 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-hoc Self-explanation of CNNs
Mar 30, 2026Although standard Convolutional Neural Networks (CNNs) can be mathematically reinterpreted as Self-Explainable Models (SEMs), their built-in prototypes do not on their own accurately represent the data. Replacing the final linear layer with a $k$-means-based classifier addresses this limitation without compromising performance. This work introduces a common formalization of $k$-means-based post-hoc explanations for the classifier, the encoder's final output (B4), and combinations of intermediate feature activations. The latter approach leverages the spatial consistency of convolutional receptive fields to generate concept-based explanation maps, which are supported by gradient-free feature attribution maps. Empirical evaluation with a ResNet34 shows that using shallower, less compressed feature activations, such as those from the last three blocks (B234), results in a trade-off between semantic fidelity and a slight reduction in predictive performance.
Beyond Word Error Rate: Auditing the Diversity Tax in Speech Recognition through Dataset Cartography
Mar 05, 2026Automatic speech recognition (ASR) systems are predominantly evaluated using the Word Error Rate (WER). However, raw token-level metrics fail to capture semantic fidelity and routinely obscures the `diversity tax', the disproportionate burden on marginalized and atypical speaker due to systematic recognition failures. In this paper, we explore the limitations of relying solely on lexical counts by systematically evaluating a broader class of non-linear and semantic metrics. To enable rigorous model auditing, we introduce the sample difficulty index (SDI), a novel metric that quantifies how intrinsic demographic and acoustic factors drive model failure. By mapping SDI on data cartography, we demonstrate that metrics EmbER and SemDist expose hidden systemic biases and inter-model disagreements that WER ignores. Finally, our findings are the first steps towards a robust audit framework for prospective safety analysis, empowering developers to audit and mitigate ASR disparities prior to deployment.
EmoTale: An Enacted Speech-emotion Dataset in Danish
Aug 20, 2025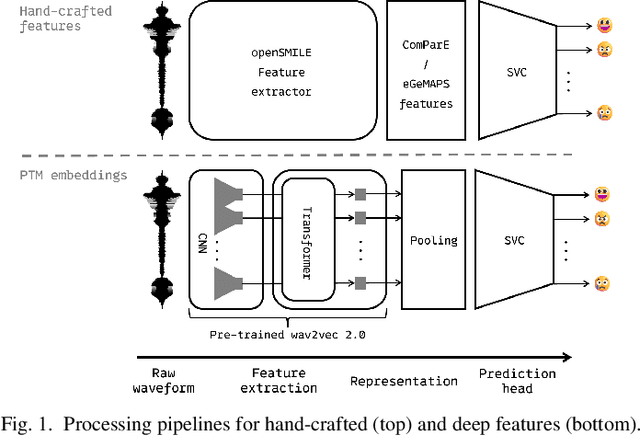
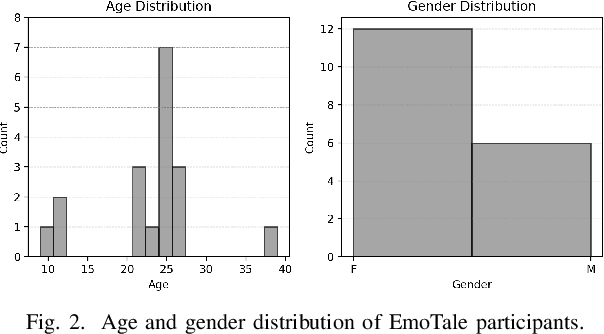
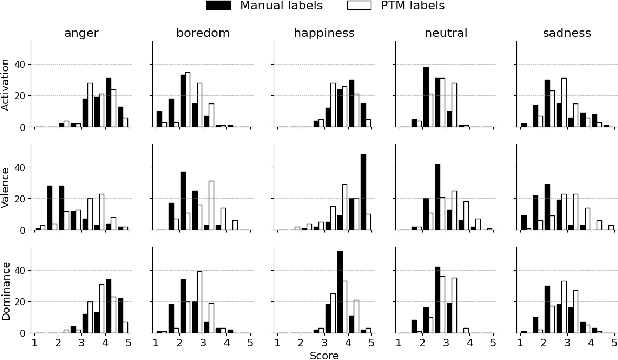
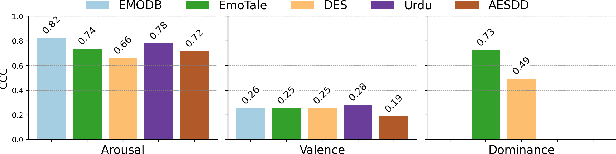
While multiple emotional speech corpora exist for commonly spoken languages, there is a lack of functional datasets for smaller (spoken) languages, such as Danish. To our knowledge, Danish Emotional Speech (DES), published in 1997, is the only other database of Danish emotional speech. We present EmoTale; a corpus comprising Danish and English speech recordings with their associated enacted emotion annotations. We demonstrate the validity of the dataset by investigating and presenting its predictive power using speech emotion recognition (SER) models. We develop SER models for EmoTale and the reference datasets using self-supervised speech model (SSLM) embeddings and the openSMILE feature extractor. We find the embeddings superior to the hand-crafted features. The best model achieves an unweighted average recall (UAR) of 64.1% on the EmoTale corpus using leave-one-speaker-out cross-validation, comparable to the performance on DES.
