 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Non-Volatile Nanomagnetic Synapse based Autoencoder for Efficient Unsupervised Network Anomaly Detection
Sep 12, 2023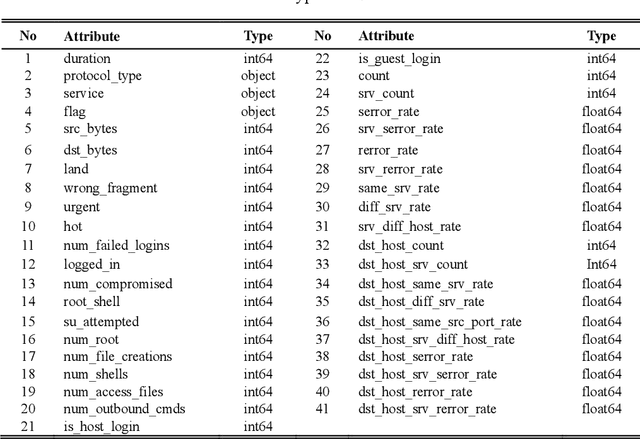
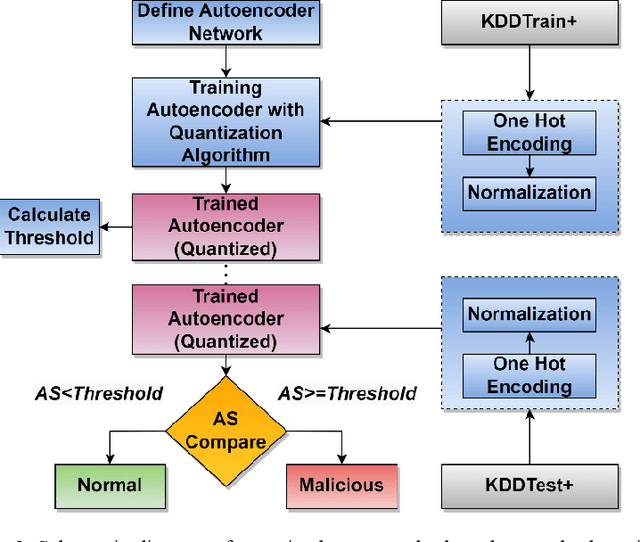
In the autoencoder based anomaly detection paradigm, implementing the autoencoder in edge devices capable of learning in real-time is exceedingly challenging due to limited hardware, energy, and computational resources. We show that these limitations can be addressed by designing an autoencoder with low-resolution non-volatile memory-based synapses and employing an effective quantized neural network learning algorithm. We propose a ferromagnetic racetrack with engineered notches hosting a magnetic domain wall (DW) as the autoencoder synapses, where limited state (5-state) synaptic weights are manipulated by spin orbit torque (SOT) current pulses. The performance of anomaly detection of the proposed autoencoder model is evaluated on the NSL-KDD dataset. Limited resolution and DW device stochasticity aware training of the autoencoder is performed, which yields comparable anomaly detection performance to the autoencoder having floating-point precision weights. While the limited number of quantized states and the inherent stochastic nature of DW synaptic weights in nanoscale devices are known to negatively impact the performance, our hardware-aware training algorithm is shown to leverage these imperfect device characteristics to generate an improvement in anomaly detection accuracy (90.98%) compared to accuracy obtained with floating-point trained weights. Furthermore, our DW-based approach demonstrates a remarkable reduction of at least three orders of magnitude in weight updates during training compared to the floating-point approach, implying substantial energy savings for our method. This work could stimulate the development of extremely energy efficient non-volatile multi-state synapse-based processors that can perform real-time training and inference on the edge with unsupervised data.
Spintronic Physical Reservoir for Autonomous Prediction and Long-Term Household Energy Load Forecasting
Apr 06, 2023In this study, we have shown autonomous long-term prediction with a spintronic physical reservoir. Due to the short-term memory property of the magnetization dynamics, non-linearity arises in the reservoir states which could be used for long-term prediction tasks using simple linear regression for online training. During the prediction stage, the output is directly fed to the input of the reservoir for autonomous prediction. We employ our proposed reservoir for the modeling of the chaotic time series such as Mackey-Glass and dynamic time-series data, such as household building energy loads. Since only the last layer of a RC needs to be trained with linear regression, it is well suited for learning in real time on edge devices. Here we show that a skyrmion based magnetic tunnel junction can potentially be used as a prototypical RC but any nanomagnetic magnetic tunnel junction with nonlinear magnetization behavior can implement such a RC. By comparing our spintronic physical RC approach with state-of-the-art energy load forecasting algorithms, such as LSTMs and RNNs, we conclude that the proposed framework presents good performance in achieving high predictions accuracy, while also requiring low memory and energy both of which are at a premium in hardware resource and power constrained edge applications. Further, the proposed approach is shown to require very small training datasets and at the same time being at least 16X energy efficient compared to the state-of-the-art sequence to sequence LSTM for accurate household load predictions.
