 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian continual learning and forgetting in neural networks
Apr 18, 2025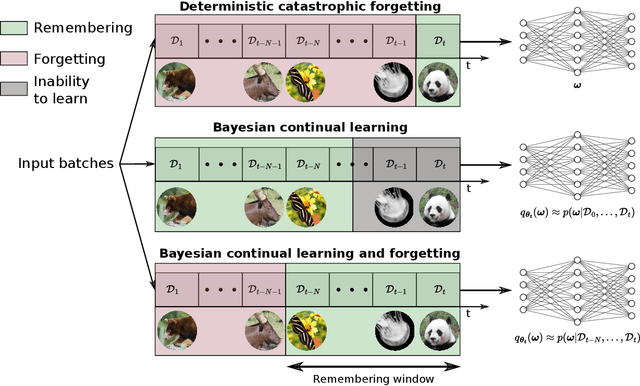
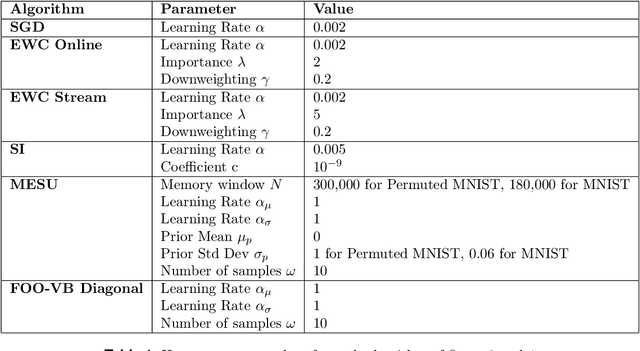
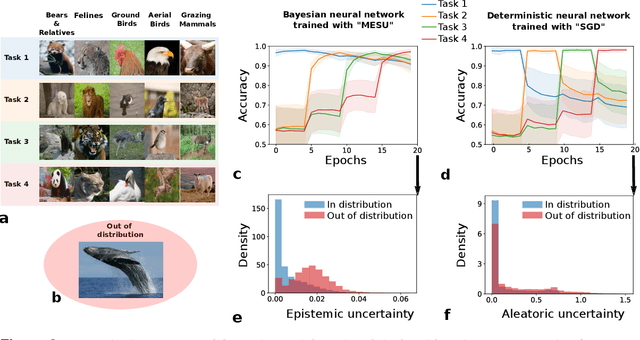
Biological synapses effortlessly balance memory retention and flexibility, yet artificial neural networks still struggle with the extremes of catastrophic forgetting and catastrophic remembering. Here, we introduce Metaplasticity from Synaptic Uncertainty (MESU), a Bayesian framework that updates network parameters according their uncertainty. This approach allows a principled combination of learning and forgetting that ensures that critical knowledge is preserved while unused or outdated information is gradually released. Unlike standard Bayesian approaches -- which risk becoming overly constrained, and popular continual-learning methods that rely on explicit task boundaries, MESU seamlessly adapts to streaming data. It further provides reliable epistemic uncertainty estimates, allowing out-of-distribution detection, the only computational cost being to sample the weights multiple times to provide proper output statistics. Experiments on image-classification benchmarks demonstrate that MESU mitigates catastrophic forgetting, while maintaining plasticity for new tasks. When training 200 sequential permuted MNIST tasks, MESU outperforms established continual learning techniques in terms of accuracy, capability to learn additional tasks, and out-of-distribution data detection. Additionally, due to its non-reliance on task boundaries, MESU outperforms conventional learning techniques on the incremental training of CIFAR-100 tasks consistently in a wide range of scenarios. Our results unify ideas from metaplasticity, Bayesian inference, and Hessian-based regularization, offering a biologically-inspired pathway to robust, perpetual learning.
Bayesian Metaplasticity from Synaptic Uncertainty
Dec 15, 2023Catastrophic forgetting remains a challenge for neural networks, especially in lifelong learning scenarios. In this study, we introduce MEtaplasticity from Synaptic Uncertainty (MESU), inspired by metaplasticity and Bayesian inference principles. MESU harnesses synaptic uncertainty to retain information over time, with its update rule closely approximating the diagonal Newton's method for synaptic updates. Through continual learning experiments on permuted MNIST tasks, we demonstrate MESU's remarkable capability to maintain learning performance across 100 tasks without the need of explicit task boundaries.
