 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel of the Weak Reset Process in HfOx Resistive Memory for Deep Learning Frameworks
Jul 02, 2021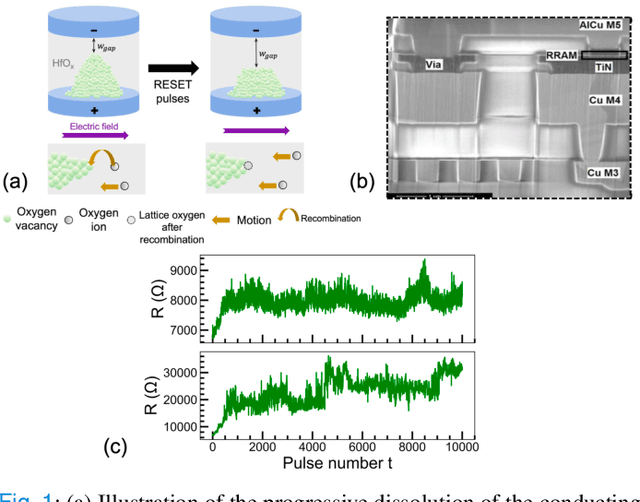
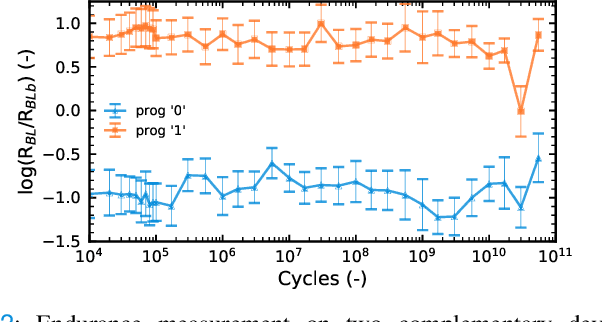
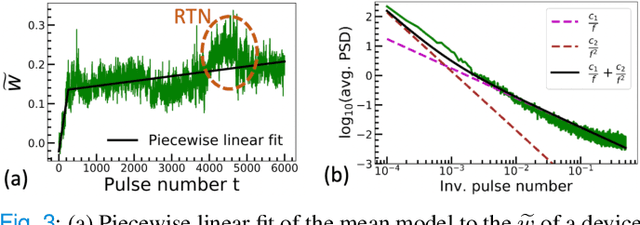
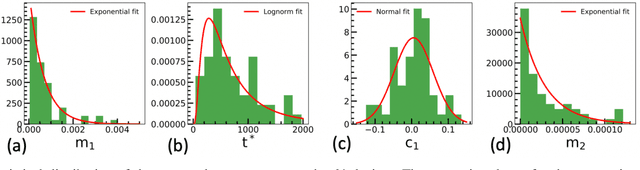
The implementation of current deep learning training algorithms is power-hungry, owing to data transfer between memory and logic units. Oxide-based RRAMs are outstanding candidates to implement in-memory computing, which is less power-intensive. Their weak RESET regime, is particularly attractive for learning, as it allows tuning the resistance of the devices with remarkable endurance. However, the resistive change behavior in this regime suffers many fluctuations and is particularly challenging to model, especially in a way compatible with tools used for simulating deep learning. In this work, we present a model of the weak RESET process in hafnium oxide RRAM and integrate this model within the PyTorch deep learning framework. Validated on experiments on a hybrid CMOS/RRAM technology, our model reproduces both the noisy progressive behavior and the device-to-device (D2D) variability. We use this tool to train Binarized Neural Networks for the MNIST handwritten digit recognition task and the CIFAR-10 object classification task. We simulate our model with and without various aspects of device imperfections to understand their impact on the training process and identify that the D2D variability is the most detrimental aspect. The framework can be used in the same manner for other types of memories to identify the device imperfections that cause the most degradation, which can, in turn, be used to optimize the devices to reduce the impact of these imperfections.
