 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian continual learning and forgetting in neural networks
Apr 18, 2025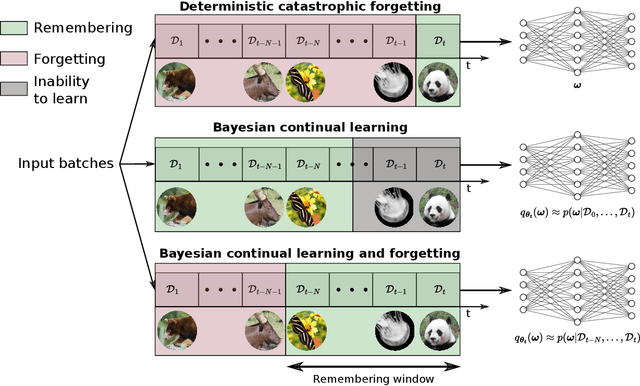
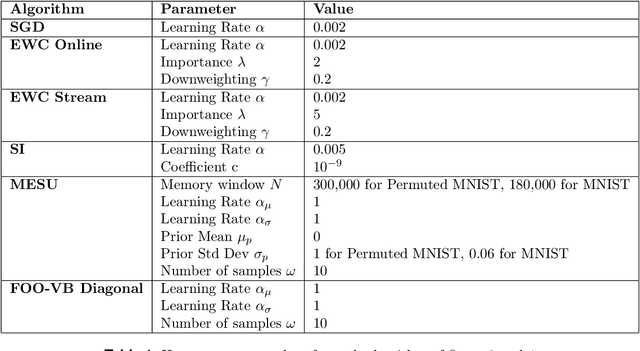
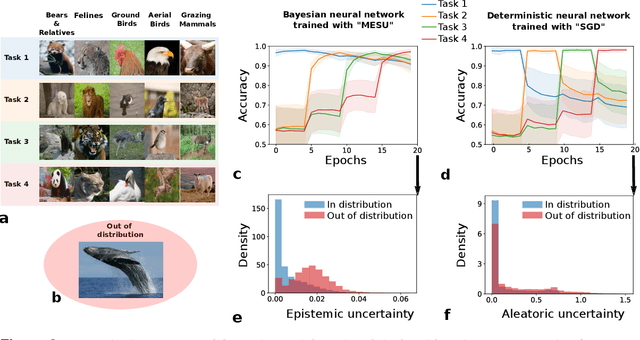
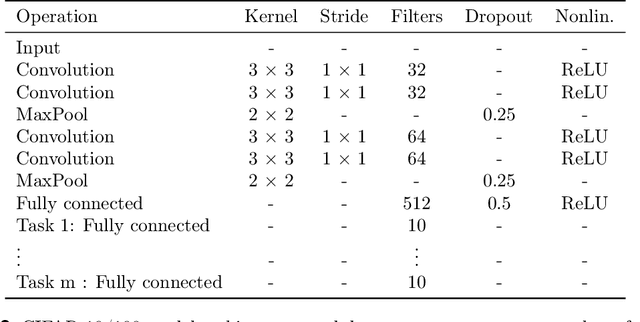
Biological synapses effortlessly balance memory retention and flexibility, yet artificial neural networks still struggle with the extremes of catastrophic forgetting and catastrophic remembering. Here, we introduce Metaplasticity from Synaptic Uncertainty (MESU), a Bayesian framework that updates network parameters according their uncertainty. This approach allows a principled combination of learning and forgetting that ensures that critical knowledge is preserved while unused or outdated information is gradually released. Unlike standard Bayesian approaches -- which risk becoming overly constrained, and popular continual-learning methods that rely on explicit task boundaries, MESU seamlessly adapts to streaming data. It further provides reliable epistemic uncertainty estimates, allowing out-of-distribution detection, the only computational cost being to sample the weights multiple times to provide proper output statistics. Experiments on image-classification benchmarks demonstrate that MESU mitigates catastrophic forgetting, while maintaining plasticity for new tasks. When training 200 sequential permuted MNIST tasks, MESU outperforms established continual learning techniques in terms of accuracy, capability to learn additional tasks, and out-of-distribution data detection. Additionally, due to its non-reliance on task boundaries, MESU outperforms conventional learning techniques on the incremental training of CIFAR-100 tasks consistently in a wide range of scenarios. Our results unify ideas from metaplasticity, Bayesian inference, and Hessian-based regularization, offering a biologically-inspired pathway to robust, perpetual learning.