Synaptic metaplasticity with multi-level memristive devices
Jun 21, 2023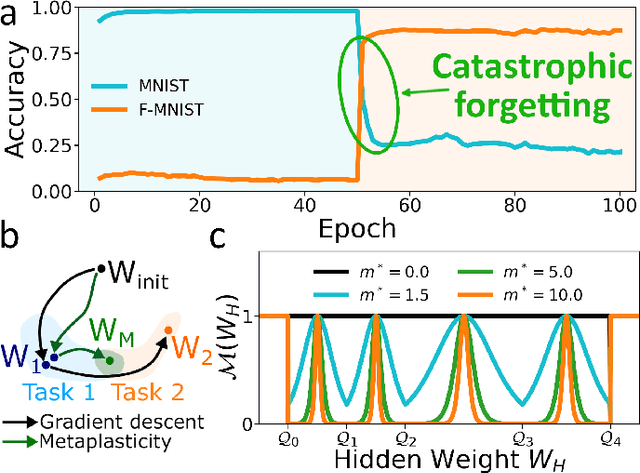
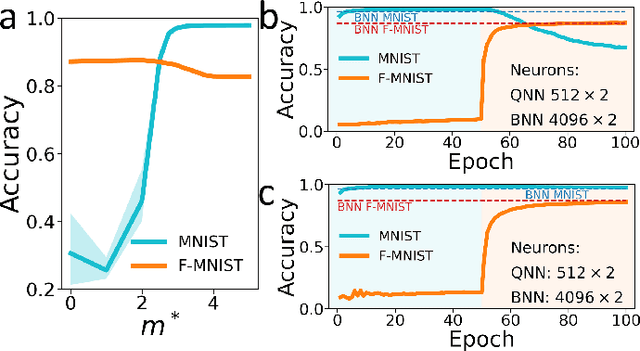
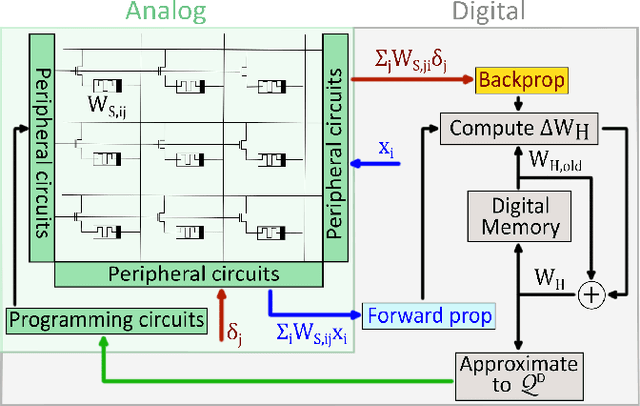
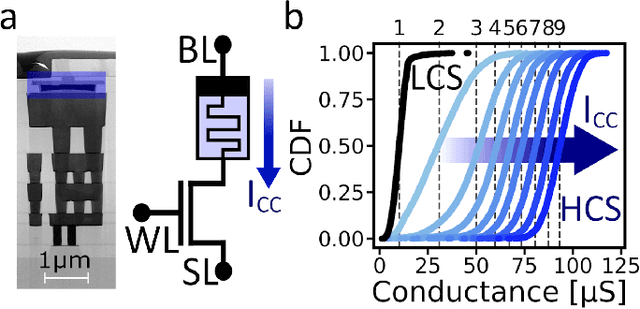
Deep learning has made remarkable progress in various tasks, surpassing human performance in some cases. However, one drawback of neural networks is catastrophic forgetting, where a network trained on one task forgets the solution when learning a new one. To address this issue, recent works have proposed solutions based on Binarized Neural Networks (BNNs) incorporating metaplasticity. In this work, we extend this solution to quantized neural networks (QNNs) and present a memristor-based hardware solution for implementing metaplasticity during both inference and training. We propose a hardware architecture that integrates quantized weights in memristor devices programmed in an analog multi-level fashion with a digital processing unit for high-precision metaplastic storage. We validated our approach using a combined software framework and memristor based crossbar array for in-memory computing fabricated in 130 nm CMOS technology. Our experimental results show that a two-layer perceptron achieves 97% and 86% accuracy on consecutive training of MNIST and Fashion-MNIST, equal to software baseline. This result demonstrates immunity to catastrophic forgetting and the resilience to analog device imperfections of the proposed solution. Moreover, our architecture is compatible with the memristor limited endurance and has a 15x reduction in memory
Model of the Weak Reset Process in HfOx Resistive Memory for Deep Learning Frameworks