Exploring Local Interpretable Model-Agnostic Explanations for Speech Emotion Recognition with Distribution-Shift
Apr 07, 2025We introduce EmoLIME, a version of local interpretable model-agnostic explanations (LIME) for black-box Speech Emotion Recognition (SER) models. To the best of our knowledge, this is the first attempt to apply LIME in SER. EmoLIME generates high-level interpretable explanations and identifies which specific frequency ranges are most influential in determining emotional states. The approach aids in interpreting complex, high-dimensional embeddings such as those generated by end-to-end speech models. We evaluate EmoLIME, qualitatively, quantitatively, and statistically, across three emotional speech datasets, using classifiers trained on both hand-crafted acoustic features and Wav2Vec 2.0 embeddings. We find that EmoLIME exhibits stronger robustness across different models than across datasets with distribution shifts, highlighting its potential for more consistent explanations in SER tasks within a dataset.
On Crowdsourcing-design with Comparison Category Rating for Evaluating Speech Enhancement Algorithms
Jun 02, 2023



Speech enhancement techniques improve the quality or the intelligibility of an audio signal by removing unwanted noise. It is used as preprocessing in numerous applications such as speech recognition, hearing aids, broadcasting and telephony. The evaluation of such algorithms often relies on reference-based objective metrics that are shown to correlate poorly with human perception. In order to evaluate audio quality as perceived by human observers it is thus fundamental to resort to subjective quality assessment. In this paper, a user evaluation based on crowdsourcing (subjective) and the Comparison Category Rating (CCR) method is compared against the DNSMOS, ViSQOL and 3QUEST (objective) metrics. The overall quality scores of three speech enhancement algorithms from real time communications (RTC) are used in the comparison using the P.808 toolkit. Results indicate that while the CCR scale allows participants to identify differences between processed and unprocessed audio samples, two groups of preferences emerge: some users rate positively by focusing on noise suppression processing, while others rate negatively by focusing mainly on speech quality. We further present results on the parameters, size considerations and speaker variations that are critical and should be considered when designing the CCR-based crowdsourcing evaluation.
