 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Self-Supervised Learning via Latent Distribution Matching
May 05, 2026Self-supervised learning (SSL) excels at finding general-purpose latent representations from complex data, yet lacks a unifying theoretical framework that explains the diverse existing methods and guides the design of new ones. We cast SSL as latent distribution matching (LDM): learning representations that maximize their log-probability under an assumed latent model (alignment), while maximizing latent entropy to prevent collapse (uniformity). This view unifies independent component analysis with contrastive, non-contrastive, and predictive SSL methods, including stop gradient approaches. Leveraging LDM, we derive a nonlinear, sampling-free Bayesian filtering model with a Kalman-based predictor for high-dimensional timeseries. We further prove that predictive LDM yields identifiable latent representations under mild assumptions, even with nonlinear predictors. Overall, LDM clarifies the assumptions behind established SSL methods and provides principled guidance for developing new approaches.
Teaching signal synchronization in deep neural networks with prospective neurons
Nov 18, 2025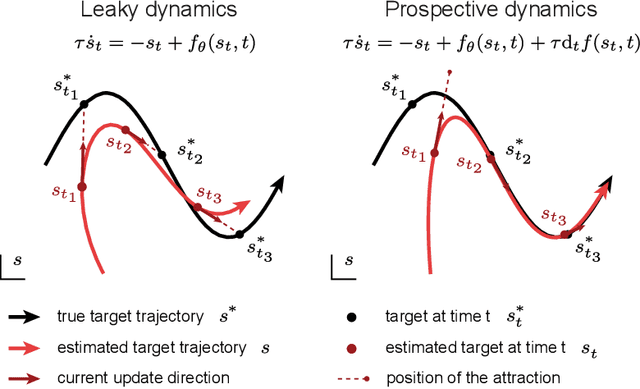
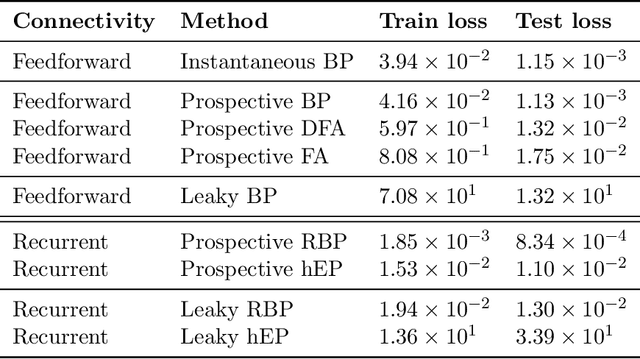
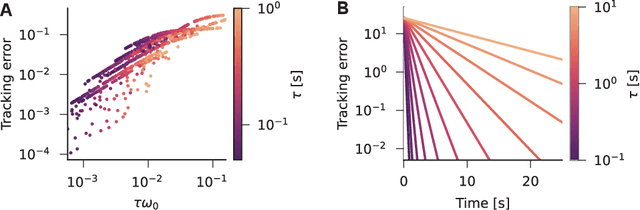
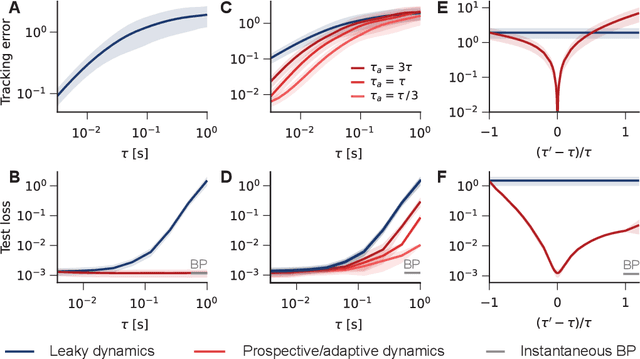
Working memory requires the brain to maintain information from the recent past to guide ongoing behavior. Neurons can contribute to this capacity by slowly integrating their inputs over time, creating persistent activity that outlasts the original stimulus. However, when these slowly integrating neurons are organized hierarchically, they introduce cumulative delays that create a fundamental challenge for learning: teaching signals that indicate whether behavior was correct or incorrect arrive out-of-sync with the neural activity they are meant to instruct. Here, we demonstrate that neurons enhanced with an adaptive current can compensate for these delays by responding to external stimuli prospectively -- effectively predicting future inputs to synchronize with them. First, we show that such prospective neurons enable teaching signal synchronization across a range of learning algorithms that propagate error signals through hierarchical networks. Second, we demonstrate that this successfully guides learning in slowly integrating neurons, enabling the formation and retrieval of memories over extended timescales. We support our findings with a mathematical analysis of the prospective coding mechanism and learning experiments on motor control tasks. Together, our results reveal how neural adaptation could solve a critical timing problem and enable efficient learning in dynamic environments.
