 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Representativity for Machine Learning and AI Systems
Mar 09, 2022
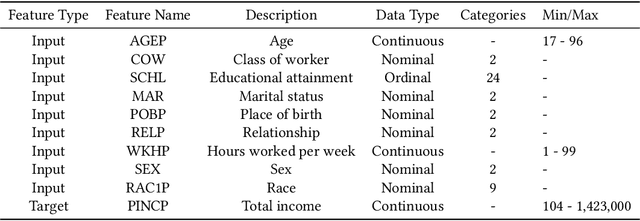
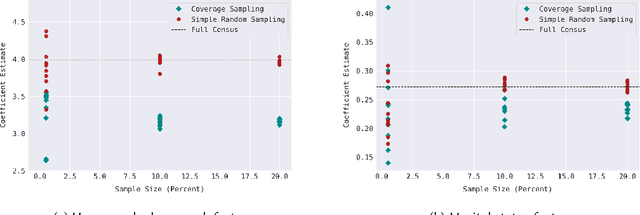

Data representativity is crucial when drawing inference from data through machine learning models. Scholars have increased focus on unraveling the bias and fairness in the models, also in relation to inherent biases in the input data. However, limited work exists on the representativity of samples (datasets) for appropriate inference in AI systems. This paper analyzes data representativity in scientific literature related to AI and sampling, and gives a brief overview of statistical sampling methodology from disciplines like sampling of physical materials, experimental design, survey analysis, and observational studies. Different notions of a 'representative sample' exist in past and present literature. In particular, the contrast between the notion of a representative sample in the sense of coverage of the input space, versus a representative sample as a miniature of the target population is of relevance when building AI systems. Using empirical demonstrations on US Census data, we demonstrate that the first is useful for providing equality and demographic parity, and is more robust to distribution shifts, whereas the latter notion is useful in situations where the purpose is to make historical inference or draw inference about the underlying population in general, or make better predictions for the majority in the underlying population. We propose a framework of questions for creating and documenting data, with data representativity in mind, as an addition to existing datasheets for datasets. Finally, we will also like to call for caution of implicit, in addition to explicit, use of a notion of data representativeness without specific clarification.
Sampling To Improve Predictions For Underrepresented Observations In Imbalanced Data
Nov 18, 2021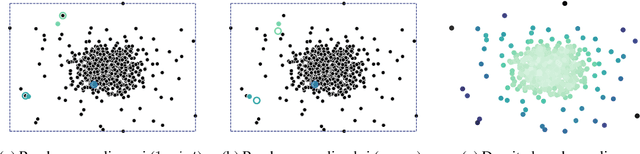
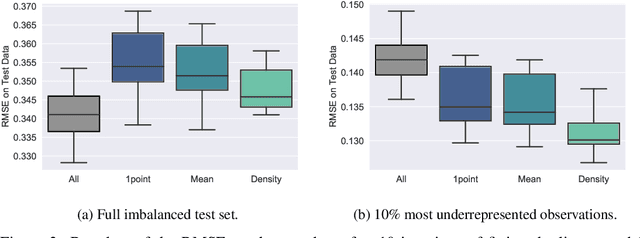

Data imbalance is common in production data, where controlled production settings require data to fall within a narrow range of variation and data are collected with quality assessment in mind, rather than data analytic insights. This imbalance negatively impacts the predictive performance of models on underrepresented observations. We propose sampling to adjust for this imbalance with the goal of improving the performance of models trained on historical production data. We investigate the use of three sampling approaches to adjust for imbalance. The goal is to downsample the covariates in the training data and subsequently fit a regression model. We investigate how the predictive power of the model changes when using either the sampled or the original data for training. We apply our methods on a large biopharmaceutical manufacturing data set from an advanced simulation of penicillin production and find that fitting a model using the sampled data gives a small reduction in the overall predictive performance, but yields a systematically better performance on underrepresented observations. In addition, the results emphasize the need for alternative, fair, and balanced model evaluations.
Unsupervised Spectral Unmixing For Telluric Correction Using A Neural Network Autoencoder
Nov 17, 2021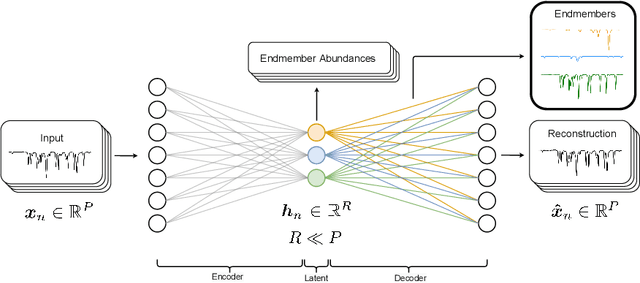
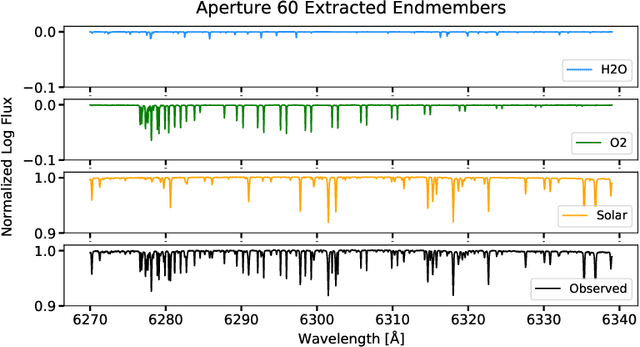

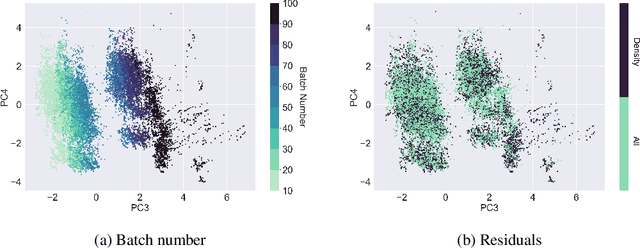
The absorption of light by molecules in the atmosphere of Earth is a complication for ground-based observations of astrophysical objects. Comprehensive information on various molecular species is required to correct for this so called telluric absorption. We present a neural network autoencoder approach for extracting a telluric transmission spectrum from a large set of high-precision observed solar spectra from the HARPS-N radial velocity spectrograph. We accomplish this by reducing the data into a compressed representation, which allows us to unveil the underlying solar spectrum and simultaneously uncover the different modes of variation in the observed spectra relating to the absorption of $\mathrm{H_2O}$ and $\mathrm{O_2}$ in the atmosphere of Earth. We demonstrate how the extracted components can be used to remove $\mathrm{H_2O}$ and $\mathrm{O_2}$ tellurics in a validation observation with similar accuracy and at less computational expense than a synthetic approach with molecfit.