Jul 02, 2021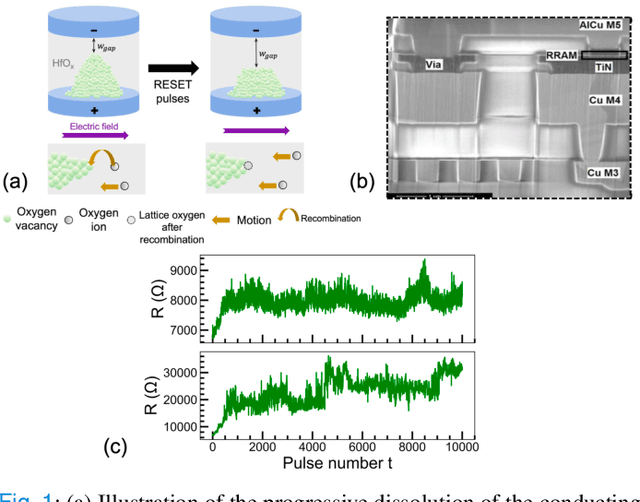
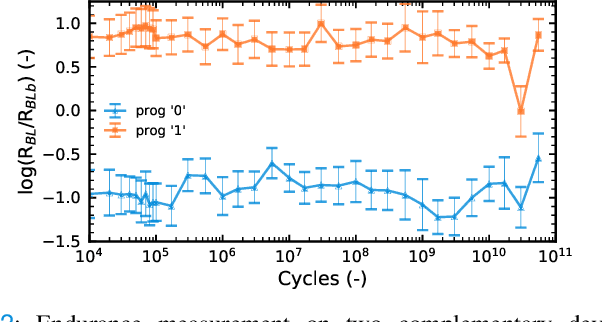
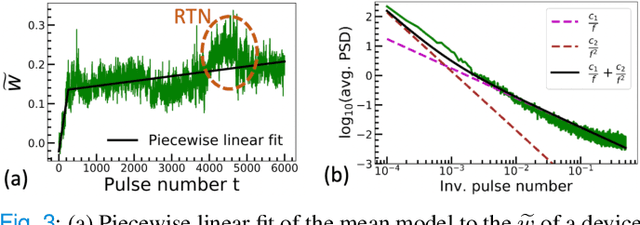
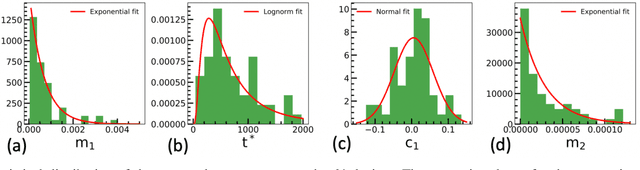
The implementation of current deep learning training algorithms is power-hungry, owing to data transfer between memory and logic units. Oxide-based RRAMs are outstanding candidates to implement in-memory computing, which is less power-intensive. Their weak RESET regime, is particularly attractive for learning, as it allows tuning the resistance of the devices with remarkable endurance. However, the resistive change behavior in this regime suffers many fluctuations and is particularly challenging to model, especially in a way compatible with tools used for simulating deep learning. In this work, we present a model of the weak RESET process in hafnium oxide RRAM and integrate this model within the PyTorch deep learning framework. Validated on experiments on a hybrid CMOS/RRAM technology, our model reproduces both the noisy progressive behavior and the device-to-device (D2D) variability. We use this tool to train Binarized Neural Networks for the MNIST handwritten digit recognition task and the CIFAR-10 object classification task. We simulate our model with and without various aspects of device imperfections to understand their impact on the training process and identify that the D2D variability is the most detrimental aspect. The framework can be used in the same manner for other types of memories to identify the device imperfections that cause the most degradation, which can, in turn, be used to optimize the devices to reduce the impact of these imperfections.
