 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability by design using computer vision for behavioral sensing in child and adolescent psychiatry
Jul 11, 2022
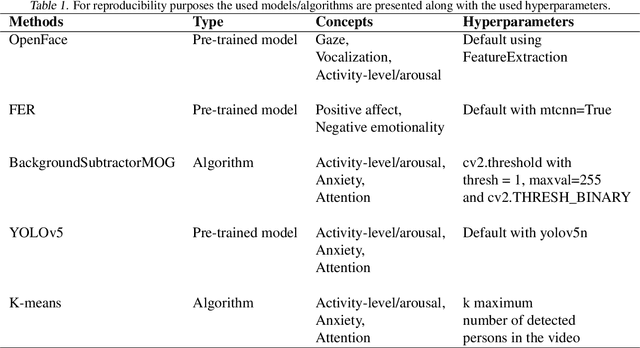
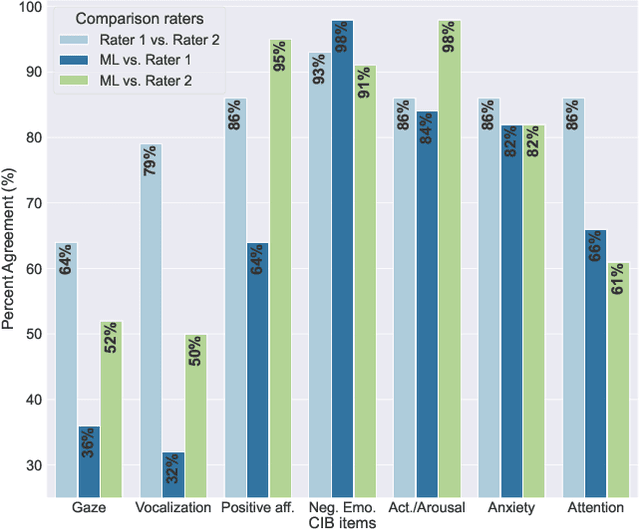

Observation is an essential tool for understanding and studying human behavior and mental states. However, coding human behavior is a time-consuming, expensive task, in which reliability can be difficult to achieve and bias is a risk. Machine learning (ML) methods offer ways to improve reliability, decrease cost, and scale up behavioral coding for application in clinical and research settings. Here, we use computer vision to derive behavioral codes or concepts of a gold standard behavioral rating system, offering familiar interpretation for mental health professionals. Features were extracted from videos of clinical diagnostic interviews of children and adolescents with and without obsessive-compulsive disorder. Our computationally-derived ratings were comparable to human expert ratings for negative emotions, activity-level/arousal and anxiety. For the attention and positive affect concepts, our ML ratings performed reasonably. However, results for gaze and vocalization indicate a need for improved data quality or additional data modalities.
Computational behavior recognition in child and adolescent psychiatry: A statistical and machine learning analysis plan
May 11, 2022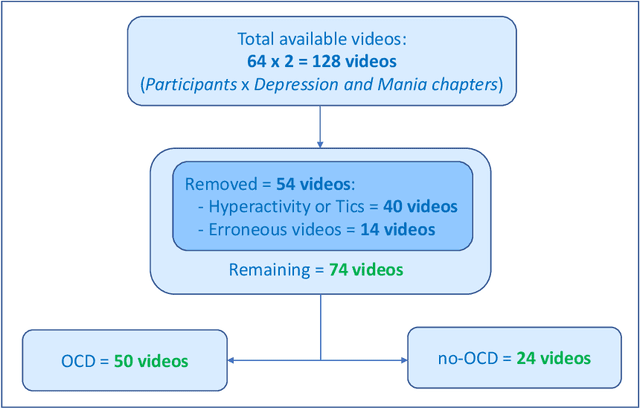
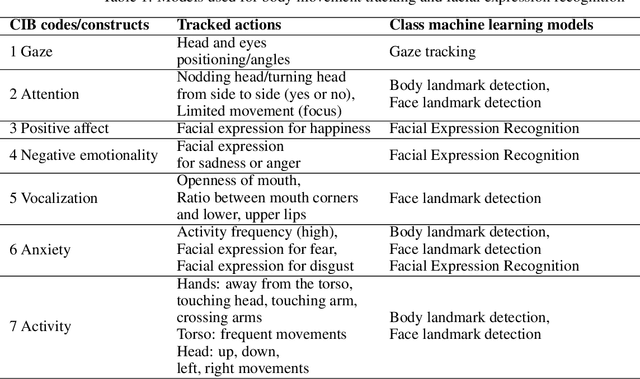
Motivation: Behavioral observations are an important resource in the study and evaluation of psychological phenomena, but it is costly, time-consuming, and susceptible to bias. Thus, we aim to automate coding of human behavior for use in psychotherapy and research with the help of artificial intelligence (AI) tools. Here, we present an analysis plan. Methods: Videos of a gold-standard semi-structured diagnostic interview of 25 youth with obsessive-compulsive disorder (OCD) and 12 youth without a psychiatric diagnosis (no-OCD) will be analyzed. Youth were between 8 and 17 years old. Features from the videos will be extracted and used to compute ratings of behavior, which will be compared to ratings of behavior produced by mental health professionals trained to use a specific behavioral coding manual. We will test the effect of OCD diagnosis on the computationally-derived behavior ratings using multivariate analysis of variance (MANOVA). Using the generated features, a binary classification model will be built and used to classify OCD/no-OCD classes. Discussion: Here, we present a pre-defined plan for how data will be pre-processed, analyzed and presented in the publication of results and their interpretation. A challenge for the proposed study is that the AI approach will attempt to derive behavioral ratings based solely on vision, whereas humans use visual, paralinguistic and linguistic cues to rate behavior. Another challenge will be using machine learning models for body and facial movement detection trained primarily on adults and not on children. If the AI tools show promising results, this pre-registered analysis plan may help reduce interpretation bias. Trial registration: ClinicalTrials.gov - H-18010607
Sampling To Improve Predictions For Underrepresented Observations In Imbalanced Data
Nov 18, 2021
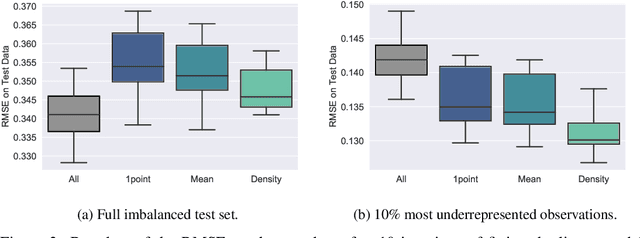

