 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Linear Implementation of an Analog Resonate-and-Fire Neuron
Nov 15, 2025Oscillatory dynamics have recently proven highly effective in machine learning (ML), particularly through State-Space-Models (SSM) that leverage structured linear recurrences for long-range temporal processing. Resonate-and-Fire neurons capture such oscillatory behavior in a spiking framework, offering strong expressivity with sparse event-based communication. While early analog RAF circuits employed nonlinear coupling and suffered from process sensitivity, modern ML practice favors linear recurrence. In this work, we introduce a resonate-and-fire (RAF) neuron, built in 22nm Fully-Depleted Silicon-on-Insulator technology, that aligns with SSM principles while retaining the efficiency of spike-based communication. We analyze its dynamics, linearity, and resilience to Process, Voltage, and Temperature variations, and evaluate its power, performance, and area trade-offs. We map the characteristics of our circuit into a system-level simulation where our RAF neuron is utilized in a keyword-spotting task, showing that its non-idealities do not hinder performance. Our results establish RAF neurons as robust, energy-efficient computational primitives for neuromorphic hardware.
mGRADE: Minimal Recurrent Gating Meets Delay Convolutions for Lightweight Sequence Modeling
Jul 02, 2025Edge devices for temporal processing demand models that capture both short- and long- range dynamics under tight memory constraints. While Transformers excel at sequence modeling, their quadratic memory scaling with sequence length makes them impractical for such settings. Recurrent Neural Networks (RNNs) offer constant memory but train sequentially, and Temporal Convolutional Networks (TCNs), though efficient, scale memory with kernel size. To address this, we propose mGRADE (mininally Gated Recurrent Architecture with Delay Embedding), a hybrid-memory system that integrates a temporal 1D-convolution with learnable spacings followed by a minimal gated recurrent unit (minGRU). This design allows the convolutional layer to realize a flexible delay embedding that captures rapid temporal variations, while the recurrent module efficiently maintains global context with minimal memory overhead. We validate our approach on two synthetic tasks, demonstrating that mGRADE effectively separates and preserves multi-scale temporal features. Furthermore, on challenging pixel-by-pixel image classification benchmarks, mGRADE consistently outperforms both pure convolutional and pure recurrent counterparts using approximately 20% less memory footprint, highlighting its suitability for memory-constrained temporal processing at the edge. This highlights mGRADE's promise as an efficient solution for memory-constrained multi-scale temporal processing at the edge.
Quantizing Small-Scale State-Space Models for Edge AI
Jun 14, 2025State-space models (SSMs) have recently gained attention in deep learning for their ability to efficiently model long-range dependencies, making them promising candidates for edge-AI applications. In this paper, we analyze the effects of quantization on small-scale SSMs with a focus on reducing memory and computational costs while maintaining task performance. Using the S4D architecture, we first investigate post-training quantization (PTQ) and show that the state matrix A and internal state x are particularly sensitive to quantization. Furthermore, we analyze the impact of different quantization techniques applied to the parameters and activations in the S4D architecture. To address the observed performance drop after Post-training Quantization (PTQ), we apply Quantization-aware Training (QAT), significantly improving performance from 40% (PTQ) to 96% on the sequential MNIST benchmark at 8-bit precision. We further demonstrate the potential of QAT in enabling sub-8-bit precisions and evaluate different parameterization schemes for QAT stability. Additionally, we propose a heterogeneous quantization strategy that assigns different precision levels to model components, reducing the overall memory footprint by a factor of 6x without sacrificing performance. Our results provide actionable insights for deploying quantized SSMs in resource-constrained environments.
MINIMALIST: switched-capacitor circuits for efficient in-memory computation of gated recurrent units
May 13, 2025

Recurrent neural networks (RNNs) have been a long-standing candidate for processing of temporal sequence data, especially in memory-constrained systems that one may find in embedded edge computing environments. Recent advances in training paradigms have now inspired new generations of efficient RNNs. We introduce a streamlined and hardware-compatible architecture based on minimal gated recurrent units (GRUs), and an accompanying efficient mixed-signal hardware implementation of the model. The proposed design leverages switched-capacitor circuits not only for in-memory computation (IMC), but also for the gated state updates. The mixed-signal cores rely solely on commodity circuits consisting of metal capacitors, transmission gates, and a clocked comparator, thus greatly facilitating scaling and transfer to other technology nodes. We benchmark the performance of our architecture on time series data, introducing all constraints required for a direct mapping to the hardware system. The direct compatibility is verified in mixed-signal simulations, reproducing data recorded from the software-only network model.
