 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPREAD: Subspace Representation Distillation for Lifelong Imitation Learning
Mar 09, 2026A key challenge in lifelong imitation learning (LIL) is enabling agents to acquire new skills from expert demonstrations while retaining prior knowledge. This requires preserving the low-dimensional manifolds and geometric structures that underlie task representations across sequential learning. Existing distillation methods, which rely on L2-norm feature matching in raw feature space, are sensitive to noise and high-dimensional variability, often failing to preserve intrinsic task manifolds. To address this, we introduce SPREAD, a geometry-preserving framework that employs singular value decomposition (SVD) to align policy representations across tasks within low-rank subspaces. This alignment maintains the underlying geometry of multimodal features, facilitating stable transfer, robustness, and generalization. Additionally, we propose a confidence-guided distillation strategy that applies a Kullback-Leibler divergence loss restricted to the top-M most confident action samples, emphasizing reliable modes and improving optimization stability. Experiments on the LIBERO, lifelong imitation learning benchmark, show that SPREAD substantially improves knowledge transfer, mitigates catastrophic forgetting, and achieves state-of-the-art performance.
WildCross: A Cross-Modal Large Scale Benchmark for Place Recognition and Metric Depth Estimation in Natural Environments
Mar 02, 2026Recent years have seen a significant increase in demand for robotic solutions in unstructured natural environments, alongside growing interest in bridging 2D and 3D scene understanding. However, existing robotics datasets are predominantly captured in structured urban environments, making them inadequate for addressing the challenges posed by complex, unstructured natural settings. To address this gap, we propose WildCross, a cross-modal benchmark for place recognition and metric depth estimation in large-scale natural environments. WildCross comprises over 476K sequential RGB frames with semi-dense depth and surface normal annotations, each aligned with accurate 6DoF poses and synchronized dense lidar submaps. We conduct comprehensive experiments on visual, lidar, and cross-modal place recognition, as well as metric depth estimation, demonstrating the value of WildCross as a challenging benchmark for multi-modal robotic perception tasks. We provide access to the code repository and dataset at https://csiro-robotics.github.io/WildCross.
SWE-Adept: An LLM-Based Agentic Framework for Deep Codebase Analysis and Structured Issue Resolution
Mar 01, 2026Large language models (LLMs) exhibit strong performance on self-contained programming tasks. However, they still struggle with repository-level software engineering (SWE), which demands (1) deep codebase navigation with effective context management for accurate localization, and (2) systematic approaches for iterative, test-driven code modification to resolve issues. To address these challenges, we propose SWE-Adept, an LLM-based two-agent framework where a localization agent identifies issue-relevant code locations and a resolution agent implements the corresponding fixes. For issue localization, we introduce agent-directed depth-first search that selectively traverses code dependencies. This minimizes issue-irrelevant content in the agent's context window and improves localization accuracy. For issue resolution, we employ adaptive planning and structured problem solving. We equip the agent with specialized tools for progress tracking and Git-based version control. These tools interface with a shared working memory that stores code-state checkpoints indexed by execution steps, facilitating precise checkpoint retrieval. This design enables reliable agent-driven version-control operations for systematic issue resolution, including branching to explore alternative solutions and reverting failed edits. Experiments on SWE-Bench Lite and SWE-Bench Pro demonstrate that SWE-Adept consistently outperforms prior approaches in both issue localization and resolution, improving the end-to-end resolve rate by up to 4.7%.
Loss Knows Best: Detecting Annotation Errors in Videos via Loss Trajectories
Feb 16, 2026High-quality video datasets are foundational for training robust models in tasks like action recognition, phase detection, and event segmentation. However, many real-world video datasets suffer from annotation errors such as *mislabeling*, where segments are assigned incorrect class labels, and *disordering*, where the temporal sequence does not follow the correct progression. These errors are particularly harmful in phase-annotated tasks, where temporal consistency is critical. We propose a novel, model-agnostic method for detecting annotation errors by analyzing the Cumulative Sample Loss (CSL)--defined as the average loss a frame incurs when passing through model checkpoints saved across training epochs. This per-frame loss trajectory acts as a dynamic fingerprint of frame-level learnability. Mislabeled or disordered frames tend to show consistently high or irregular loss patterns, as they remain difficult for the model to learn throughout training, while correctly labeled frames typically converge to low loss early. To compute CSL, we train a video segmentation model and store its weights at each epoch. These checkpoints are then used to evaluate the loss of each frame in a test video. Frames with persistently high CSL are flagged as likely candidates for annotation errors, including mislabeling or temporal misalignment. Our method does not require ground truth on annotation errors and is generalizable across datasets. Experiments on EgoPER and Cholec80 demonstrate strong detection performance, effectively identifying subtle inconsistencies such as mislabeling and frame disordering. The proposed approach provides a powerful tool for dataset auditing and improving training reliability in video-based machine learning.
