 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Diet to Free Lunch: Estimating Auxiliary Signal Properties using Dynamic Pruning Masks in Speech Enhancement Networks
Feb 11, 2026Speech Enhancement (SE) in audio devices is often supported by auxiliary modules for Voice Activity Detection (VAD), SNR estimation, or Acoustic Scene Classification to ensure robust context-aware behavior and seamless user experience. Just like SE, these tasks often employ deep learning; however, deploying additional models on-device is computationally impractical, whereas cloud-based inference would introduce additional latency and compromise privacy. Prior work on SE employed Dynamic Channel Pruning (DynCP) to reduce computation by adaptively disabling specific channels based on the current input. In this work, we investigate whether useful signal properties can be estimated from these internal pruning masks, thus removing the need for separate models. We show that simple, interpretable predictors achieve up to 93% accuracy on VAD, 84% on noise classification, and an R2 of 0.86 on F0 estimation. With binary masks, predictions reduce to weighted sums, inducing negligible overhead. Our contribution is twofold: on one hand, we examine the emergent behavior of DynCP models through the lens of downstream prediction tasks, to reveal what they are learning; on the other, we repurpose and re-propose DynCP as a holistic solution for efficient SE and simultaneous estimation of signal properties.
Resource-Efficient Speech Quality Prediction through Quantization Aware Training and Binary Activation Maps
Jul 05, 2024