Roadmap to Neuromorphic Computing with Emerging Technologies
Jul 02, 2024



The roadmap is organized into several thematic sections, outlining current computing challenges, discussing the neuromorphic computing approach, analyzing mature and currently utilized technologies, providing an overview of emerging technologies, addressing material challenges, exploring novel computing concepts, and finally examining the maturity level of emerging technologies while determining the next essential steps for their advancement.
Unsupervised End-to-End Training with a Self-Defined Bio-Inspired Target
Mar 18, 2024Current unsupervised learning methods depend on end-to-end training via deep learning techniques such as self-supervised learning, with high computational requirements, or employ layer-by-layer training using bio-inspired approaches like Hebbian learning, using local learning rules incompatible with supervised learning. Both approaches are problematic for edge AI hardware that relies on sparse computational resources and would strongly benefit from alternating between unsupervised and supervised learning phases - thus leveraging widely available unlabeled data from the environment as well as labeled training datasets. To solve this challenge, in this work, we introduce a 'self-defined target' that uses Winner-Take-All (WTA) selectivity at the network's final layer, complemented by regularization through biologically inspired homeostasis mechanism. This approach, framework-agnostic and compatible with both global (Backpropagation) and local (Equilibrium propagation) learning rules, achieves a 97.6% test accuracy on the MNIST dataset. Furthermore, we demonstrate that incorporating a hidden layer enhances classification accuracy and the quality of learned features across all training methods, showcasing the advantages of end-to-end unsupervised training. Extending to semi-supervised learning, our method dynamically adjusts the target according to data availability, reaching a 96.6% accuracy with just 600 labeled MNIST samples. This result highlights our 'unsupervised target' strategy's efficacy and flexibility in scenarios ranging from abundant to no labeled data availability.