Implementing Binarized Neural Networks with Magnetoresistive RAM without Error Correction
Aug 12, 2019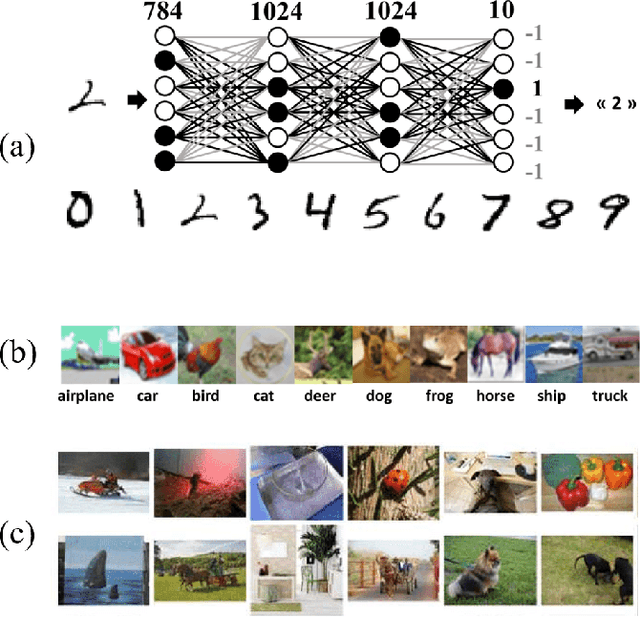
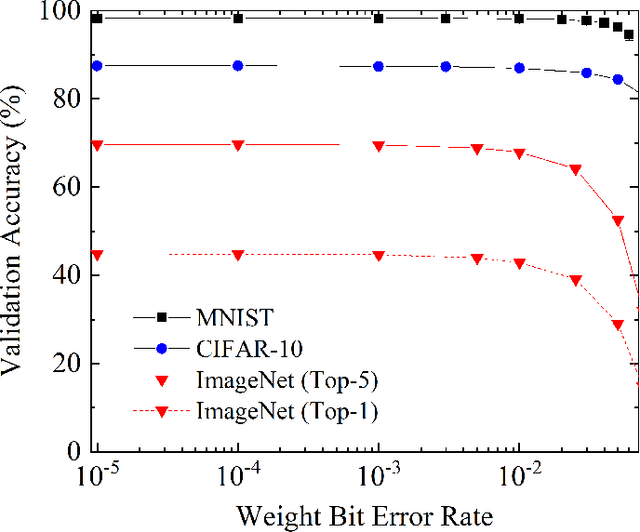
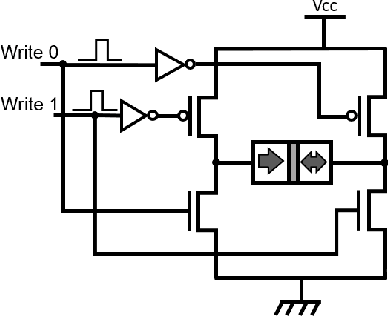
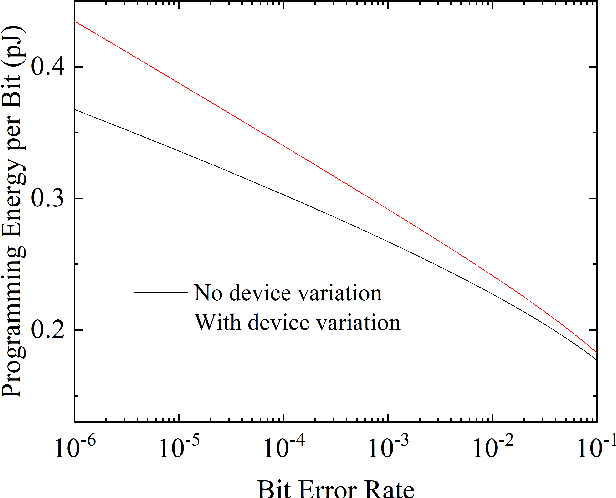
One of the most exciting applications of Spin Torque Magnetoresistive Random Access Memory (ST-MRAM) is the in-memory implementation of deep neural networks, which could allow improving the energy efficiency of Artificial Intelligence by orders of magnitude with regards to its implementation on computers and graphics cards. In particular, ST-MRAM could be ideal for implementing Binarized Neural Networks (BNNs), a type of deep neural networks discovered in 2016, which can achieve state-of-the-art performance with a highly reduced memory footprint with regards to conventional artificial intelligence approaches. The challenge of ST-MRAM, however, is that it is prone to write errors and usually requires the use of error correction. In this work, we show that these bit errors can be tolerated by BNNs to an outstanding level, based on examples of image recognition tasks (MNIST, CIFAR-10 and ImageNet): bit error rates of ST-MRAM up to 0.1% have little impact on recognition accuracy. The requirements for ST-MRAM are therefore considerably relaxed for BNNs with regards to traditional applications. By consequence, we show that for BNNs, ST-MRAMs can be programmed with weak (low-energy) programming conditions, without error correcting codes. We show that this result can allow the use of low energy and low area ST-MRAM cells, and show that the energy savings at the system level can reach a factor two.
Spatio-temporal Learning with Arrays of Analog Nanosynapses
Sep 12, 2017



Emerging nanodevices such as resistive memories are being considered for hardware realizations of a variety of artificial neural networks (ANNs), including highly promising online variants of the learning approaches known as reservoir computing (RC) and the extreme learning machine (ELM). We propose an RC/ELM inspired learning system built with nanosynapses that performs both on-chip projection and regression operations. To address time-dynamic tasks, the hidden neurons of our system perform spatio-temporal integration and can be further enhanced with variable sampling or multiple activation windows. We detail the system and show its use in conjunction with a highly analog nanosynapse device on a standard task with intrinsic timing dynamics- the TI-46 battery of spoken digits. The system achieves nearly perfect (99%) accuracy at sufficient hidden layer size, which compares favorably with software results. In addition, the model is extended to a larger dataset, the MNIST database of handwritten digits. By translating the database into the time domain and using variable integration windows, up to 95% classification accuracy is achieved. In addition to an intrinsically low-power programming style, the proposed architecture learns very quickly and can easily be converted into a spiking system with negligible loss in performance- all features that confer significant energy efficiency.