Decoding finger velocity from cortical spike trains with recurrent spiking neural networks
Sep 03, 2024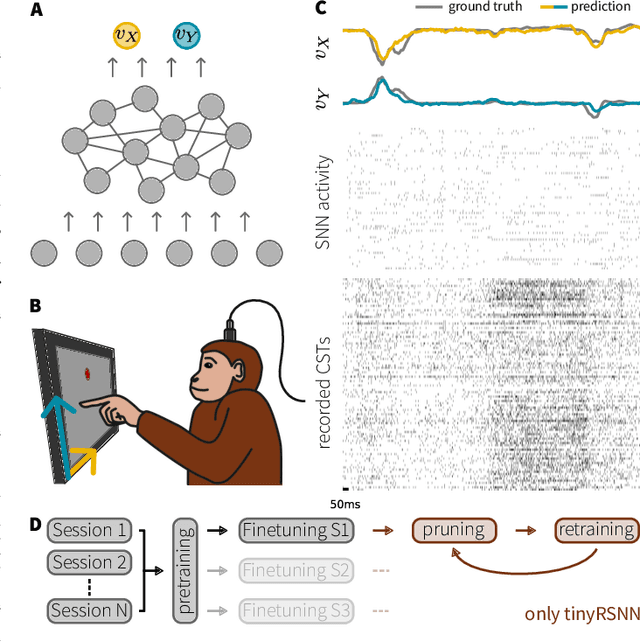
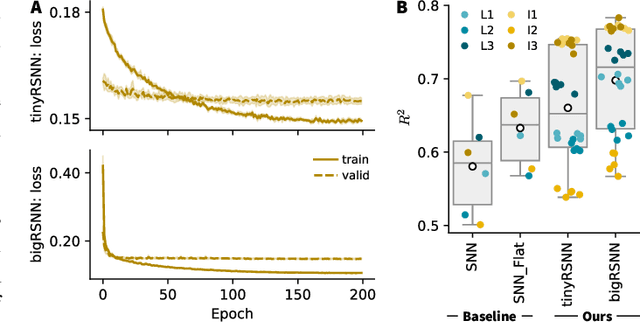
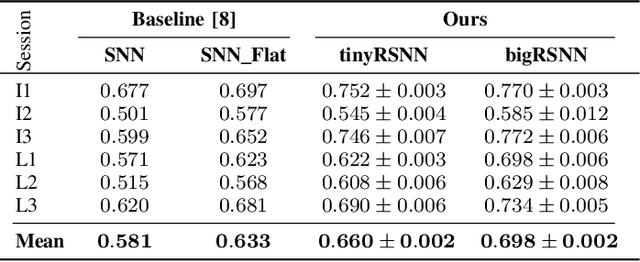
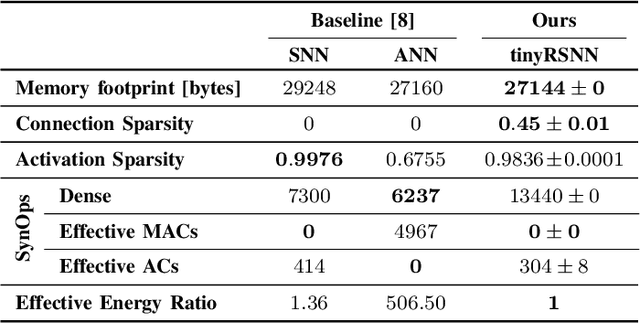
Invasive cortical brain-machine interfaces (BMIs) can significantly improve the life quality of motor-impaired patients. Nonetheless, externally mounted pedestals pose an infection risk, which calls for fully implanted systems. Such systems, however, must meet strict latency and energy constraints while providing reliable decoding performance. While recurrent spiking neural networks (RSNNs) are ideally suited for ultra-low-power, low-latency processing on neuromorphic hardware, it is unclear whether they meet the above requirements. To address this question, we trained RSNNs to decode finger velocity from cortical spike trains (CSTs) of two macaque monkeys. First, we found that a large RSNN model outperformed existing feedforward spiking neural networks (SNNs) and artificial neural networks (ANNs) in terms of their decoding accuracy. We next developed a tiny RSNN with a smaller memory footprint, low firing rates, and sparse connectivity. Despite its reduced computational requirements, the resulting model performed substantially better than existing SNN and ANN decoders. Our results thus demonstrate that RSNNs offer competitive CST decoding performance under tight resource constraints and are promising candidates for fully implanted ultra-low-power BMIs with the potential to revolutionize patient care.