Bayesian Metaplasticity from Synaptic Uncertainty
Dec 15, 2023Catastrophic forgetting remains a challenge for neural networks, especially in lifelong learning scenarios. In this study, we introduce MEtaplasticity from Synaptic Uncertainty (MESU), inspired by metaplasticity and Bayesian inference principles. MESU harnesses synaptic uncertainty to retain information over time, with its update rule closely approximating the diagonal Newton's method for synaptic updates. Through continual learning experiments on permuted MNIST tasks, we demonstrate MESU's remarkable capability to maintain learning performance across 100 tasks without the need of explicit task boundaries.
Synaptic metaplasticity with multi-level memristive devices
Jun 21, 2023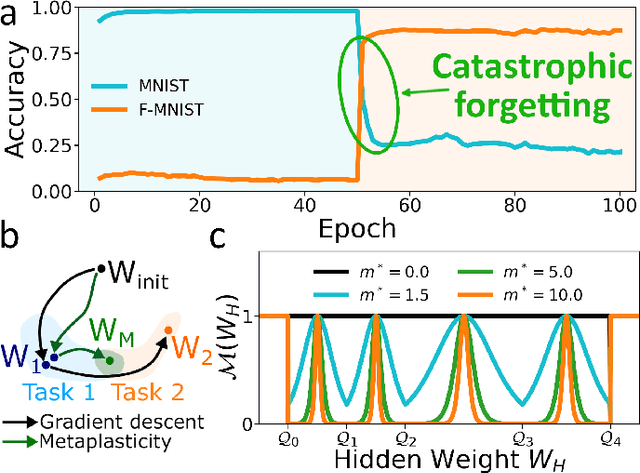
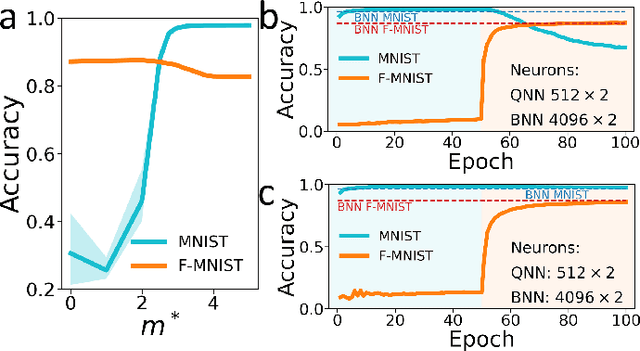
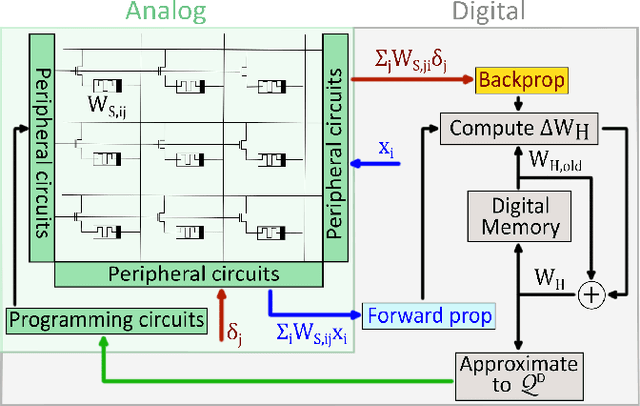
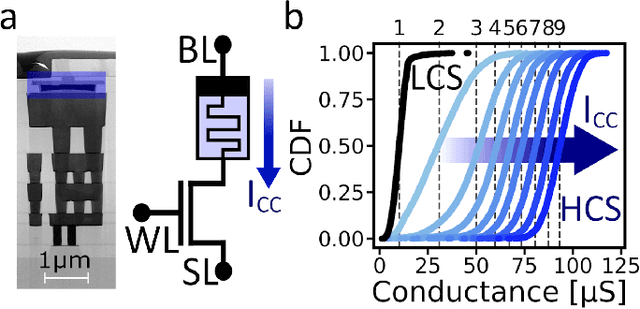
Deep learning has made remarkable progress in various tasks, surpassing human performance in some cases. However, one drawback of neural networks is catastrophic forgetting, where a network trained on one task forgets the solution when learning a new one. To address this issue, recent works have proposed solutions based on Binarized Neural Networks (BNNs) incorporating metaplasticity. In this work, we extend this solution to quantized neural networks (QNNs) and present a memristor-based hardware solution for implementing metaplasticity during both inference and training. We propose a hardware architecture that integrates quantized weights in memristor devices programmed in an analog multi-level fashion with a digital processing unit for high-precision metaplastic storage. We validated our approach using a combined software framework and memristor based crossbar array for in-memory computing fabricated in 130 nm CMOS technology. Our experimental results show that a two-layer perceptron achieves 97% and 86% accuracy on consecutive training of MNIST and Fashion-MNIST, equal to software baseline. This result demonstrates immunity to catastrophic forgetting and the resilience to analog device imperfections of the proposed solution. Moreover, our architecture is compatible with the memristor limited endurance and has a 15x reduction in memory