Continuous Metric Learning For Transferable Speech Emotion Recognition and Embedding Across Low-resource Languages
Mar 28, 2022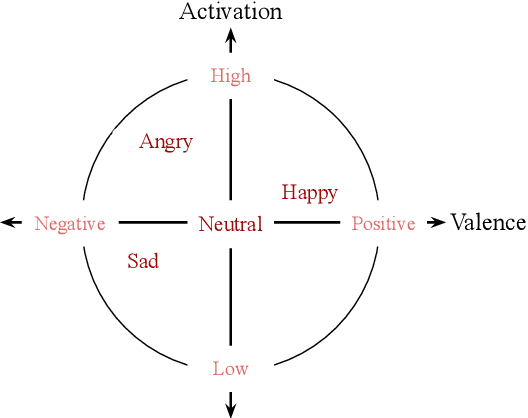

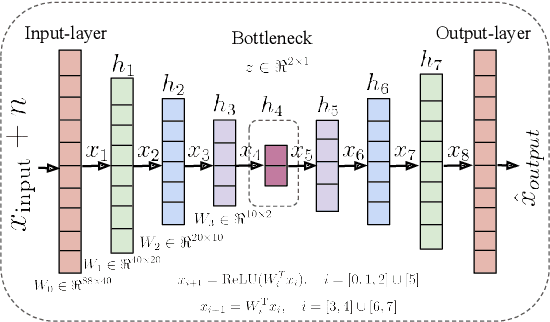

Speech emotion recognition~(SER) refers to the technique of inferring the emotional state of an individual from speech signals. SERs continue to garner interest due to their wide applicability. Although the domain is mainly founded on signal processing, machine learning, and deep learning, generalizing over languages continues to remain a challenge. However, developing generalizable and transferable models are critical due to a lack of sufficient resources in terms of data and labels for languages beyond the most commonly spoken ones. To improve performance over languages, we propose a denoising autoencoder with semi-supervision using a continuous metric loss based on either activation or valence. The novelty of this work lies in our proposal of continuous metric learning, which is among the first proposals on the topic to the best of our knowledge. Furthermore, to address the lack of activation and valence labels in the transfer datasets, we annotate the signal samples with activation and valence levels corresponding to a dimensional model of emotions, which were then used to evaluate the quality of the embedding over the transfer datasets. We show that the proposed semi-supervised model consistently outperforms the baseline unsupervised method, which is a conventional denoising autoencoder, in terms of emotion classification accuracy as well as correlation with respect to the dimensional variables. Further evaluation of classification accuracy with respect to the reference, a BERT based speech representation model, shows that the proposed method is comparable to the reference method in classifying specific emotion classes at a much lower complexity.
