 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability by design using computer vision for behavioral sensing in child and adolescent psychiatry
Jul 11, 2022
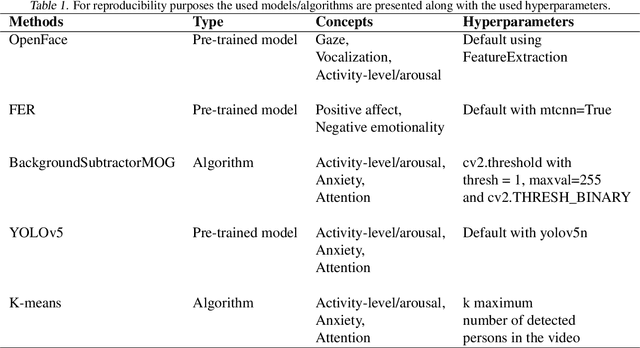
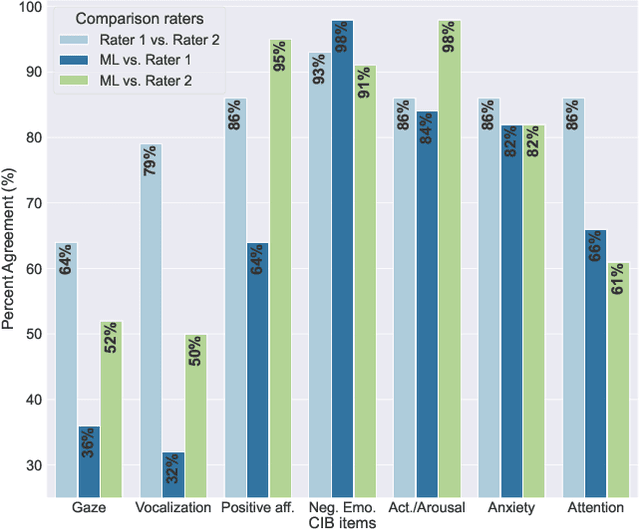