Voltage-Dependent Synaptic Plasticity (VDSP): Unsupervised probabilistic Hebbian plasticity rule based on neurons membrane potential
Apr 14, 2022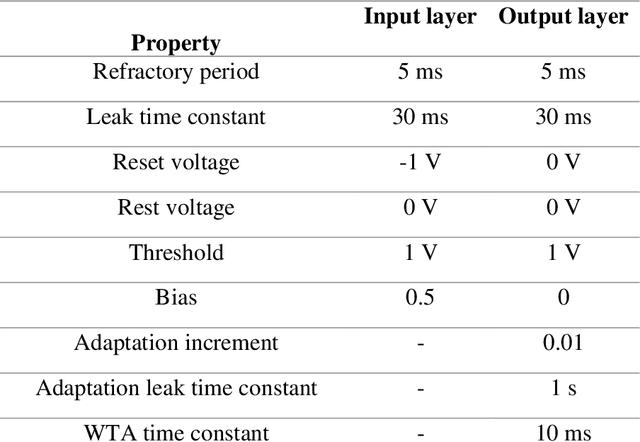
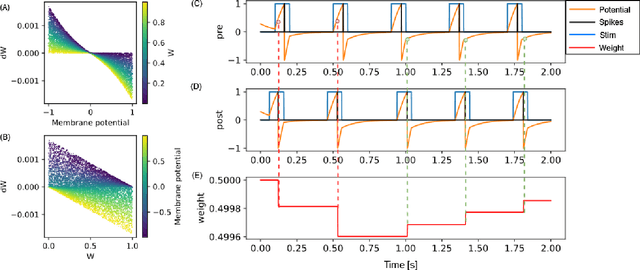
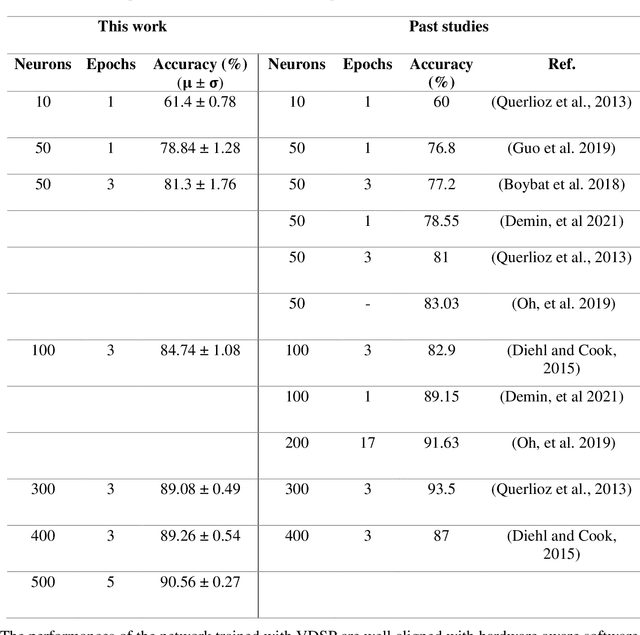
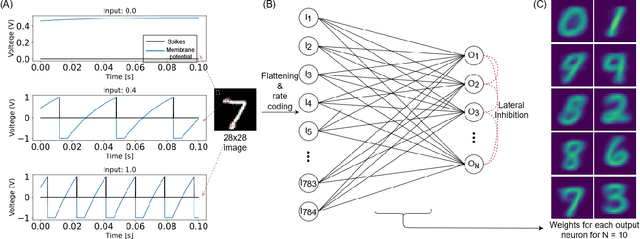
This study proposes voltage-dependent-synaptic plasticity (VDSP), a novel brain-inspired unsupervised local learning rule for the online implementation of Hebb's plasticity mechanism on neuromorphic hardware. The proposed VDSP learning rule updates the synaptic conductance on the spike of the postsynaptic neuron only, which reduces by a factor of two the number of updates with respect to standard spike-timing-dependent plasticity (STDP). This update is dependent on the membrane potential of the presynaptic neuron, which is readily available as part of neuron implementation and hence does not require additional memory for storage. Moreover, the update is also regularized on synaptic weight and prevents explosion or vanishing of weights on repeated stimulation. Rigorous mathematical analysis is performed to draw an equivalence between VDSP and STDP. To validate the system-level performance of VDSP, we train a single-layer spiking neural network (SNN) for the recognition of handwritten digits. We report 85.01 $ \pm $ 0.76% (Mean $ \pm $ S.D.) accuracy for a network of 100 output neurons on the MNIST dataset. The performance improves when scaling the network size (89.93 $ \pm $ 0.41% for 400 output neurons, 90.56 $ \pm $ 0.27 for 500 neurons), which validates the applicability of the proposed learning rule for large-scale computer vision tasks. Interestingly, the learning rule better adapts than STDP to the frequency of input signal and does not require hand-tuning of hyperparameters.