The Role of Temporal Hierarchy in Spiking Neural Networks
Jul 26, 2024
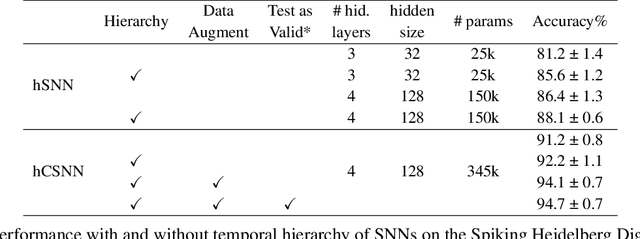
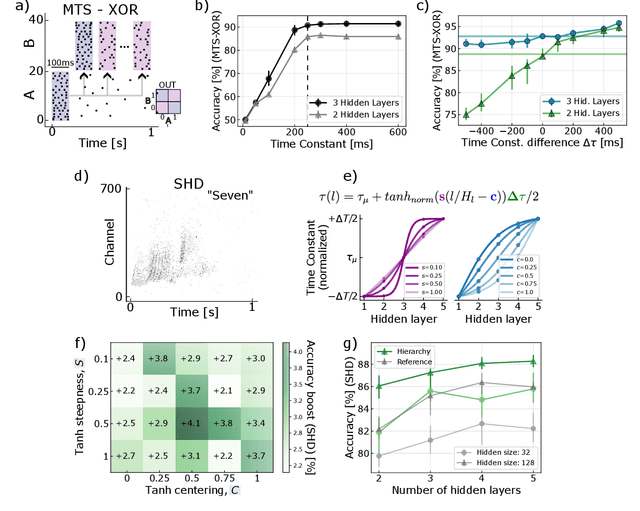

Spiking Neural Networks (SNNs) have the potential for rich spatio-temporal signal processing thanks to exploiting both spatial and temporal parameters. The temporal dynamics such as time constants of the synapses and neurons and delays have been recently shown to have computational benefits that help reduce the overall number of parameters required in the network and increase the accuracy of the SNNs in solving temporal tasks. Optimizing such temporal parameters, for example, through gradient descent, gives rise to a temporal architecture for different problems. As has been shown in machine learning, to reduce the cost of optimization, architectural biases can be applied, in this case in the temporal domain. Such inductive biases in temporal parameters have been found in neuroscience studies, highlighting a hierarchy of temporal structure and input representation in different layers of the cortex. Motivated by this, we propose to impose a hierarchy of temporal representation in the hidden layers of SNNs, highlighting that such an inductive bias improves their performance. We demonstrate the positive effects of temporal hierarchy in the time constants of feed-forward SNNs applied to temporal tasks (Multi-Time-Scale XOR and Keyword Spotting, with a benefit of up to 4.1% in classification accuracy). Moreover, we show that such architectural biases, i.e. hierarchy of time constants, naturally emerge when optimizing the time constants through gradient descent, initialized as homogeneous values. We further pursue this proposal in temporal convolutional SNNs, by introducing the hierarchical bias in the size and dilation of temporal kernels, giving rise to competitive results in popular temporal spike-based datasets.