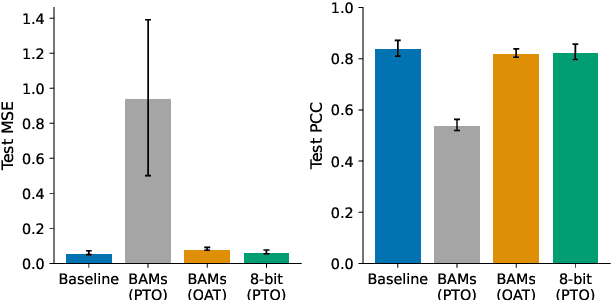

As speech processing systems in mobile and edge devices become more commonplace, the demand for unintrusive speech quality monitoring increases. Deep learning methods provide high-quality estimates of objective and subjective speech quality metrics. However, their significant computational requirements are often prohibitive on resource-constrained devices. To address this issue, we investigated binary activation maps (BAMs) for speech quality prediction on a convolutional architecture based on DNSMOS. We show that the binary activation model with quantization aware training matches the predictive performance of the baseline model. It further allows using other compression techniques. Combined with 8-bit weight quantization, our approach results in a 25-fold memory reduction during inference, while replacing almost all dot products with summations. Our findings show a path toward substantial resource savings by supporting mixed-precision binary multiplication in hard- and software.
Towards a tailored mixed-precision sub-8bit quantization scheme for Gated Recurrent Units using Genetic Algorithms
Feb 19, 2024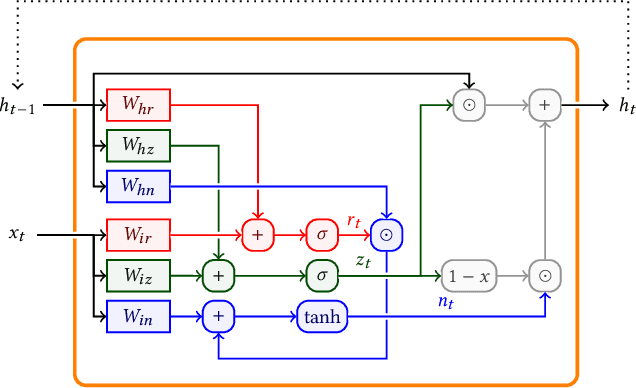
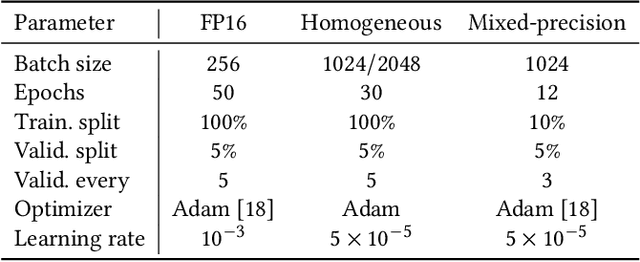
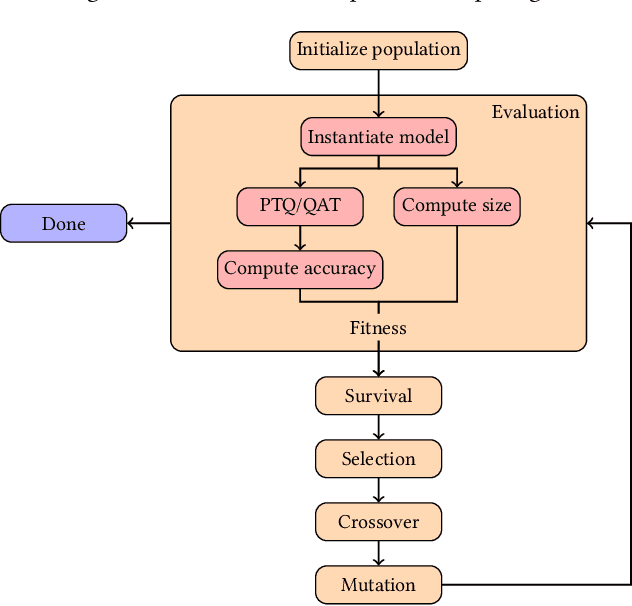
Despite the recent advances in model compression techniques for deep neural networks, deploying such models on ultra-low-power embedded devices still proves challenging. In particular, quantization schemes for Gated Recurrent Units (GRU) are difficult to tune due to their dependence on an internal state, preventing them from fully benefiting from sub-8bit quantization. In this work, we propose a modular integer quantization scheme for GRUs where the bit width of each operator can be selected independently. We then employ Genetic Algorithms (GA) to explore the vast search space of possible bit widths, simultaneously optimising for model size and accuracy. We evaluate our methods on four different sequential tasks and demonstrate that mixed-precision solutions exceed homogeneous-precision ones in terms of Pareto efficiency. In our results, we achieve a model size reduction between 25% and 55% while maintaining an accuracy comparable with the 8-bit homogeneous equivalent.
Dynamic nsNet2: Efficient Deep Noise Suppression with Early Exiting
Aug 31, 2023



Although deep learning has made strides in the field of deep noise suppression, leveraging deep architectures on resource-constrained devices still proved challenging. Therefore, we present an early-exiting model based on nsNet2 that provides several levels of accuracy and resource savings by halting computations at different stages. Moreover, we adapt the original architecture by splitting the information flow to take into account the injected dynamism. We show the trade-offs between performance and computational complexity based on established metrics.
On Crowdsourcing-design with Comparison Category Rating for Evaluating Speech Enhancement Algorithms
Jun 02, 2023



Speech enhancement techniques improve the quality or the intelligibility of an audio signal by removing unwanted noise. It is used as preprocessing in numerous applications such as speech recognition, hearing aids, broadcasting and telephony. The evaluation of such algorithms often relies on reference-based objective metrics that are shown to correlate poorly with human perception. In order to evaluate audio quality as perceived by human observers it is thus fundamental to resort to subjective quality assessment. In this paper, a user evaluation based on crowdsourcing (subjective) and the Comparison Category Rating (CCR) method is compared against the DNSMOS, ViSQOL and 3QUEST (objective) metrics. The overall quality scores of three speech enhancement algorithms from real time communications (RTC) are used in the comparison using the P.808 toolkit. Results indicate that while the CCR scale allows participants to identify differences between processed and unprocessed audio samples, two groups of preferences emerge: some users rate positively by focusing on noise suppression processing, while others rate negatively by focusing mainly on speech quality. We further present results on the parameters, size considerations and speaker variations that are critical and should be considered when designing the CCR-based crowdsourcing evaluation.