Energy Efficient Learning with Low Resolution Stochastic Domain Wall Synapse Based Deep Neural Networks
Nov 14, 2021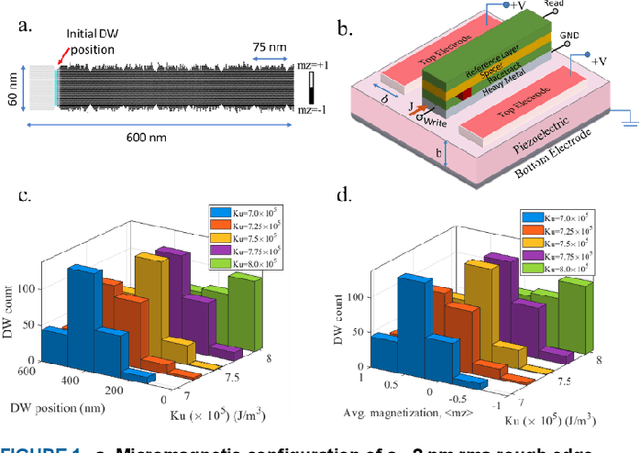
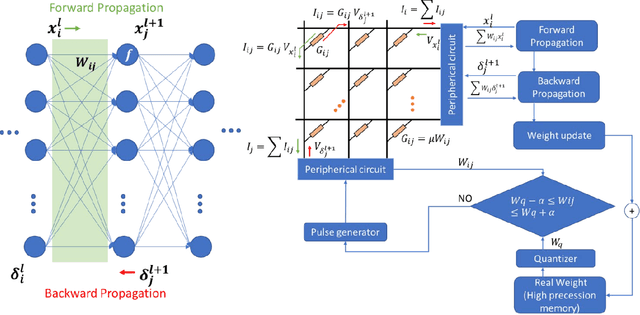
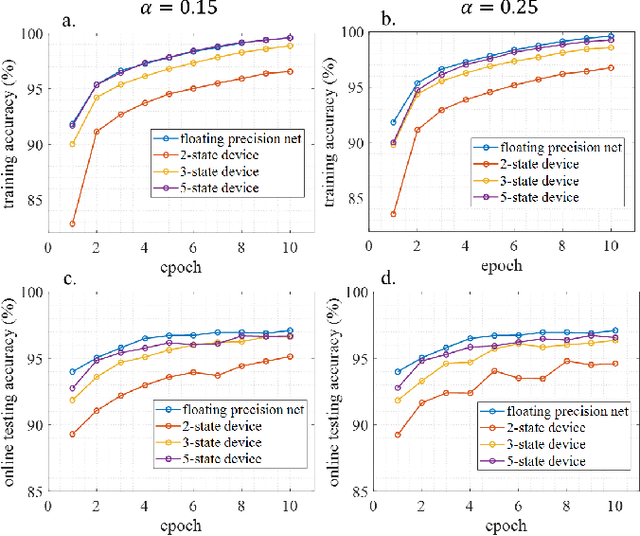
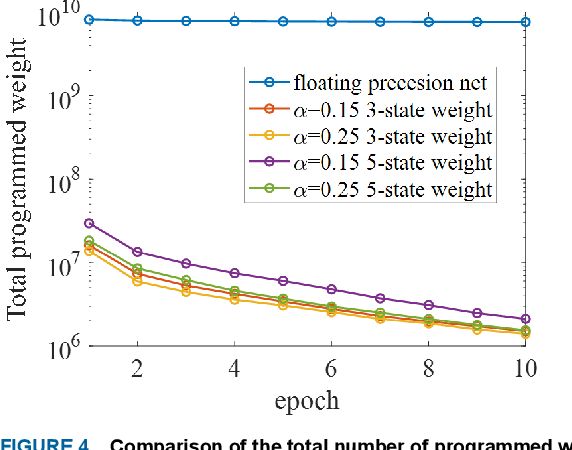
We demonstrate that extremely low resolution quantized (nominally 5-state) synapses with large stochastic variations in Domain Wall (DW) position can be both energy efficient and achieve reasonably high testing accuracies compared to Deep Neural Networks (DNNs) of similar sizes using floating precision synaptic weights. Specifically, voltage controlled DW devices demonstrate stochastic behavior as modeled rigorously with micromagnetic simulations and can only encode limited states; however, they can be extremely energy efficient during both training and inference. We show that by implementing suitable modifications to the learning algorithms, we can address the stochastic behavior as well as mitigate the effect of their low-resolution to achieve high testing accuracies. In this study, we propose both in-situ and ex-situ training algorithms, based on modification of the algorithm proposed by Hubara et al. [1] which works well with quantization of synaptic weights. We train several 5-layer DNNs on MNIST dataset using 2-, 3- and 5-state DW device as synapse. For in-situ training, a separate high precision memory unit is adopted to preserve and accumulate the weight gradients, which are then quantized to program the low precision DW devices. Moreover, a sizeable noise tolerance margin is used during the training to address the intrinsic programming noise. For ex-situ training, a precursor DNN is first trained based on the characterized DW device model and a noise tolerance margin, which is similar to the in-situ training. Remarkably, for in-situ inference the energy dissipation to program the devices is only 13 pJ per inference given that the training is performed over the entire MNIST dataset for 10 epochs.