DelGrad: Exact gradients in spiking networks for learning transmission delays and weights
Apr 30, 2024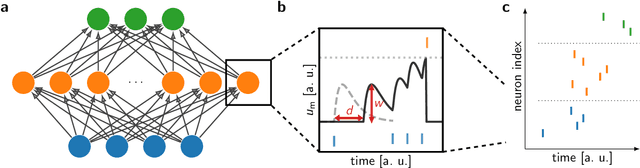
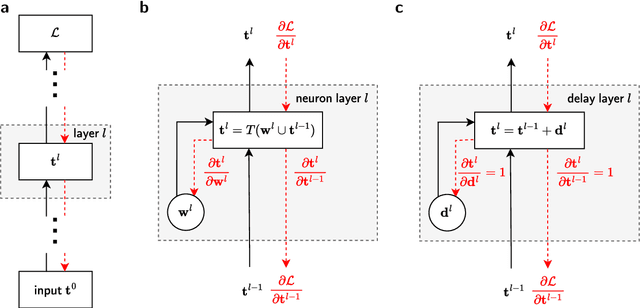
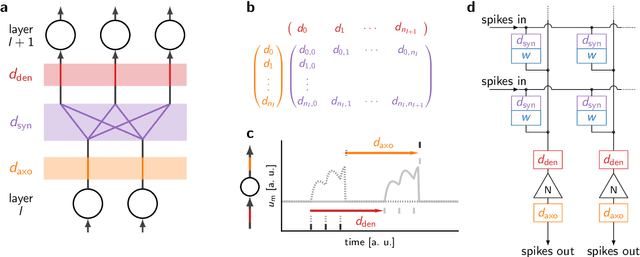
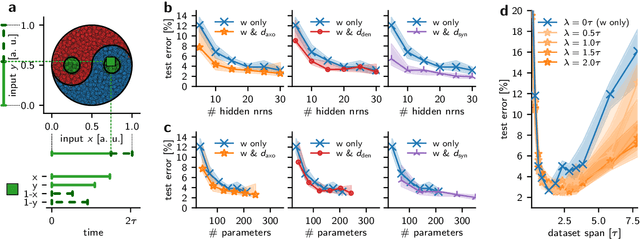
Spiking neural networks (SNNs) inherently rely on the timing of signals for representing and processing information. Transmission delays play an important role in shaping these temporal characteristics. Recent work has demonstrated the substantial advantages of learning these delays along with synaptic weights, both in terms of accuracy and memory efficiency. However, these approaches suffer from drawbacks in terms of precision and efficiency, as they operate in discrete time and with approximate gradients, while also requiring membrane potential recordings for calculating parameter updates. To alleviate these issues, we propose an analytical approach for calculating exact loss gradients with respect to both synaptic weights and delays in an event-based fashion. The inclusion of delays emerges naturally within our proposed formalism, enriching the model's search space with a temporal dimension. Our algorithm is purely based on the timing of individual spikes and does not require access to other variables such as membrane potentials. We explicitly compare the impact on accuracy and parameter efficiency of different types of delays - axonal, dendritic and synaptic. Furthermore, while previous work on learnable delays in SNNs has been mostly confined to software simulations, we demonstrate the functionality and benefits of our approach on the BrainScaleS-2 neuromorphic platform.
DenRAM: Neuromorphic Dendritic Architecture with RRAM for Efficient Temporal Processing with Delays
Dec 14, 2023An increasing number of neuroscience studies are highlighting the importance of spatial dendritic branching in pyramidal neurons in the brain for supporting non-linear computation through localized synaptic integration. In particular, dendritic branches play a key role in temporal signal processing and feature detection, using coincidence detection (CD) mechanisms, made possible by the presence of synaptic delays that align temporally disparate inputs for effective integration. Computational studies on spiking neural networks further highlight the significance of delays for CD operations, enabling spatio-temporal pattern recognition within feed-forward neural networks without the need for recurrent architectures. In this work, we present DenRAM, the first realization of a spiking neural network with analog dendritic circuits, integrated into a 130nm technology node coupled with resistive memory (RRAM) technology. DenRAM's dendritic circuits use the RRAM devices to implement both delays and synaptic weights in the network. By configuring the RRAM devices to reproduce bio-realistic timescales, and through exploiting their heterogeneity, we experimentally demonstrate DenRAM's capability to replicate synaptic delay profiles, and efficiently implement CD for spatio-temporal pattern recognition. To validate the architecture, we conduct comprehensive system-level simulations on two representative temporal benchmarks, highlighting DenRAM's resilience to analog hardware noise, and its superior accuracy compared to recurrent architectures with an equivalent number of parameters. DenRAM not only brings rich temporal processing capabilities to neuromorphic architectures, but also reduces the memory footprint of edge devices, provides high accuracy on temporal benchmarks, and represents a significant step-forward in low-power real-time signal processing technologies.
