 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETLP: Event-based Three-factor Local Plasticity for online learning with neuromorphic hardware
Jan 24, 2023Neuromorphic perception with event-based sensors, asynchronous hardware and spiking neurons is showing promising results for real-time and energy-efficient inference in embedded systems. The next promise of brain-inspired computing is to enable adaptation to changes at the edge with online learning. However, the parallel and distributed architectures of neuromorphic hardware based on co-localized compute and memory imposes locality constraints to the on-chip learning rules. We propose in this work the Event-based Three-factor Local Plasticity (ETLP) rule that uses (1) the pre-synaptic spike trace, (2) the post-synaptic membrane voltage and (3) a third factor in the form of projected labels with no error calculation, that also serve as update triggers. We apply ETLP with feedforward and recurrent spiking neural networks on visual and auditory event-based pattern recognition, and compare it to Back-Propagation Through Time (BPTT) and eProp. We show a competitive performance in accuracy with a clear advantage in the computational complexity for ETLP. We also show that when using local plasticity, threshold adaptation in spiking neurons and a recurrent topology are necessary to learn spatio-temporal patterns with a rich temporal structure. Finally, we provide a proof of concept hardware implementation of ETLP on FPGA to highlight the simplicity of its computational primitives and how they can be mapped into neuromorphic hardware for online learning with low-energy consumption and real-time interaction.
On-Chip Error-triggered Learning of Multi-layer Memristive Spiking Neural Networks
Nov 21, 2020
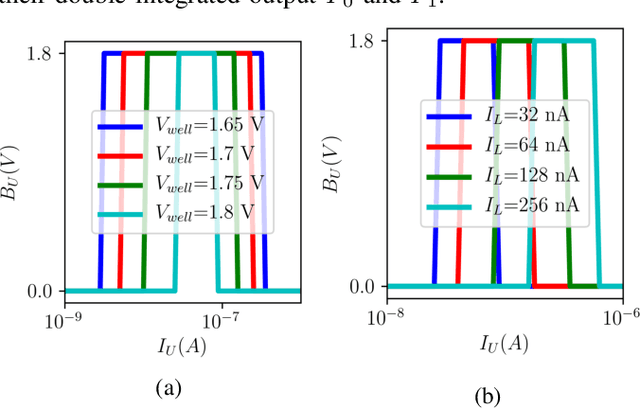
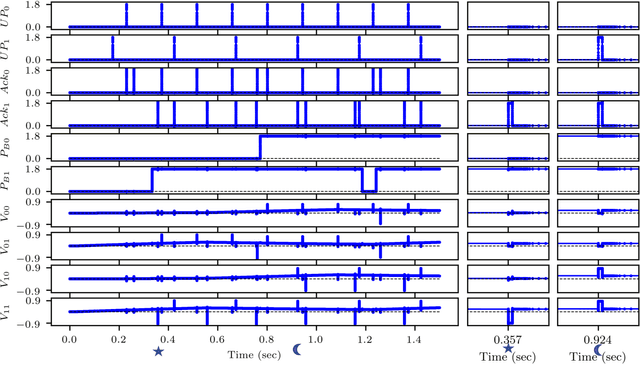
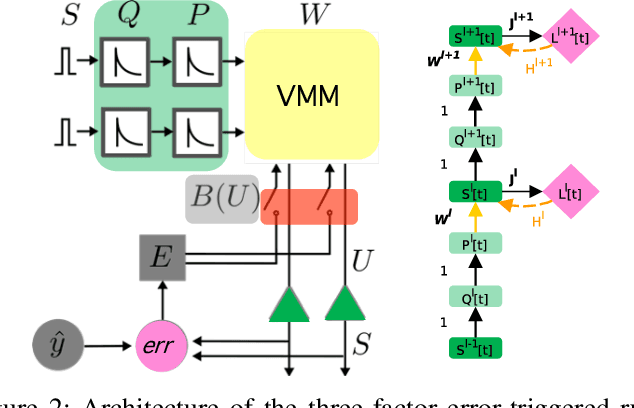
Recent breakthroughs in neuromorphic computing show that local forms of gradient descent learning are compatible with Spiking Neural Networks (SNNs) and synaptic plasticity. Although SNNs can be scalably implemented using neuromorphic VLSI, an architecture that can learn using gradient-descent in situ is still missing. In this paper, we propose a local, gradient-based, error-triggered learning algorithm with online ternary weight updates. The proposed algorithm enables online training of multi-layer SNNs with memristive neuromorphic hardware showing a small loss in the performance compared with the state of the art. We also propose a hardware architecture based on memristive crossbar arrays to perform the required vector-matrix multiplications. The necessary peripheral circuitry including pre-synaptic, post-synaptic and write circuits required for online training, have been designed in the sub-threshold regime for power saving with a standard 180 nm CMOS process.