Forecasting the outcome of spintronic experiments with Neural Ordinary Differential Equations
Jul 23, 2021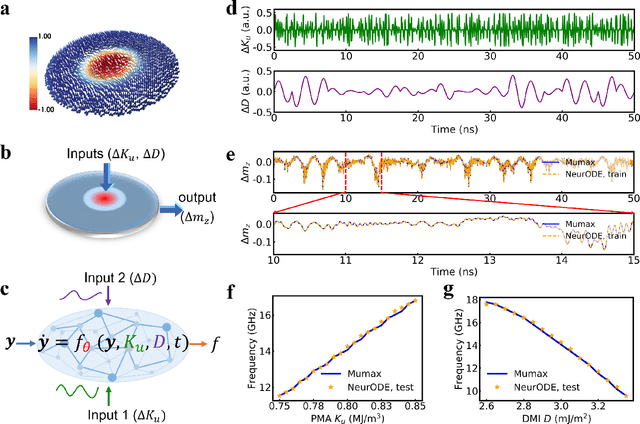
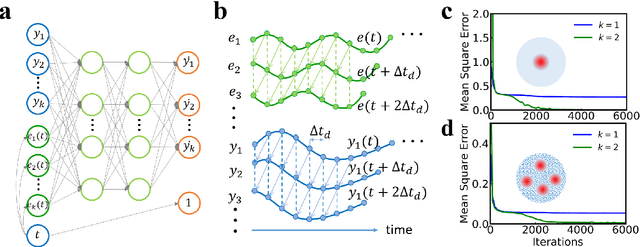
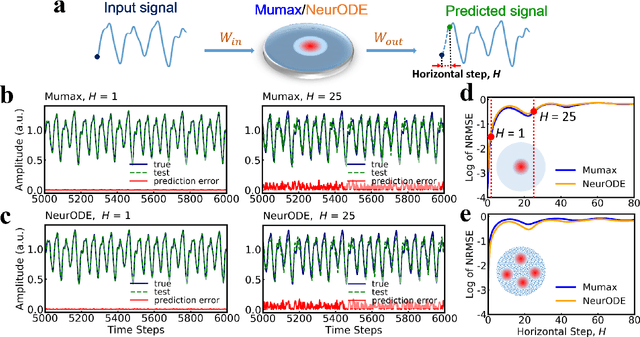
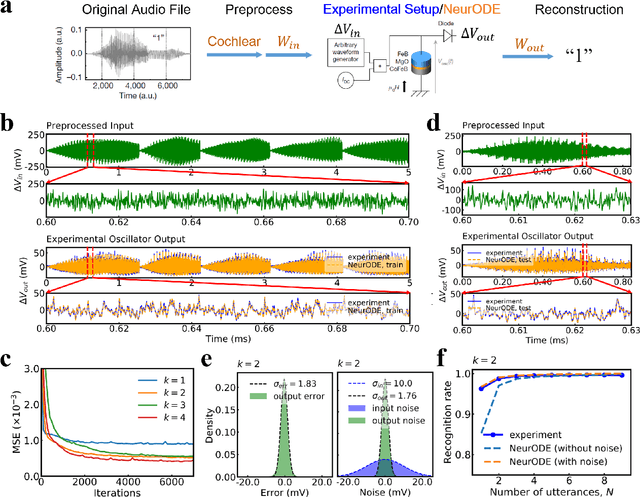
Deep learning has an increasing impact to assist research, allowing, for example, the discovery of novel materials. Until now, however, these artificial intelligence techniques have fallen short of discovering the full differential equation of an experimental physical system. Here we show that a dynamical neural network, trained on a minimal amount of data, can predict the behavior of spintronic devices with high accuracy and an extremely efficient simulation time, compared to the micromagnetic simulations that are usually employed to model them. For this purpose, we re-frame the formalism of Neural Ordinary Differential Equations (ODEs) to the constraints of spintronics: few measured outputs, multiple inputs and internal parameters. We demonstrate with Spin-Neural ODEs an acceleration factor over 200 compared to micromagnetic simulations for a complex problem -- the simulation of a reservoir computer made of magnetic skyrmions (20 minutes compared to three days). In a second realization, we show that we can predict the noisy response of experimental spintronic nano-oscillators to varying inputs after training Spin-Neural ODEs on five milliseconds of their measured response to different excitations. Spin-Neural ODE is a disruptive tool for developing spintronic applications in complement to micromagnetic simulations, which are time-consuming and cannot fit experiments when noise or imperfections are present. Spin-Neural ODE can also be generalized to other electronic devices involving dynamics.
