 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Speech Enhancement with Dynamic Channel Pruning
Dec 22, 2024Speech Enhancement (SE) is essential for improving productivity in remote collaborative environments. Although deep learning models are highly effective at SE, their computational demands make them impractical for embedded systems. Furthermore, acoustic conditions can change significantly in terms of difficulty, whereas neural networks are usually static with regard to the amount of computation performed. To this end, we introduce Dynamic Channel Pruning to the audio domain for the first time and apply it to a custom convolutional architecture for SE. Our approach works by identifying unnecessary convolutional channels at runtime and saving computational resources by not computing the activations for these channels and retrieving their filters. When trained to only use 25% of channels, we save 29.6% of MACs while only causing a 0.75% drop in PESQ. Thus, DynCP offers a promising path toward deploying larger and more powerful SE solutions on resource-constrained devices.
Towards a tailored mixed-precision sub-8bit quantization scheme for Gated Recurrent Units using Genetic Algorithms
Feb 19, 2024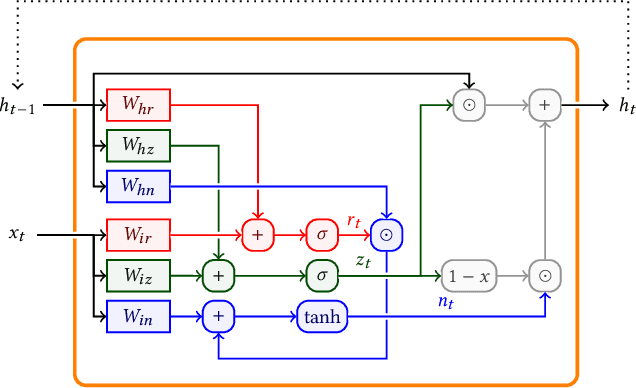
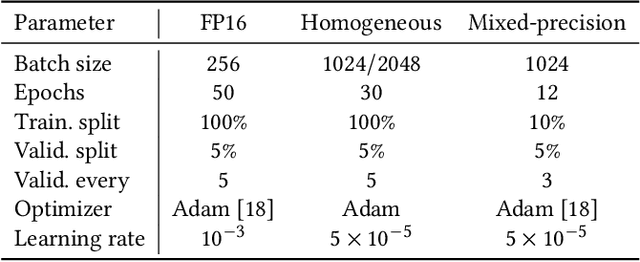
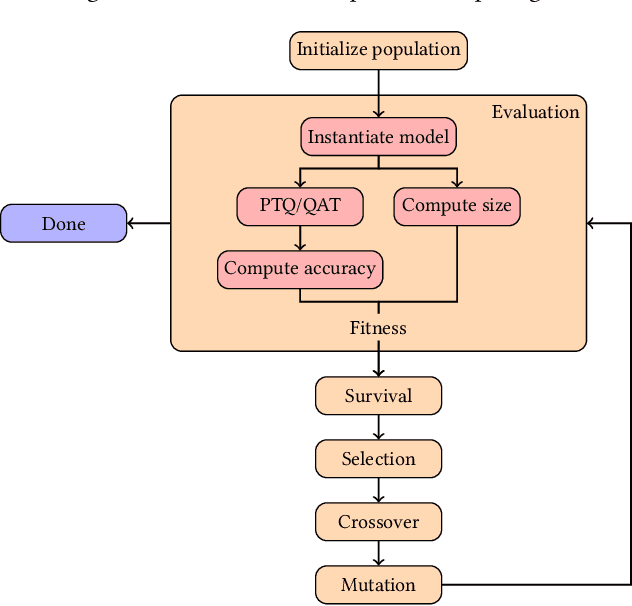
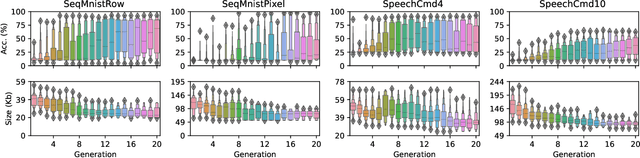
Despite the recent advances in model compression techniques for deep neural networks, deploying such models on ultra-low-power embedded devices still proves challenging. In particular, quantization schemes for Gated Recurrent Units (GRU) are difficult to tune due to their dependence on an internal state, preventing them from fully benefiting from sub-8bit quantization. In this work, we propose a modular integer quantization scheme for GRUs where the bit width of each operator can be selected independently. We then employ Genetic Algorithms (GA) to explore the vast search space of possible bit widths, simultaneously optimising for model size and accuracy. We evaluate our methods on four different sequential tasks and demonstrate that mixed-precision solutions exceed homogeneous-precision ones in terms of Pareto efficiency. In our results, we achieve a model size reduction between 25% and 55% while maintaining an accuracy comparable with the 8-bit homogeneous equivalent.
Dynamic nsNet2: Efficient Deep Noise Suppression with Early Exiting
Aug 31, 2023



Although deep learning has made strides in the field of deep noise suppression, leveraging deep architectures on resource-constrained devices still proved challenging. Therefore, we present an early-exiting model based on nsNet2 that provides several levels of accuracy and resource savings by halting computations at different stages. Moreover, we adapt the original architecture by splitting the information flow to take into account the injected dynamism. We show the trade-offs between performance and computational complexity based on established metrics.