Brain-Inspired Learning on Neuromorphic Substrates
Oct 22, 2020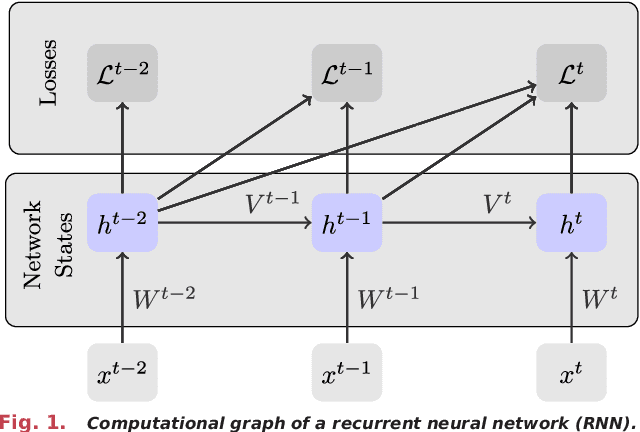
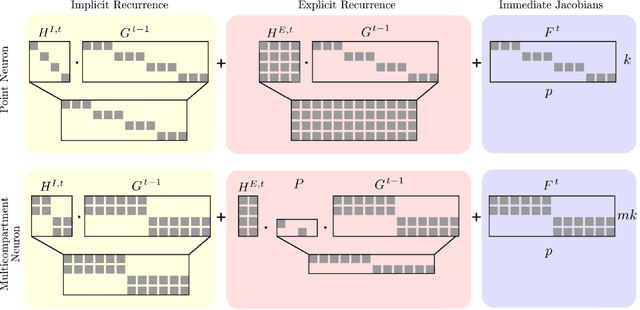
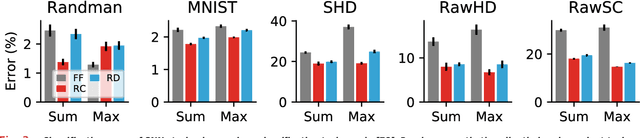
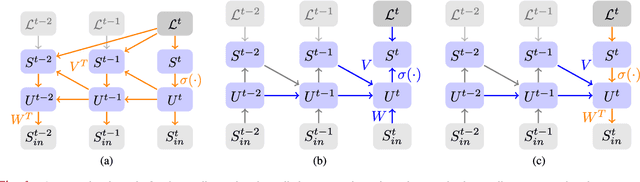
Neuromorphic hardware strives to emulate brain-like neural networks and thus holds the promise for scalable, low-power information processing on temporal data streams. Yet, to solve real-world problems, these networks need to be trained. However, training on neuromorphic substrates creates significant challenges due to the offline character and the required non-local computations of gradient-based learning algorithms. This article provides a mathematical framework for the design of practical online learning algorithms for neuromorphic substrates. Specifically, we show a direct connection between Real-Time Recurrent Learning (RTRL), an online algorithm for computing gradients in conventional Recurrent Neural Networks (RNNs), and biologically plausible learning rules for training Spiking Neural Networks (SNNs). Further, we motivate a sparse approximation based on block-diagonal Jacobians, which reduces the algorithm's computational complexity, diminishes the non-local information requirements, and empirically leads to good learning performance, thereby improving its applicability to neuromorphic substrates. In summary, our framework bridges the gap between synaptic plasticity and gradient-based approaches from deep learning and lays the foundations for powerful information processing on future neuromorphic hardware systems.