Energy Efficient Learning with Low Resolution Stochastic Domain Wall Synapse Based Deep Neural Networks
Nov 14, 2021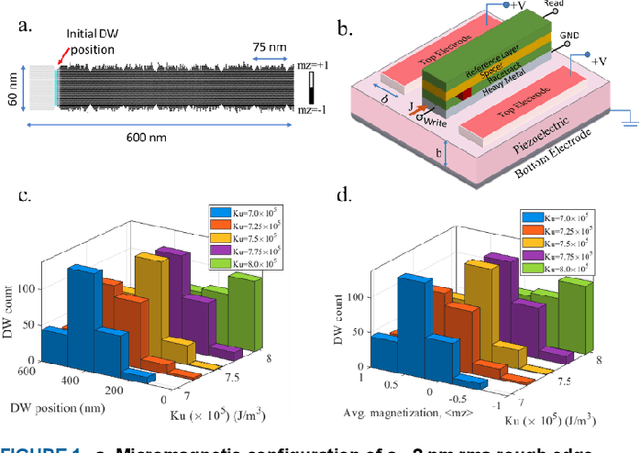
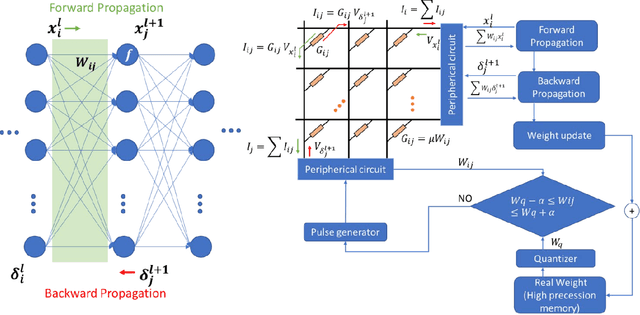
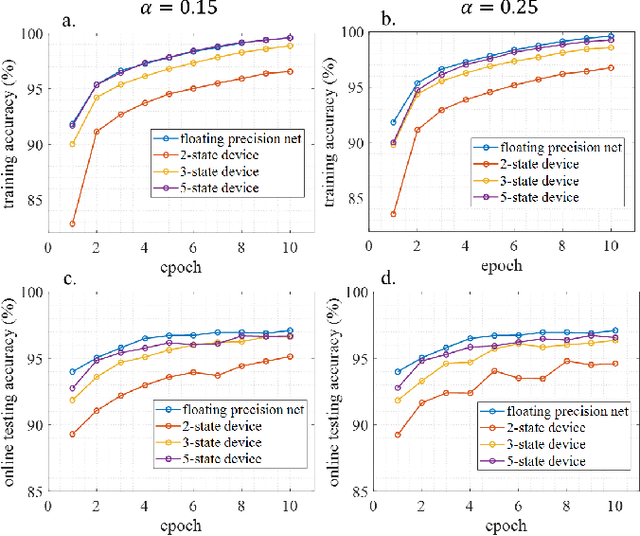
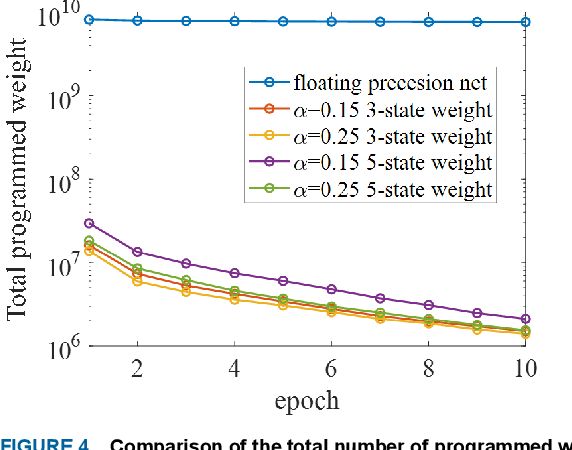
We demonstrate that extremely low resolution quantized (nominally 5-state) synapses with large stochastic variations in Domain Wall (DW) position can be both energy efficient and achieve reasonably high testing accuracies compared to Deep Neural Networks (DNNs) of similar sizes using floating precision synaptic weights. Specifically, voltage controlled DW devices demonstrate stochastic behavior as modeled rigorously with micromagnetic simulations and can only encode limited states; however, they can be extremely energy efficient during both training and inference. We show that by implementing suitable modifications to the learning algorithms, we can address the stochastic behavior as well as mitigate the effect of their low-resolution to achieve high testing accuracies. In this study, we propose both in-situ and ex-situ training algorithms, based on modification of the algorithm proposed by Hubara et al. [1] which works well with quantization of synaptic weights. We train several 5-layer DNNs on MNIST dataset using 2-, 3- and 5-state DW device as synapse. For in-situ training, a separate high precision memory unit is adopted to preserve and accumulate the weight gradients, which are then quantized to program the low precision DW devices. Moreover, a sizeable noise tolerance margin is used during the training to address the intrinsic programming noise. For ex-situ training, a precursor DNN is first trained based on the characterized DW device model and a noise tolerance margin, which is similar to the in-situ training. Remarkably, for in-situ inference the energy dissipation to program the devices is only 13 pJ per inference given that the training is performed over the entire MNIST dataset for 10 epochs.
Frustrated Arrays of Nanomagnets for Efficient Reservoir Computing
Mar 16, 2021


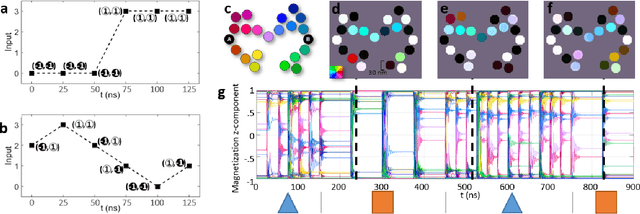
We simulated our nanomagnet reservoir computer (NMRC) design on benchmark tasks, demonstrating NMRC's high memory content and expressibility. In support of the feasibility of this method, we fabricated a frustrated nanomagnet reservoir layer. Using this structure, we describe a low-power, low-area system with an area-energy-delay product $10^7$ lower than conventional RC systems, that is therefore promising for size, weight, and power (SWaP) constrained applications.