Model of the Weak Reset Process in HfOx Resistive Memory for Deep Learning Frameworks
Jul 02, 2021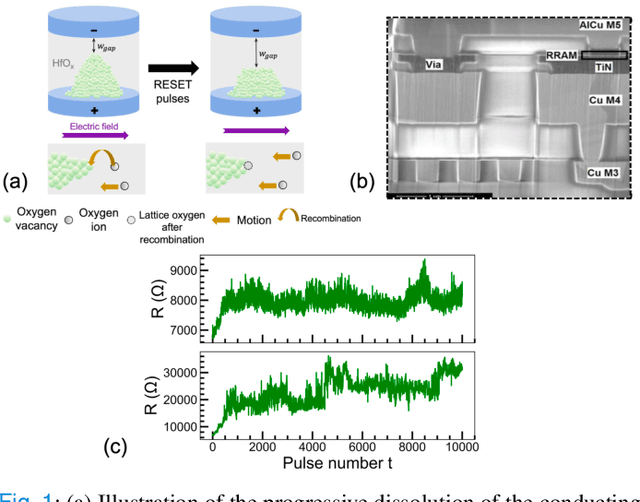
The implementation of current deep learning training algorithms is power-hungry, owing to data transfer between memory and logic units. Oxide-based RRAMs are outstanding candidates to implement in-memory computing, which is less power-intensive. Their weak RESET regime, is particularly attractive for learning, as it allows tuning the resistance of the devices with remarkable endurance. However, the resistive change behavior in this regime suffers many fluctuations and is particularly challenging to model, especially in a way compatible with tools used for simulating deep learning. In this work, we present a model of the weak RESET process in hafnium oxide RRAM and integrate this model within the PyTorch deep learning framework. Validated on experiments on a hybrid CMOS/RRAM technology, our model reproduces both the noisy progressive behavior and the device-to-device (D2D) variability. We use this tool to train Binarized Neural Networks for the MNIST handwritten digit recognition task and the CIFAR-10 object classification task. We simulate our model with and without various aspects of device imperfections to understand their impact on the training process and identify that the D2D variability is the most detrimental aspect. The framework can be used in the same manner for other types of memories to identify the device imperfections that cause the most degradation, which can, in turn, be used to optimize the devices to reduce the impact of these imperfections.