Synaptic metaplasticity in binarized neural networks
Jan 19, 2021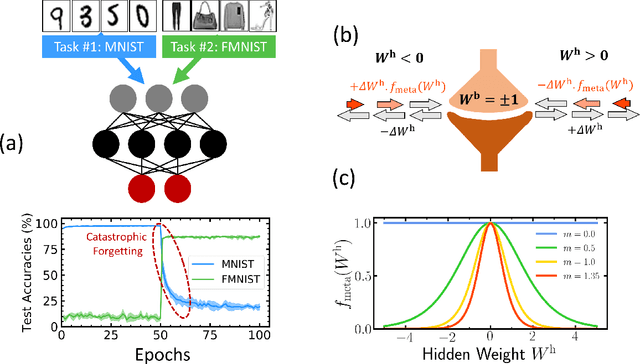
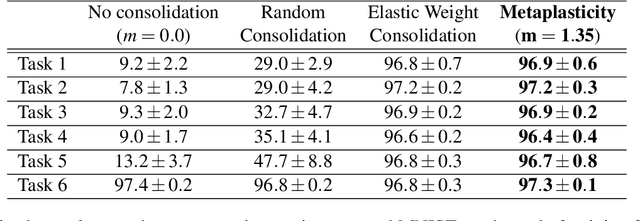
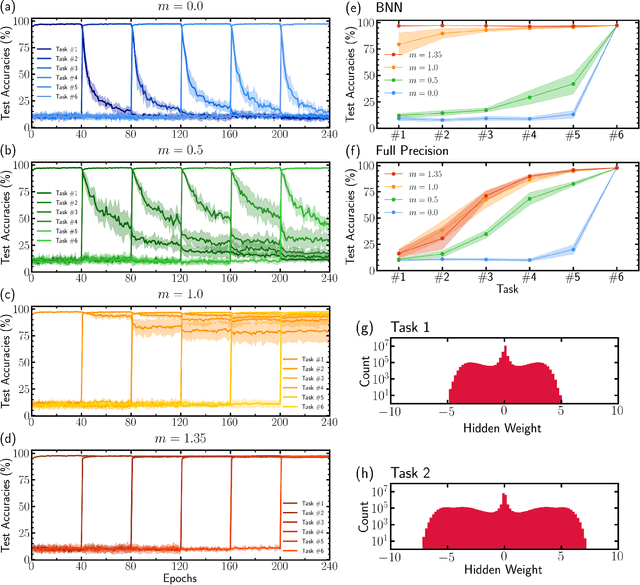
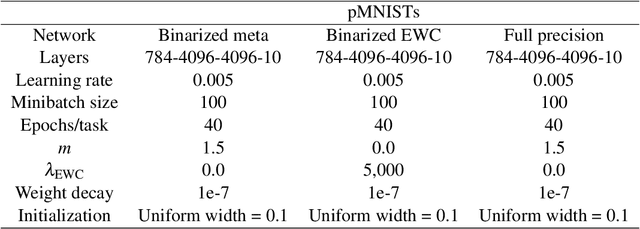
Unlike the brain, artificial neural networks, including state-of-the-art deep neural networks for computer vision, are subject to "catastrophic forgetting": they rapidly forget the previous task when trained on a new one. Neuroscience suggests that biological synapses avoid this issue through the process of synaptic consolidation and metaplasticity: the plasticity itself changes upon repeated synaptic events. In this work, we show that this concept of metaplasticity can be transferred to a particular type of deep neural networks, binarized neural networks, to reduce catastrophic forgetting.