Scaling Limits of Memristor-Based Routers for Asynchronous Neuromorphic Systems
Jul 16, 2023Multi-core neuromorphic systems typically use on-chip routers to transmit spikes among cores. These routers require significant memory resources and consume a large part of the overall system's energy budget. A promising alternative approach to using standard CMOS and SRAM-based routers is to exploit the features of memristive crossbar arrays and use them as programmable switch-matrices that route spikes. However, the scaling of these crossbar arrays presents physical challenges, such as `IR drop' on the metal lines due to the parasitic resistance, and leakage current accumulation on multiple active `off' memristors. While reliability challenges of this type have been extensively studied in synchronous systems for compute-in-memory matrix-vector multiplication (MVM) accelerators and storage class memory, little effort has been devoted so far to characterizing the scaling limits of memristor-based crossbar routers. In this paper, we study the challenges of memristive crossbar arrays, when used as routing channels to transmit spikes in asynchronous Spiking Neural Network (SNN) hardware. We validate our analytical findings with experimental results obtained from a 4K-ReRAM chip which demonstrate its functionality as a routing crossbar. We determine the functionality bounds on the routing due to the IR drop and leak problem, based both on experimental measurements, modeling and circuit simulations in a 22nm FDSOI technology. This work highlights the constraint of this approach and provides useful guidelines for engineering memristor properties in memristive crossbar routers for building multi-core asynchronous neuromorphic systems.
Neuromorphic analog circuits for robust on-chip always-on learning in spiking neural networks
Jul 12, 2023
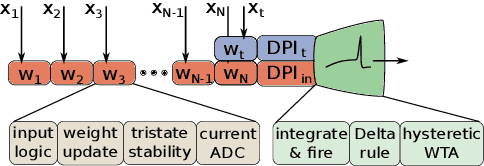
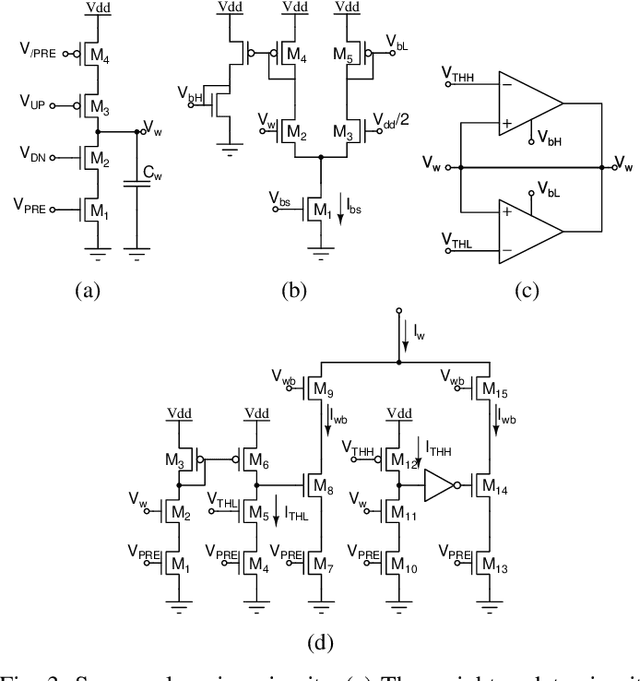
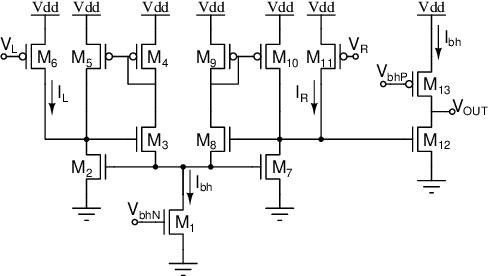
Mixed-signal neuromorphic systems represent a promising solution for solving extreme-edge computing tasks without relying on external computing resources. Their spiking neural network circuits are optimized for processing sensory data on-line in continuous-time. However, their low precision and high variability can severely limit their performance. To address this issue and improve their robustness to inhomogeneities and noise in both their internal state variables and external input signals, we designed on-chip learning circuits with short-term analog dynamics and long-term tristate discretization mechanisms. An additional hysteretic stop-learning mechanism is included to improve stability and automatically disable weight updates when necessary, to enable continuous always-on learning. We designed a spiking neural network with these learning circuits in a prototype chip using a 180 nm CMOS technology. Simulation and silicon measurement results from the prototype chip are presented. These circuits enable the construction of large-scale spiking neural networks with online learning capabilities for real-world edge computing tasks.
