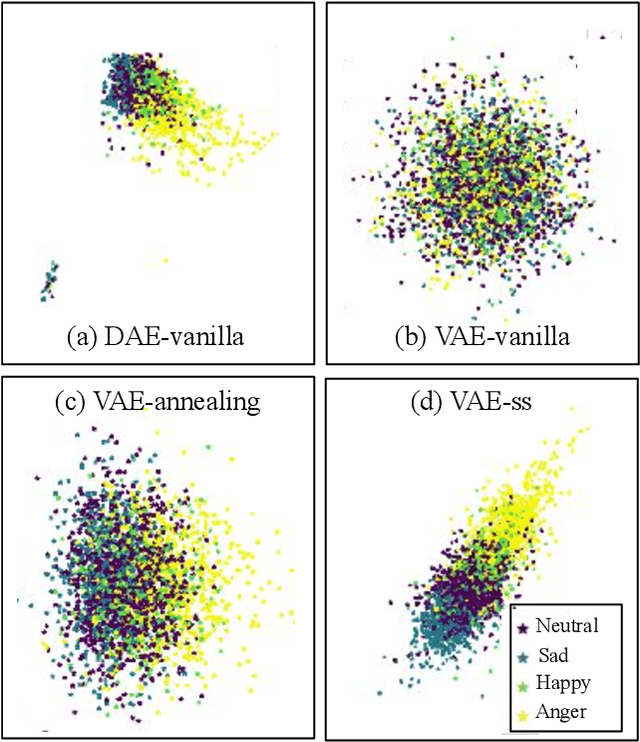
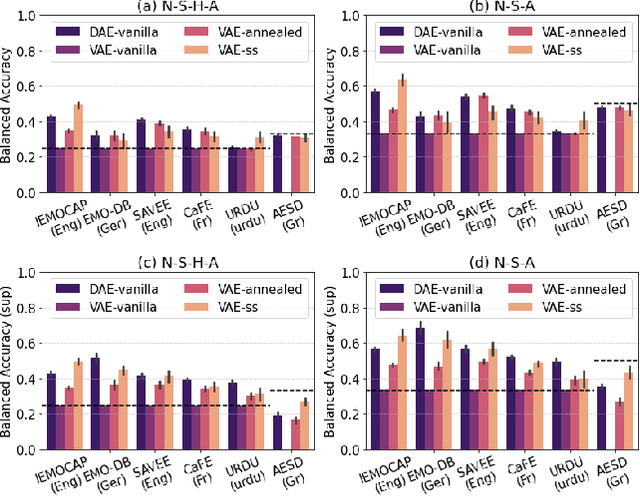
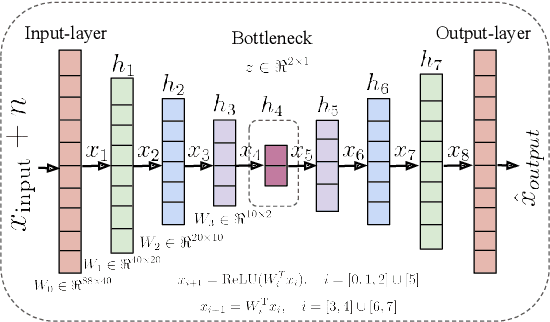
In recent years, speech emotion recognition (SER) has been used in wide ranging applications, from healthcare to the commercial sector. In addition to signal processing approaches, methods for SER now also use deep learning techniques which provide transfer learning possibilities. However, generalizing over languages, corpora and recording conditions is still an open challenge. In this work we address this gap by exploring loss functions that aid in transferability, specifically to non-tonal languages. We propose a variational autoencoder (VAE) with KL annealing and a semi-supervised VAE to obtain more consistent latent embedding distributions across data sets. To ensure transferability, the distribution of the latent embedding should be similar across non-tonal languages (data sets). We start by presenting a low-complexity SER based on a denoising-autoencoder, which achieves an unweighted classification accuracy of over 52.09% for four-class emotion classification. This performance is comparable to that of similar baseline methods. Following this, we employ a VAE, the semi-supervised VAE and the VAE with KL annealing to obtain a more regularized latent space. We show that while the DAE has the highest classification accuracy among the methods, the semi-supervised VAE has a comparable classification accuracy and a more consistent latent embedding distribution over data sets.