Observation is an essential tool for understanding and studying human behavior and mental states. However, coding human behavior is a time-consuming, expensive task, in which reliability can be difficult to achieve and bias is a risk. Machine learning (ML) methods offer ways to improve reliability, decrease cost, and scale up behavioral coding for application in clinical and research settings. Here, we use computer vision to derive behavioral codes or concepts of a gold standard behavioral rating system, offering familiar interpretation for mental health professionals. Features were extracted from videos of clinical diagnostic interviews of children and adolescents with and without obsessive-compulsive disorder. Our computationally-derived ratings were comparable to human expert ratings for negative emotions, activity-level/arousal and anxiety. For the attention and positive affect concepts, our ML ratings performed reasonably. However, results for gaze and vocalization indicate a need for improved data quality or additional data modalities.
Computational behavior recognition in child and adolescent psychiatry: A statistical and machine learning analysis plan
May 11, 2022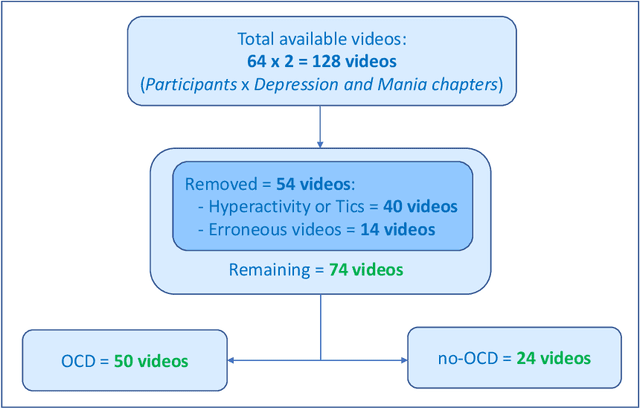
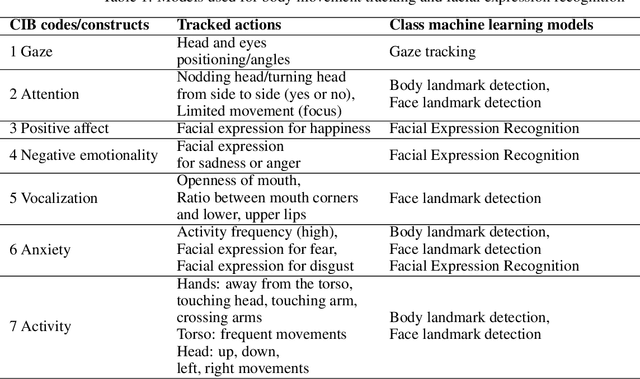
Motivation: Behavioral observations are an important resource in the study and evaluation of psychological phenomena, but it is costly, time-consuming, and susceptible to bias. Thus, we aim to automate coding of human behavior for use in psychotherapy and research with the help of artificial intelligence (AI) tools. Here, we present an analysis plan. Methods: Videos of a gold-standard semi-structured diagnostic interview of 25 youth with obsessive-compulsive disorder (OCD) and 12 youth without a psychiatric diagnosis (no-OCD) will be analyzed. Youth were between 8 and 17 years old. Features from the videos will be extracted and used to compute ratings of behavior, which will be compared to ratings of behavior produced by mental health professionals trained to use a specific behavioral coding manual. We will test the effect of OCD diagnosis on the computationally-derived behavior ratings using multivariate analysis of variance (MANOVA). Using the generated features, a binary classification model will be built and used to classify OCD/no-OCD classes. Discussion: Here, we present a pre-defined plan for how data will be pre-processed, analyzed and presented in the publication of results and their interpretation. A challenge for the proposed study is that the AI approach will attempt to derive behavioral ratings based solely on vision, whereas humans use visual, paralinguistic and linguistic cues to rate behavior. Another challenge will be using machine learning models for body and facial movement detection trained primarily on adults and not on children. If the AI tools show promising results, this pre-registered analysis plan may help reduce interpretation bias. Trial registration: ClinicalTrials.gov - H-18010607
Continuous Metric Learning For Transferable Speech Emotion Recognition and Embedding Across Low-resource Languages
Mar 28, 2022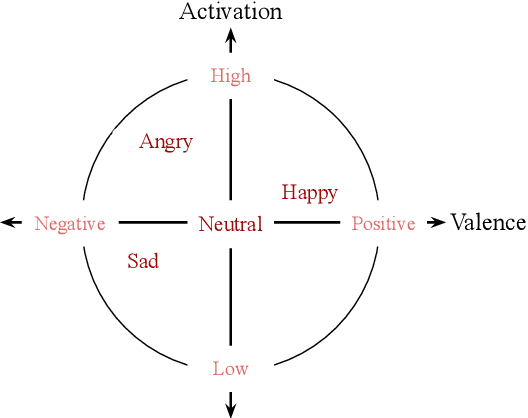

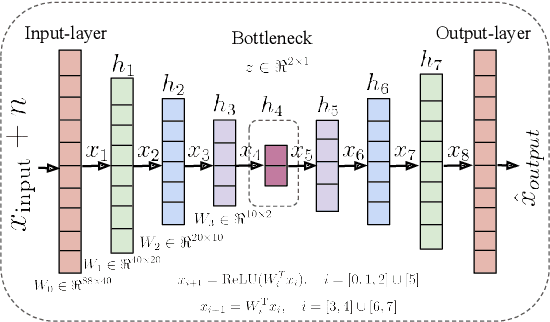

Speech emotion recognition~(SER) refers to the technique of inferring the emotional state of an individual from speech signals. SERs continue to garner interest due to their wide applicability. Although the domain is mainly founded on signal processing, machine learning, and deep learning, generalizing over languages continues to remain a challenge. However, developing generalizable and transferable models are critical due to a lack of sufficient resources in terms of data and labels for languages beyond the most commonly spoken ones. To improve performance over languages, we propose a denoising autoencoder with semi-supervision using a continuous metric loss based on either activation or valence. The novelty of this work lies in our proposal of continuous metric learning, which is among the first proposals on the topic to the best of our knowledge. Furthermore, to address the lack of activation and valence labels in the transfer datasets, we annotate the signal samples with activation and valence levels corresponding to a dimensional model of emotions, which were then used to evaluate the quality of the embedding over the transfer datasets. We show that the proposed semi-supervised model consistently outperforms the baseline unsupervised method, which is a conventional denoising autoencoder, in terms of emotion classification accuracy as well as correlation with respect to the dimensional variables. Further evaluation of classification accuracy with respect to the reference, a BERT based speech representation model, shows that the proposed method is comparable to the reference method in classifying specific emotion classes at a much lower complexity.