Training Dynamical Binary Neural Networks with Equilibrium Propagation
Mar 16, 2021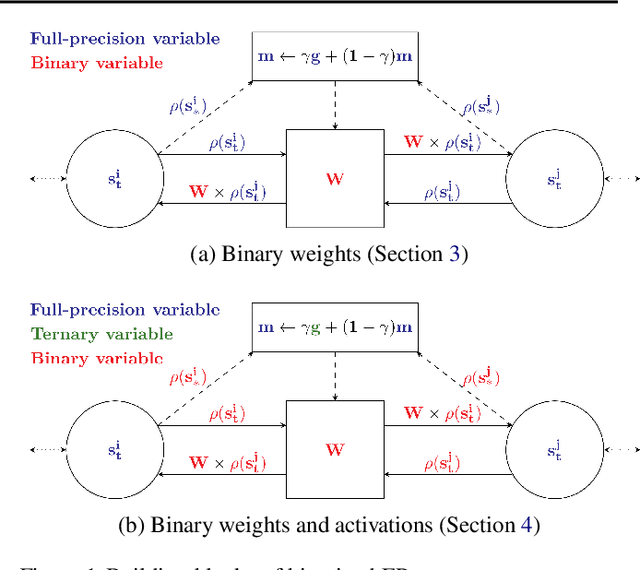
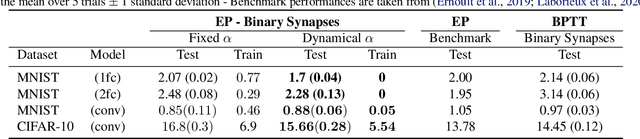
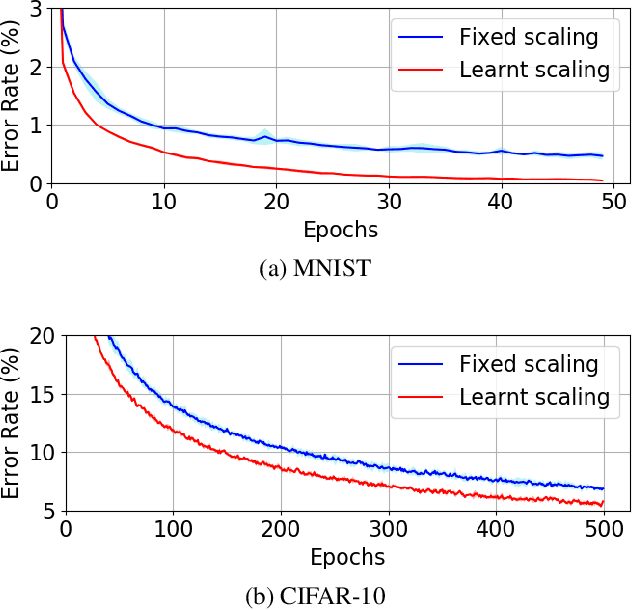
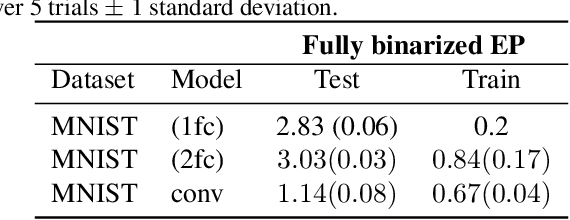
Equilibrium Propagation (EP) is an algorithm intrinsically adapted to the training of physical networks, in particular thanks to the local updates of weights given by the internal dynamics of the system. However, the construction of such a hardware requires to make the algorithm compatible with the existing neuromorphic CMOS technology, which generally exploits digital communication between neurons and offers a limited amount of local memory. In this work, we demonstrate that EP can train dynamical networks with binary activations and weights. We first train systems with binary weights and full-precision activations, achieving an accuracy equivalent to that of full-precision models trained by standard EP on MNIST, and losing only 1.9% accuracy on CIFAR-10 with equal architecture. We then extend our method to the training of models with binary activations and weights on MNIST, achieving an accuracy within 1% of the full-precision reference for fully connected architectures and reaching the full-precision reference accuracy for the convolutional architecture. Our extension of EP training to binary networks is consistent with the requirements of today's dynamic, brain-inspired hardware platforms and paves the way for very low-power end-to-end learning.