Towards Interpretable and Transferable Speech Emotion Recognition: Latent Representation Based Analysis of Features, Methods and Corpora
May 05, 2021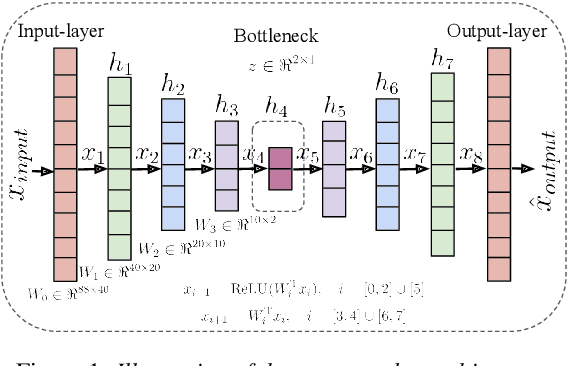
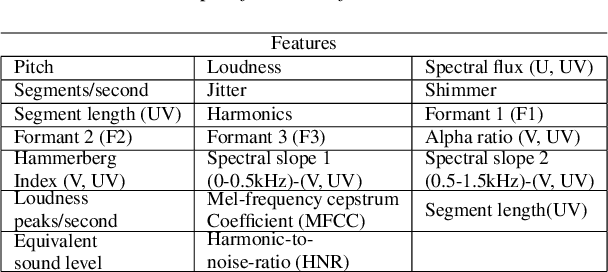
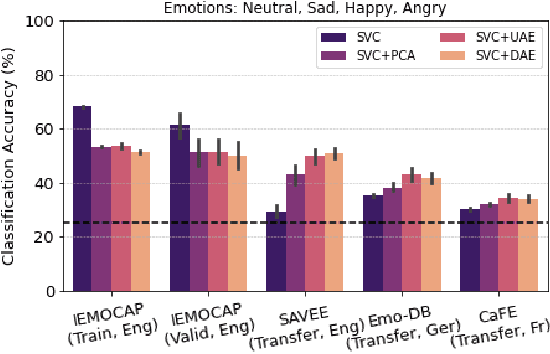
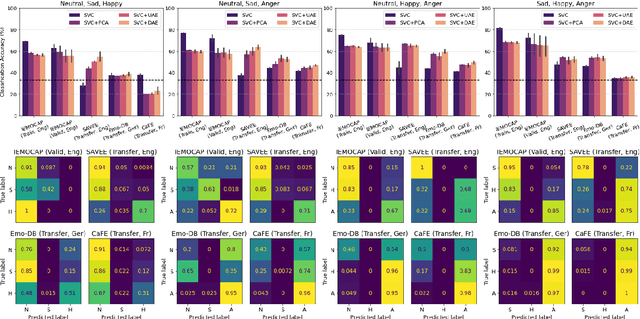
In recent years, speech emotion recognition (SER) has been used in wide ranging applications, from healthcare to the commercial sector. In addition to signal processing approaches, methods for SER now also use deep learning techniques. However, generalizing over languages, corpora and recording conditions is still an open challenge in the field. Furthermore, due to the black-box nature of deep learning algorithms, a newer challenge is the lack of interpretation and transparency in the models and the decision making process. This is critical when the SER systems are deployed in applications that influence human lives. In this work we address this gap by providing an in-depth analysis of the decision making process of the proposed SER system. Towards that end, we present low-complexity SER based on undercomplete- and denoising- autoencoders that achieve an average classification accuracy of over 55\% for four-class emotion classification. Following this, we investigate the clustering of emotions in the latent space to understand the influence of the corpora on the model behavior and to obtain a physical interpretation of the latent embedding. Lastly, we explore the role of each input feature towards the performance of the SER.