 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a tailored mixed-precision sub-8bit quantization scheme for Gated Recurrent Units using Genetic Algorithms
Feb 19, 2024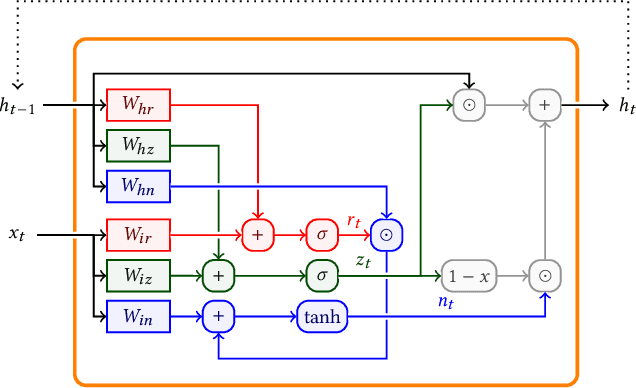
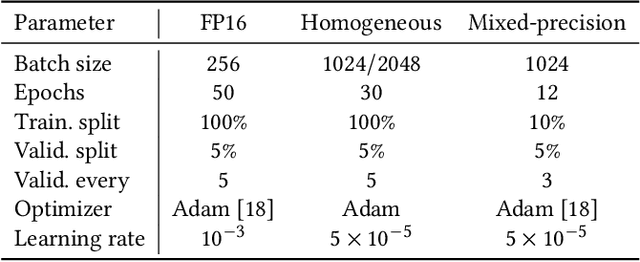
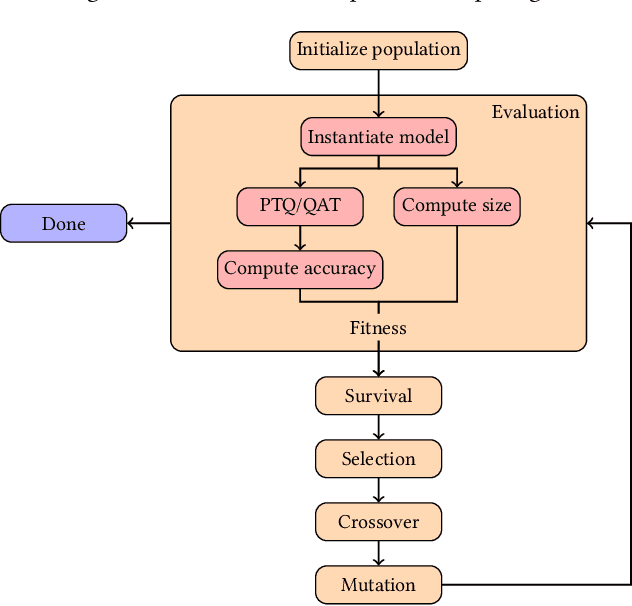
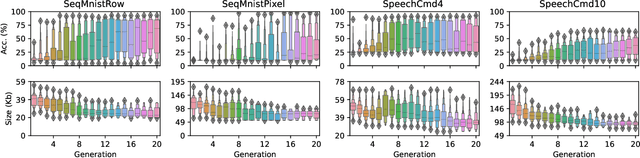
Despite the recent advances in model compression techniques for deep neural networks, deploying such models on ultra-low-power embedded devices still proves challenging. In particular, quantization schemes for Gated Recurrent Units (GRU) are difficult to tune due to their dependence on an internal state, preventing them from fully benefiting from sub-8bit quantization. In this work, we propose a modular integer quantization scheme for GRUs where the bit width of each operator can be selected independently. We then employ Genetic Algorithms (GA) to explore the vast search space of possible bit widths, simultaneously optimising for model size and accuracy. We evaluate our methods on four different sequential tasks and demonstrate that mixed-precision solutions exceed homogeneous-precision ones in terms of Pareto efficiency. In our results, we achieve a model size reduction between 25% and 55% while maintaining an accuracy comparable with the 8-bit homogeneous equivalent.