Resource-Efficient Speech Quality Prediction through Quantization Aware Training and Binary Activation Maps
Jul 05, 2024

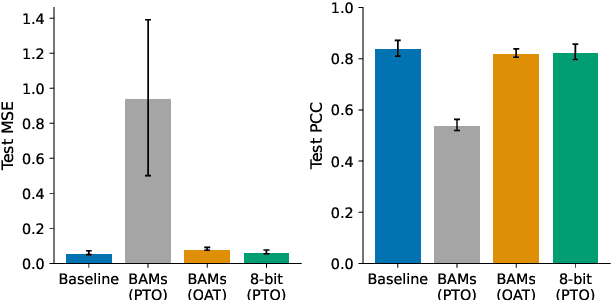

As speech processing systems in mobile and edge devices become more commonplace, the demand for unintrusive speech quality monitoring increases. Deep learning methods provide high-quality estimates of objective and subjective speech quality metrics. However, their significant computational requirements are often prohibitive on resource-constrained devices. To address this issue, we investigated binary activation maps (BAMs) for speech quality prediction on a convolutional architecture based on DNSMOS. We show that the binary activation model with quantization aware training matches the predictive performance of the baseline model. It further allows using other compression techniques. Combined with 8-bit weight quantization, our approach results in a 25-fold memory reduction during inference, while replacing almost all dot products with summations. Our findings show a path toward substantial resource savings by supporting mixed-precision binary multiplication in hard- and software.
Theories of synaptic memory consolidation and intelligent plasticity for continual learning
May 27, 2024Humans and animals learn throughout life. Such continual learning is crucial for intelligence. In this chapter, we examine the pivotal role plasticity mechanisms with complex internal synaptic dynamics could play in enabling this ability in neural networks. By surveying theoretical research, we highlight two fundamental enablers for continual learning. First, synaptic plasticity mechanisms must maintain and evolve an internal state over several behaviorally relevant timescales. Second, plasticity algorithms must leverage the internal state to intelligently regulate plasticity at individual synapses to facilitate the seamless integration of new memories while avoiding detrimental interference with existing ones. Our chapter covers successful applications of these principles to deep neural networks and underscores the significance of synaptic metaplasticity in sustaining continual learning capabilities. Finally, we outline avenues for further research to understand the brain's superb continual learning abilities and harness similar mechanisms for artificial intelligence systems.
Elucidating the theoretical underpinnings of surrogate gradient learning in spiking neural networks
Apr 23, 2024Training spiking neural networks to approximate complex functions is essential for studying information processing in the brain and neuromorphic computing. Yet, the binary nature of spikes constitutes a challenge for direct gradient-based training. To sidestep this problem, surrogate gradients have proven empirically successful, but their theoretical foundation remains elusive. Here, we investigate the relation of surrogate gradients to two theoretically well-founded approaches. On the one hand, we consider smoothed probabilistic models, which, due to lack of support for automatic differentiation, are impractical for training deep spiking neural networks, yet provide gradients equivalent to surrogate gradients in single neurons. On the other hand, we examine stochastic automatic differentiation, which is compatible with discrete randomness but has never been applied to spiking neural network training. We find that the latter provides the missing theoretical basis for surrogate gradients in stochastic spiking neural networks. We further show that surrogate gradients in deterministic networks correspond to a particular asymptotic case and numerically confirm the effectiveness of surrogate gradients in stochastic multi-layer spiking neural networks. Finally, we illustrate that surrogate gradients are not conservative fields and, thus, not gradients of a surrogate loss. Our work provides the missing theoretical foundation for surrogate gradients and an analytically well-founded solution for end-to-end training of stochastic spiking neural networks.
Dis-inhibitory neuronal circuits can control the sign of synaptic plasticity
Oct 30, 2023
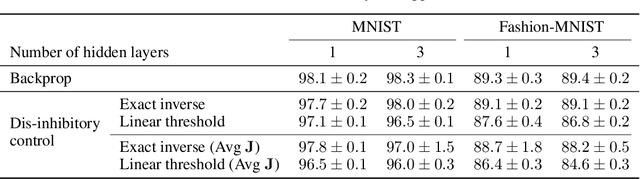
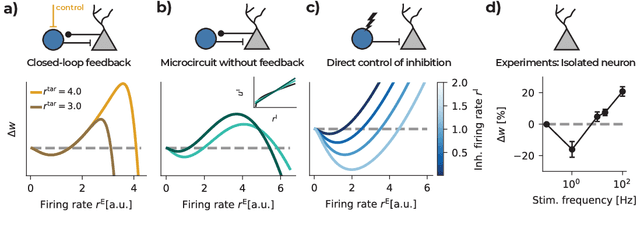

How neuronal circuits achieve credit assignment remains a central unsolved question in systems neuroscience. Various studies have suggested plausible solutions for back-propagating error signals through multi-layer networks. These purely functionally motivated models assume distinct neuronal compartments to represent local error signals that determine the sign of synaptic plasticity. However, this explicit error modulation is inconsistent with phenomenological plasticity models in which the sign depends primarily on postsynaptic activity. Here we show how a plausible microcircuit model and Hebbian learning rule derived within an adaptive control theory framework can resolve this discrepancy. Assuming errors are encoded in top-down dis-inhibitory synaptic afferents, we show that error-modulated learning emerges naturally at the circuit level when recurrent inhibition explicitly influences Hebbian plasticity. The same learning rule accounts for experimentally observed plasticity in the absence of inhibition and performs comparably to back-propagation of error (BP) on several non-linearly separable benchmarks. Our findings bridge the gap between functional and experimentally observed plasticity rules and make concrete predictions on inhibitory modulation of excitatory plasticity.