TraceNAS: Zero-shot LLM Pruning via Gradient Trace Correlation
Feb 02, 2026Structured pruning is essential for efficient deployment of Large Language Models (LLMs). The varying sensitivity of LLM sub-blocks to pruning necessitates the identification of optimal non-uniformly pruned models. Existing methods evaluate the importance of layers, attention heads, or weight channels in isolation. Such localized focus ignores the complex global structural dependencies that exist across the model. Training-aware structured pruning addresses global dependencies, but its computational cost can be just as expensive as post-pruning training. To alleviate the computational burden of training-aware pruning and capture global structural dependencies, we propose TraceNAS, a training-free Neural Architecture Search (NAS) framework that jointly explores structured pruning of LLM depth and width. TraceNAS identifies pruned models that maintain a high degree of loss landscape alignment with the pretrained model using a scale-invariant zero-shot proxy, effectively selecting models that exhibit maximal performance potential during post-pruning training. TraceNAS is highly efficient, enabling high-fidelity discovery of pruned models on a single GPU in 8.5 hours, yielding a 10$\times$ reduction in GPU-hours compared to training-aware methods. Evaluations on the Llama and Qwen families demonstrate that TraceNAS is competitive with training-aware baselines across commonsense and reasoning benchmarks.
TopoPrune: Robust Data Pruning via Unified Latent Space Topology
Feb 02, 2026Geometric data pruning methods, while practical for leveraging pretrained models, are fundamentally unstable. Their reliance on extrinsic geometry renders them highly sensitive to latent space perturbations, causing performance to degrade during cross-architecture transfer or in the presence of feature noise. We introduce TopoPrune, a framework which resolves this challenge by leveraging topology to capture the stable, intrinsic structure of data. TopoPrune operates at two scales, (1) utilizing a topology-aware manifold approximation to establish a global low-dimensional embedding of the dataset. Subsequently, (2) it employs differentiable persistent homology to perform a local topological optimization on the manifold embeddings, ranking samples by their structural complexity. We demonstrate that our unified dual-scale topological approach ensures high accuracy and precision, particularly at significant dataset pruning rates (e.g., 90%). Furthermore, through the inherent stability properties of topology, TopoPrune is (a) exceptionally robust to noise perturbations of latent feature embeddings and (b) demonstrates superior transferability across diverse network architectures. This study demonstrates a promising avenue towards stable and principled topology-based frameworks for robust data-efficient learning.
ELLA: Efficient Lifelong Learning for Adapters in Large Language Models
Jan 07, 2026Large Language Models (LLMs) suffer severe catastrophic forgetting when adapted sequentially to new tasks in a continual learning (CL) setting. Existing approaches are fundamentally limited: replay-based methods are impractical and privacy-violating, while strict orthogonality-based methods collapse under scale: each new task is projected onto an orthogonal complement, progressively reducing the residual degrees of freedom and eliminating forward transfer by forbidding overlap in shared representations. In this work, we introduce ELLA, a training framework built on the principle of selective subspace de-correlation. Rather than forbidding all overlap, ELLA explicitly characterizes the structure of past updates and penalizes alignments along their high-energy, task-specific directions, while preserving freedom in the low-energy residual subspaces to enable transfer. Formally, this is realized via a lightweight regularizer on a single aggregated update matrix. We prove this mechanism corresponds to an anisotropic shrinkage operator that bounds interference, yielding a penalty that is both memory- and compute-constant regardless of task sequence length. ELLA requires no data replay, no architectural expansion, and negligible storage. Empirically, it achieves state-of-the-art CL performance on three popular benchmarks, with relative accuracy gains of up to $9.6\%$ and a $35\times$ smaller memory footprint. Further, ELLA scales robustly across architectures and actively enhances the model's zero-shot generalization performance on unseen tasks, establishing a principled and scalable solution for constructive lifelong LLM adaptation.