* 3 pages, 1 figure
Implementing Binarized Neural Networks with Magnetoresistive RAM without Error Correction
Aug 12, 2019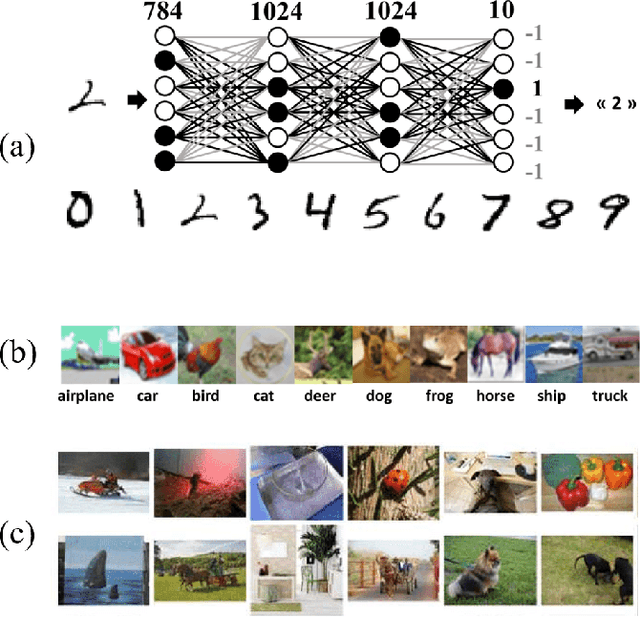
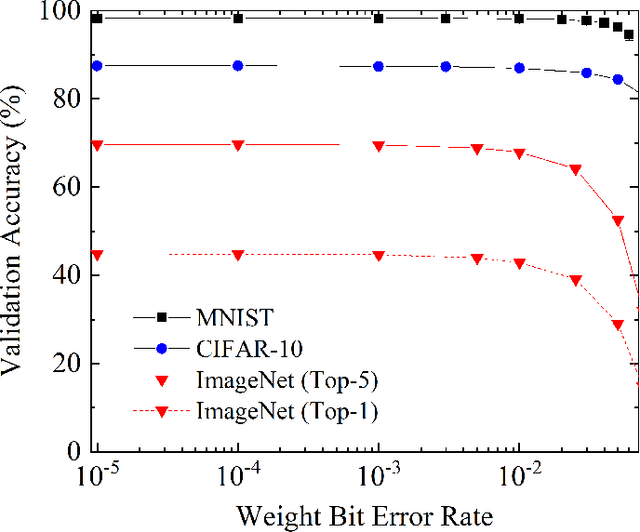
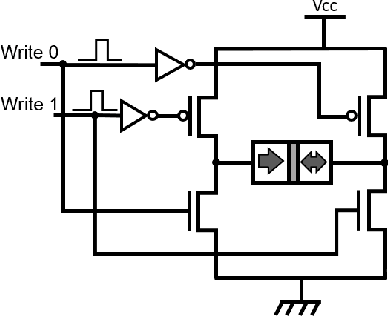
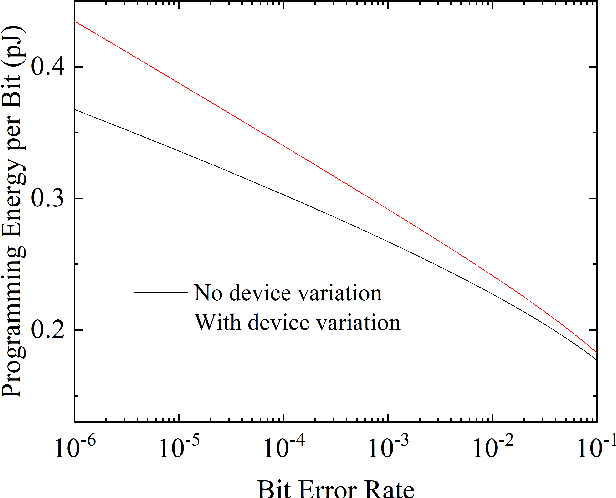
One of the most exciting applications of Spin Torque Magnetoresistive Random Access Memory (ST-MRAM) is the in-memory implementation of deep neural networks, which could allow improving the energy efficiency of Artificial Intelligence by orders of magnitude with regards to its implementation on computers and graphics cards. In particular, ST-MRAM could be ideal for implementing Binarized Neural Networks (BNNs), a type of deep neural networks discovered in 2016, which can achieve state-of-the-art performance with a highly reduced memory footprint with regards to conventional artificial intelligence approaches. The challenge of ST-MRAM, however, is that it is prone to write errors and usually requires the use of error correction. In this work, we show that these bit errors can be tolerated by BNNs to an outstanding level, based on examples of image recognition tasks (MNIST, CIFAR-10 and ImageNet): bit error rates of ST-MRAM up to 0.1% have little impact on recognition accuracy. The requirements for ST-MRAM are therefore considerably relaxed for BNNs with regards to traditional applications. By consequence, we show that for BNNs, ST-MRAMs can be programmed with weak (low-energy) programming conditions, without error correcting codes. We show that this result can allow the use of low energy and low area ST-MRAM cells, and show that the energy savings at the system level can reach a factor two.