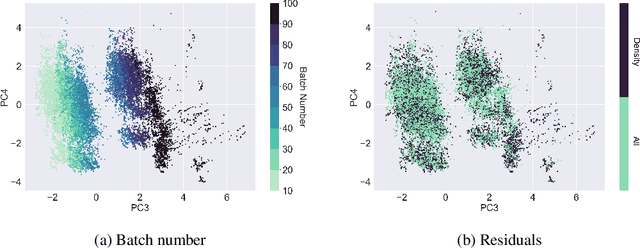
Data imbalance is common in production data, where controlled production settings require data to fall within a narrow range of variation and data are collected with quality assessment in mind, rather than data analytic insights. This imbalance negatively impacts the predictive performance of models on underrepresented observations. We propose sampling to adjust for this imbalance with the goal of improving the performance of models trained on historical production data. We investigate the use of three sampling approaches to adjust for imbalance. The goal is to downsample the covariates in the training data and subsequently fit a regression model. We investigate how the predictive power of the model changes when using either the sampled or the original data for training. We apply our methods on a large biopharmaceutical manufacturing data set from an advanced simulation of penicillin production and find that fitting a model using the sampled data gives a small reduction in the overall predictive performance, but yields a systematically better performance on underrepresented observations. In addition, the results emphasize the need for alternative, fair, and balanced model evaluations.
Unsupervised Spectral Unmixing For Telluric Correction Using A Neural Network Autoencoder
Nov 17, 2021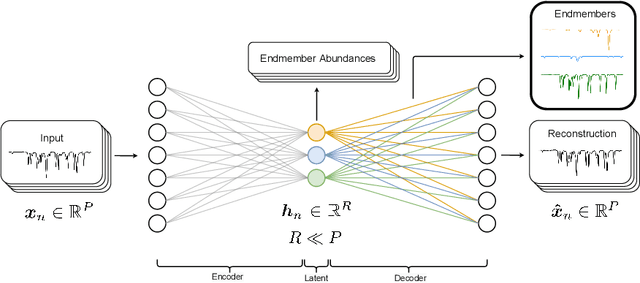
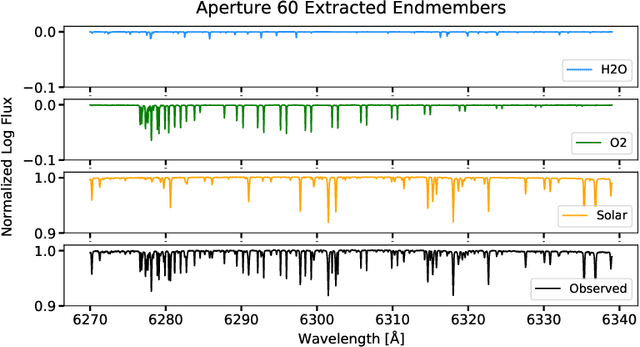

The absorption of light by molecules in the atmosphere of Earth is a complication for ground-based observations of astrophysical objects. Comprehensive information on various molecular species is required to correct for this so called telluric absorption. We present a neural network autoencoder approach for extracting a telluric transmission spectrum from a large set of high-precision observed solar spectra from the HARPS-N radial velocity spectrograph. We accomplish this by reducing the data into a compressed representation, which allows us to unveil the underlying solar spectrum and simultaneously uncover the different modes of variation in the observed spectra relating to the absorption of $\mathrm{H_2O}$ and $\mathrm{O_2}$ in the atmosphere of Earth. We demonstrate how the extracted components can be used to remove $\mathrm{H_2O}$ and $\mathrm{O_2}$ tellurics in a validation observation with similar accuracy and at less computational expense than a synthetic approach with molecfit.