Synaptic metaplasticity with multi-level memristive devices
Jun 21, 2023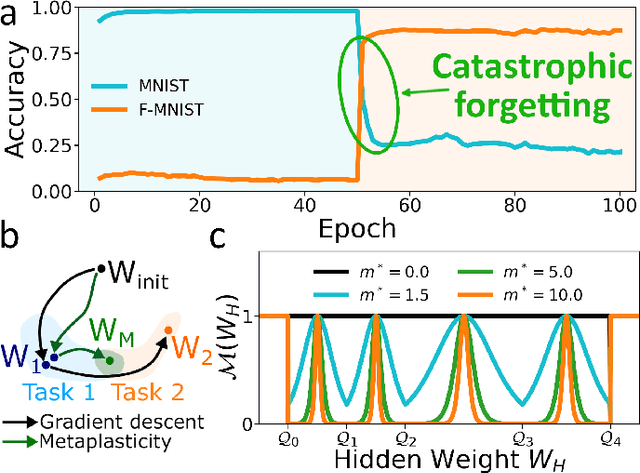
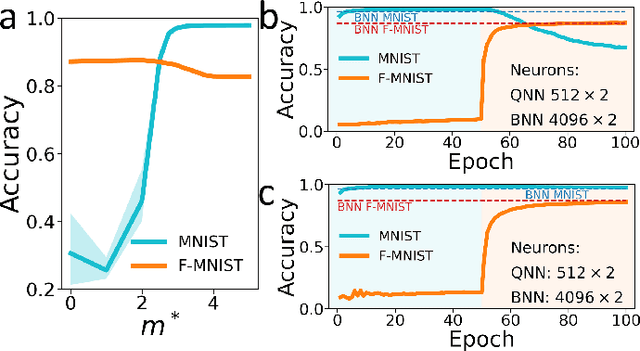
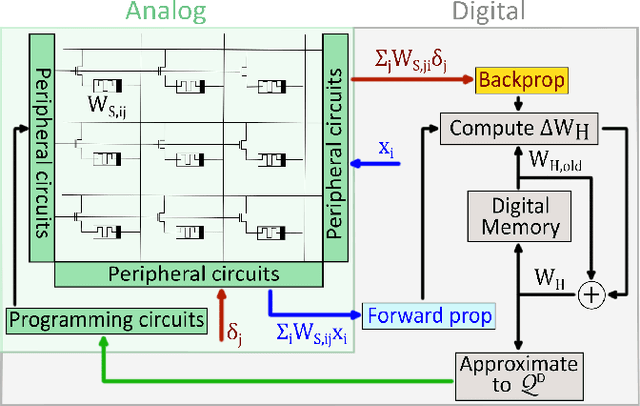
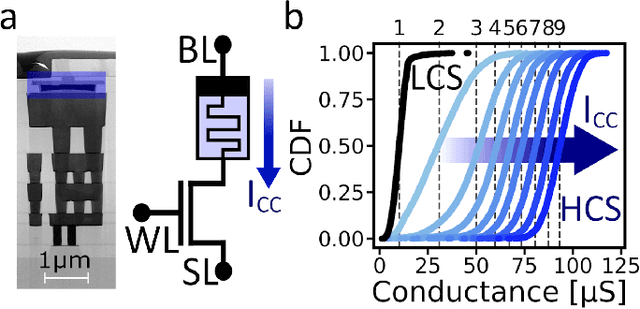
Deep learning has made remarkable progress in various tasks, surpassing human performance in some cases. However, one drawback of neural networks is catastrophic forgetting, where a network trained on one task forgets the solution when learning a new one. To address this issue, recent works have proposed solutions based on Binarized Neural Networks (BNNs) incorporating metaplasticity. In this work, we extend this solution to quantized neural networks (QNNs) and present a memristor-based hardware solution for implementing metaplasticity during both inference and training. We propose a hardware architecture that integrates quantized weights in memristor devices programmed in an analog multi-level fashion with a digital processing unit for high-precision metaplastic storage. We validated our approach using a combined software framework and memristor based crossbar array for in-memory computing fabricated in 130 nm CMOS technology. Our experimental results show that a two-layer perceptron achieves 97% and 86% accuracy on consecutive training of MNIST and Fashion-MNIST, equal to software baseline. This result demonstrates immunity to catastrophic forgetting and the resilience to analog device imperfections of the proposed solution. Moreover, our architecture is compatible with the memristor limited endurance and has a 15x reduction in memory