Improving equilibrium propagation without weight symmetry through Jacobian homeostasis
Sep 05, 2023Equilibrium propagation (EP) is a compelling alternative to the backpropagation of error algorithm (BP) for computing gradients of neural networks on biological or analog neuromorphic substrates. Still, the algorithm requires weight symmetry and infinitesimal equilibrium perturbations, i.e., nudges, to estimate unbiased gradients efficiently. Both requirements are challenging to implement in physical systems. Yet, whether and how weight asymmetry affects its applicability is unknown because, in practice, it may be masked by biases introduced through the finite nudge. To address this question, we study generalized EP, which can be formulated without weight symmetry, and analytically isolate the two sources of bias. For complex-differentiable non-symmetric networks, we show that the finite nudge does not pose a problem, as exact derivatives can still be estimated via a Cauchy integral. In contrast, weight asymmetry introduces bias resulting in low task performance due to poor alignment of EP's neuronal error vectors compared to BP. To mitigate this issue, we present a new homeostatic objective that directly penalizes functional asymmetries of the Jacobian at the network's fixed point. This homeostatic objective dramatically improves the network's ability to solve complex tasks such as ImageNet 32x32. Our results lay the theoretical groundwork for studying and mitigating the adverse effects of imperfections of physical networks on learning algorithms that rely on the substrate's relaxation dynamics.
Predictor networks and stop-grads provide implicit variance regularization in BYOL/SimSiam
Dec 09, 2022Self-supervised learning (SSL) learns useful representations from unlabelled data by training networks to be invariant to pairs of augmented versions of the same input. Non-contrastive methods avoid collapse either by directly regularizing the covariance matrix of network outputs or through asymmetric loss architectures, two seemingly unrelated approaches. Here, by building on DirectPred, we lay out a theoretical framework that reconciles these two views. We derive analytical expressions for the representational learning dynamics in linear networks. By expressing them in the eigenspace of the embedding covariance matrix, where the solutions decouple, we reveal the mechanism and conditions that provide implicit variance regularization. These insights allow us to formulate a new isotropic loss function that equalizes eigenvalue contribution and renders learning more robust. Finally, we show empirically that our findings translate to nonlinear networks trained on CIFAR-10 and STL-10.
Fluctuation-driven initialization for spiking neural network training
Jun 21, 2022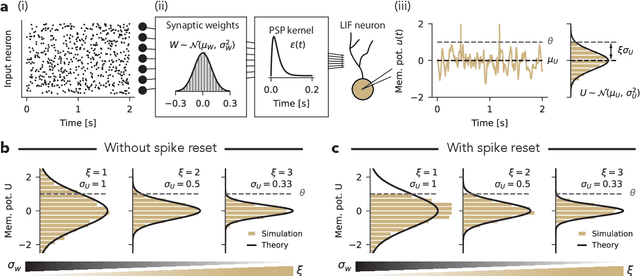


Spiking neural networks (SNNs) underlie low-power, fault-tolerant information processing in the brain and could constitute a power-efficient alternative to conventional deep neural networks when implemented on suitable neuromorphic hardware accelerators. However, instantiating SNNs that solve complex computational tasks in-silico remains a significant challenge. Surrogate gradient (SG) techniques have emerged as a standard solution for training SNNs end-to-end. Still, their success depends on synaptic weight initialization, similar to conventional artificial neural networks (ANNs). Yet, unlike in the case of ANNs, it remains elusive what constitutes a good initial state for an SNN. Here, we develop a general initialization strategy for SNNs inspired by the fluctuation-driven regime commonly observed in the brain. Specifically, we derive practical solutions for data-dependent weight initialization that ensure fluctuation-driven firing in the widely used leaky integrate-and-fire (LIF) neurons. We empirically show that SNNs initialized following our strategy exhibit superior learning performance when trained with SGs. These findings generalize across several datasets and SNN architectures, including fully connected, deep convolutional, recurrent, and more biologically plausible SNNs obeying Dale's law. Thus fluctuation-driven initialization provides a practical, versatile, and easy-to-implement strategy for improving SNN training performance on diverse tasks in neuromorphic engineering and computational neuroscience.