 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Efficient Learning with Low Resolution Stochastic Domain Wall Synapse Based Deep Neural Networks
Nov 14, 2021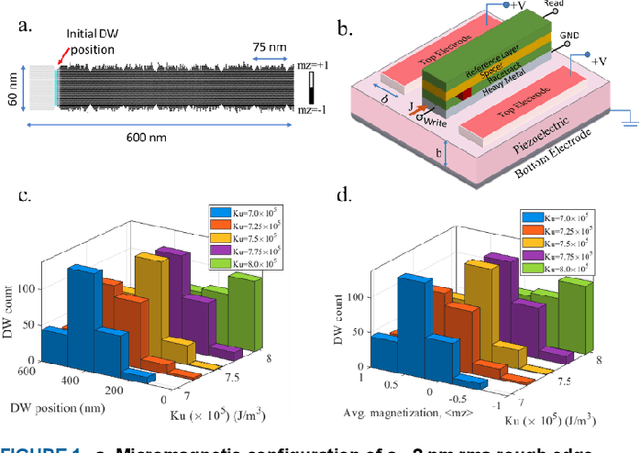
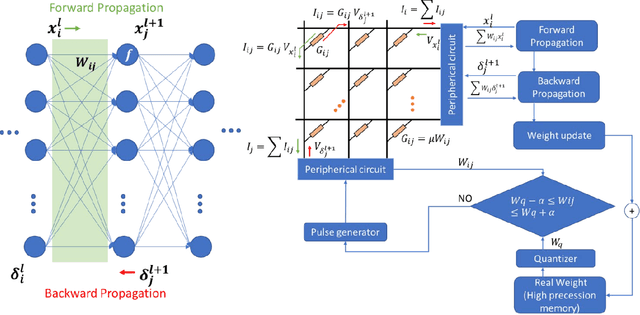
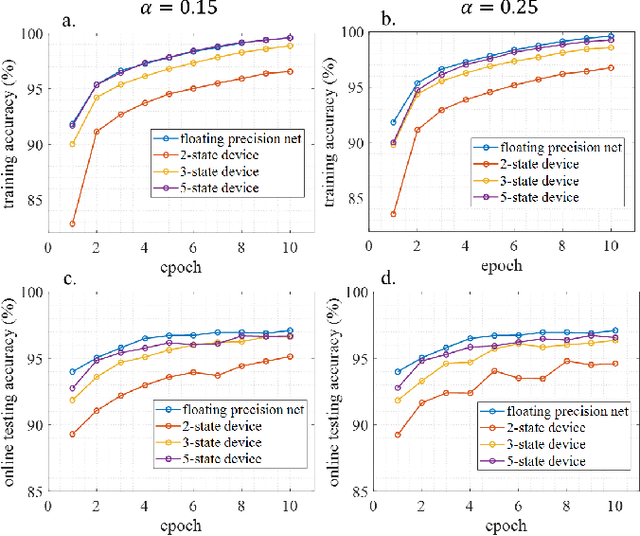
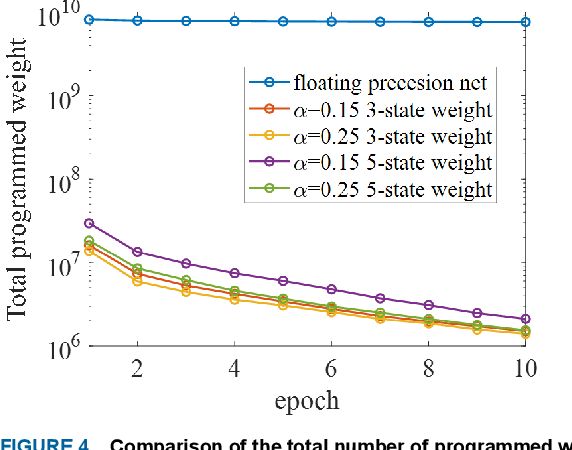
We demonstrate that extremely low resolution quantized (nominally 5-state) synapses with large stochastic variations in Domain Wall (DW) position can be both energy efficient and achieve reasonably high testing accuracies compared to Deep Neural Networks (DNNs) of similar sizes using floating precision synaptic weights. Specifically, voltage controlled DW devices demonstrate stochastic behavior as modeled rigorously with micromagnetic simulations and can only encode limited states; however, they can be extremely energy efficient during both training and inference. We show that by implementing suitable modifications to the learning algorithms, we can address the stochastic behavior as well as mitigate the effect of their low-resolution to achieve high testing accuracies. In this study, we propose both in-situ and ex-situ training algorithms, based on modification of the algorithm proposed by Hubara et al. [1] which works well with quantization of synaptic weights. We train several 5-layer DNNs on MNIST dataset using 2-, 3- and 5-state DW device as synapse. For in-situ training, a separate high precision memory unit is adopted to preserve and accumulate the weight gradients, which are then quantized to program the low precision DW devices. Moreover, a sizeable noise tolerance margin is used during the training to address the intrinsic programming noise. For ex-situ training, a precursor DNN is first trained based on the characterized DW device model and a noise tolerance margin, which is similar to the in-situ training. Remarkably, for in-situ inference the energy dissipation to program the devices is only 13 pJ per inference given that the training is performed over the entire MNIST dataset for 10 epochs.