Towards Transferable Speech Emotion Representation: On loss functions for cross-lingual latent representations
Mar 28, 2022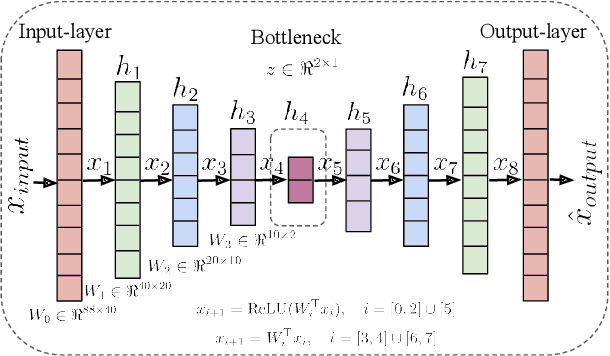

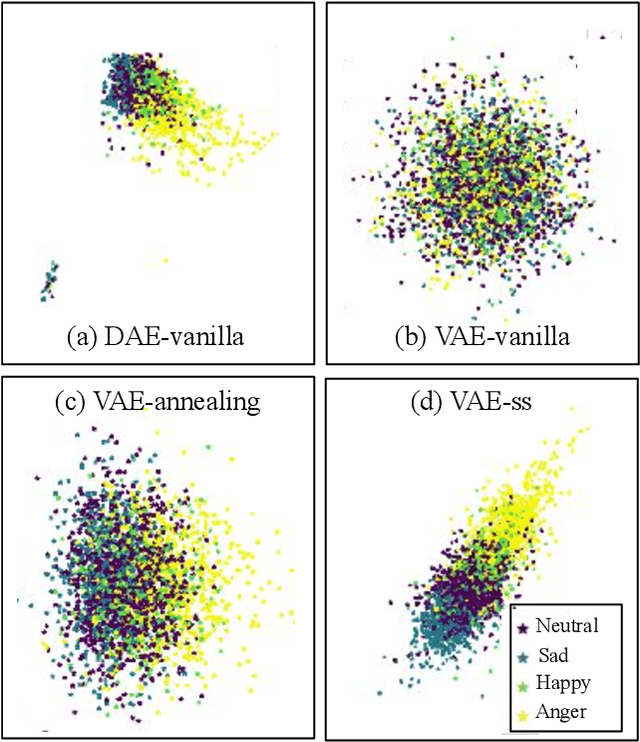
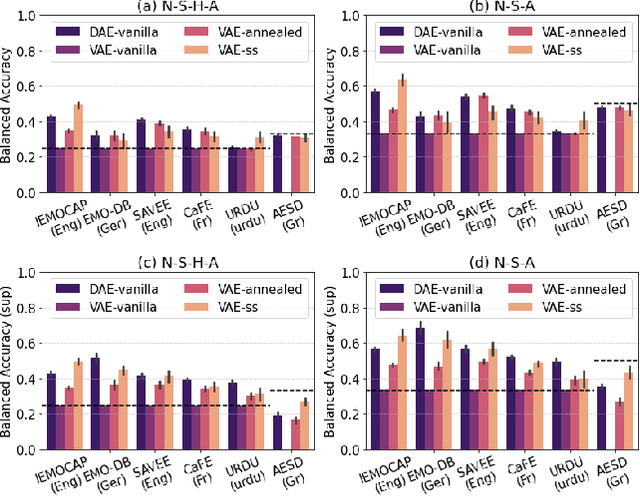
In recent years, speech emotion recognition (SER) has been used in wide ranging applications, from healthcare to the commercial sector. In addition to signal processing approaches, methods for SER now also use deep learning techniques which provide transfer learning possibilities. However, generalizing over languages, corpora and recording conditions is still an open challenge. In this work we address this gap by exploring loss functions that aid in transferability, specifically to non-tonal languages. We propose a variational autoencoder (VAE) with KL annealing and a semi-supervised VAE to obtain more consistent latent embedding distributions across data sets. To ensure transferability, the distribution of the latent embedding should be similar across non-tonal languages (data sets). We start by presenting a low-complexity SER based on a denoising-autoencoder, which achieves an unweighted classification accuracy of over 52.09% for four-class emotion classification. This performance is comparable to that of similar baseline methods. Following this, we employ a VAE, the semi-supervised VAE and the VAE with KL annealing to obtain a more regularized latent space. We show that while the DAE has the highest classification accuracy among the methods, the semi-supervised VAE has a comparable classification accuracy and a more consistent latent embedding distribution over data sets.