Surrogate Gradient Learning in Spiking Neural Networks
Jan 28, 2019

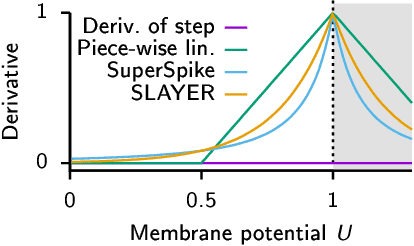
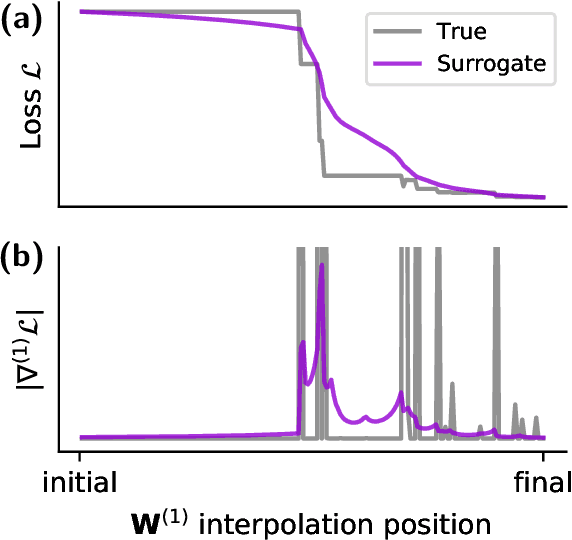
A growing number of neuromorphic spiking neural network processors that emulate biological neural networks create an imminent need for methods and tools to enable them to solve real-world signal processing problems. Like conventional neural networks, spiking neural networks are particularly efficient when trained on real, domain specific data. However, their training requires overcoming a number of challenges linked to their binary and dynamical nature. This tutorial elucidates step-by-step the problems typically encountered when training spiking neural networks, and guides the reader through the key concepts of synaptic plasticity and data-driven learning in the spiking setting. To that end, it gives an overview of existing approaches and provides an introduction to surrogate gradient methods, specifically, as a particularly flexible and efficient method to overcome the aforementioned challenges.
Stochastic Synapses Enable Efficient Brain-Inspired Learning Machines
Dec 15, 2016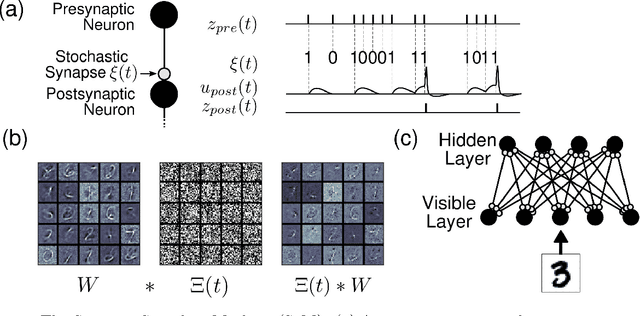
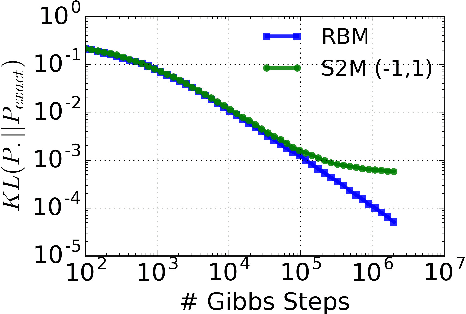
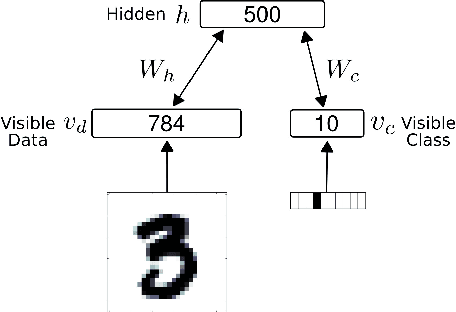
Recent studies have shown that synaptic unreliability is a robust and sufficient mechanism for inducing the stochasticity observed in cortex. Here, we introduce Synaptic Sampling Machines, a class of neural network models that uses synaptic stochasticity as a means to Monte Carlo sampling and unsupervised learning. Similar to the original formulation of Boltzmann machines, these models can be viewed as a stochastic counterpart of Hopfield networks, but where stochasticity is induced by a random mask over the connections. Synaptic stochasticity plays the dual role of an efficient mechanism for sampling, and a regularizer during learning akin to DropConnect. A local synaptic plasticity rule implementing an event-driven form of contrastive divergence enables the learning of generative models in an on-line fashion. Synaptic sampling machines perform equally well using discrete-timed artificial units (as in Hopfield networks) or continuous-timed leaky integrate & fire neurons. The learned representations are remarkably sparse and robust to reductions in bit precision and synapse pruning: removal of more than 75% of the weakest connections followed by cursory re-learning causes a negligible performance loss on benchmark classification tasks. The spiking neuron-based synaptic sampling machines outperform existing spike-based unsupervised learners, while potentially offering substantial advantages in terms of power and complexity, and are thus promising models for on-line learning in brain-inspired hardware.