Data Representativity for Machine Learning and AI Systems
Mar 09, 2022
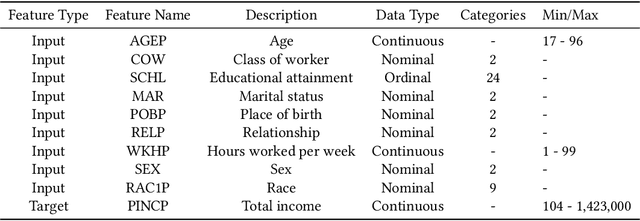
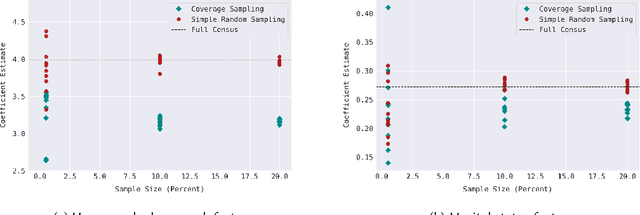

Data representativity is crucial when drawing inference from data through machine learning models. Scholars have increased focus on unraveling the bias and fairness in the models, also in relation to inherent biases in the input data. However, limited work exists on the representativity of samples (datasets) for appropriate inference in AI systems. This paper analyzes data representativity in scientific literature related to AI and sampling, and gives a brief overview of statistical sampling methodology from disciplines like sampling of physical materials, experimental design, survey analysis, and observational studies. Different notions of a 'representative sample' exist in past and present literature. In particular, the contrast between the notion of a representative sample in the sense of coverage of the input space, versus a representative sample as a miniature of the target population is of relevance when building AI systems. Using empirical demonstrations on US Census data, we demonstrate that the first is useful for providing equality and demographic parity, and is more robust to distribution shifts, whereas the latter notion is useful in situations where the purpose is to make historical inference or draw inference about the underlying population in general, or make better predictions for the majority in the underlying population. We propose a framework of questions for creating and documenting data, with data representativity in mind, as an addition to existing datasheets for datasets. Finally, we will also like to call for caution of implicit, in addition to explicit, use of a notion of data representativeness without specific clarification.
Towards Interpretable and Transferable Speech Emotion Recognition: Latent Representation Based Analysis of Features, Methods and Corpora
May 05, 2021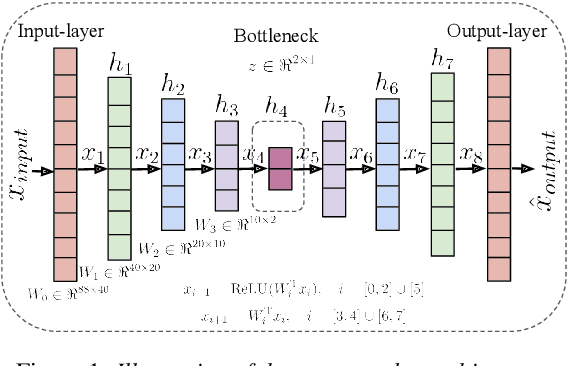
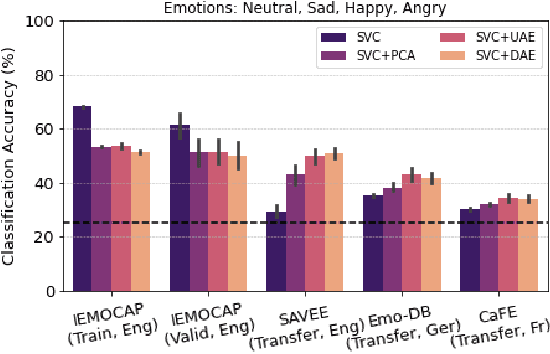
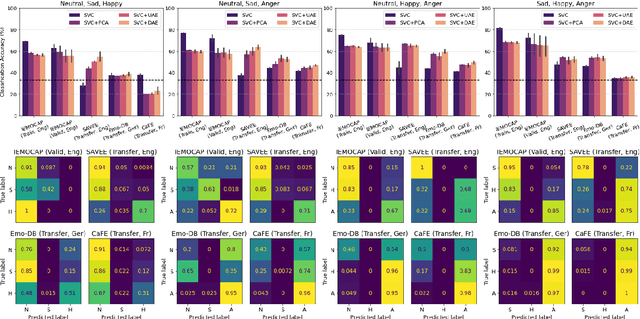
In recent years, speech emotion recognition (SER) has been used in wide ranging applications, from healthcare to the commercial sector. In addition to signal processing approaches, methods for SER now also use deep learning techniques. However, generalizing over languages, corpora and recording conditions is still an open challenge in the field. Furthermore, due to the black-box nature of deep learning algorithms, a newer challenge is the lack of interpretation and transparency in the models and the decision making process. This is critical when the SER systems are deployed in applications that influence human lives. In this work we address this gap by providing an in-depth analysis of the decision making process of the proposed SER system. Towards that end, we present low-complexity SER based on undercomplete- and denoising- autoencoders that achieve an average classification accuracy of over 55\% for four-class emotion classification. Following this, we investigate the clustering of emotions in the latent space to understand the influence of the corpora on the model behavior and to obtain a physical interpretation of the latent embedding. Lastly, we explore the role of each input feature towards the performance of the SER.
A generalized linear joint trained framework for semi-supervised leaning of sparse features
Jun 02, 2020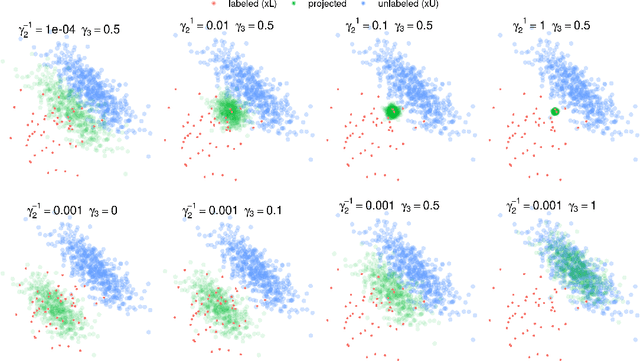
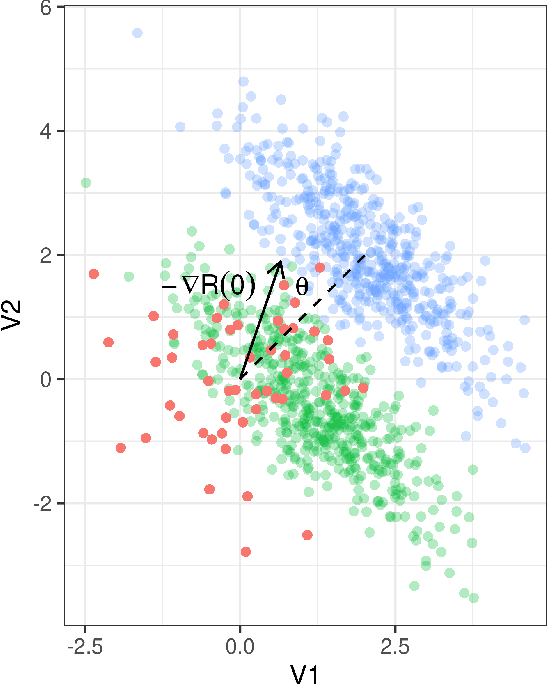
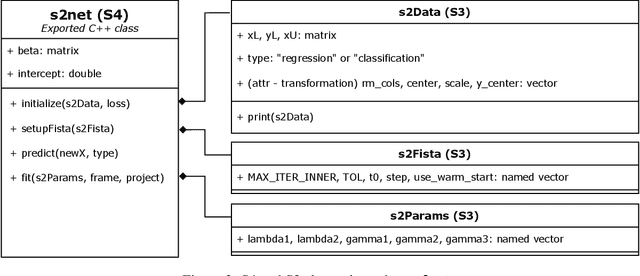

The elastic-net is among the most widely used types of regularization algorithms, commonly associated with the problem of supervised generalized linear model estimation via penalized maximum likelihood. Its nice properties originate from a combination of $\ell_1$ and $\ell_2$ norms, which endow this method with the ability to select variables taking into account the correlations between them. In the last few years, semi-supervised approaches, that use both labeled and unlabeled data, have become an important component in the statistical research. Despite this interest, however, few researches have investigated semi-supervised elastic-net extensions. This paper introduces a novel solution for semi-supervised learning of sparse features in the context of generalized linear model estimation: the generalized semi-supervised elastic-net (s2net), which extends the supervised elastic-net method, with a general mathematical formulation that covers, but is not limited to, both regression and classification problems. We develop a flexible and fast implementation for s2net in R, and its advantages are illustrated using both real and synthetic data sets.