AgriRegion: Region-Aware Retrieval for High-Fidelity Agricultural Advice
Dec 10, 2025Large Language Models (LLMs) have demonstrated significant potential in democratizing access to information. However, in the domain of agriculture, general-purpose models frequently suffer from contextual hallucination, which provides non-factual advice or answers are scientifically sound in one region but disastrous in another due to variations in soil, climate, and local regulations. We introduce AgriRegion, a Retrieval-Augmented Generation (RAG) framework designed specifically for high-fidelity, region-aware agricultural advisory. Unlike standard RAG approaches that rely solely on semantic similarity, AgriRegion incorporates a geospatial metadata injection layer and a region-prioritized re-ranking mechanism. By restricting the knowledge base to verified local agricultural extension services and enforcing geo-spatial constraints during retrieval, AgriRegion ensures that the advice regarding planting schedules, pest control, and fertilization is locally accurate. We create a novel benchmark dataset, AgriRegion-Eval, which comprises 160 domain-specific questions across 12 agricultural subfields. Experiments demonstrate that AgriRegion reduces hallucinations by 10-20% compared to state-of-the-art LLMs systems and significantly improves trust scores according to a comprehensive evaluation.
TRIM: Token-wise Attention-Derived Saliency for Data-Efficient Instruction Tuning
Oct 08, 2025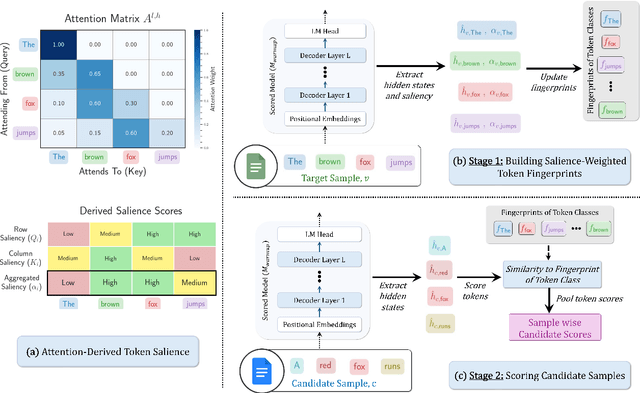
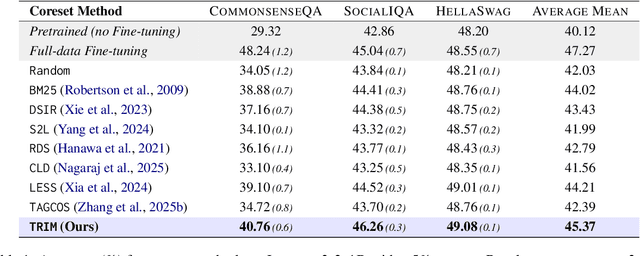
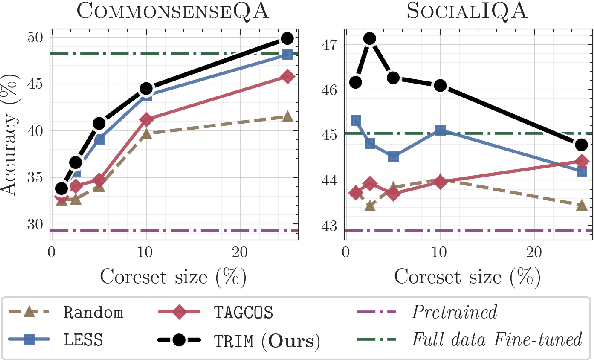

Instruction tuning is essential for aligning large language models (LLMs) to downstream tasks and commonly relies on large, diverse corpora. However, small, high-quality subsets, known as coresets, can deliver comparable or superior results, though curating them remains challenging. Existing methods often rely on coarse, sample-level signals like gradients, an approach that is computationally expensive and overlooks fine-grained features. To address this, we introduce TRIM (Token Relevance via Interpretable Multi-layer Attention), a forward-only, token-centric framework. Instead of using gradients, TRIM operates by matching underlying representational patterns identified via attention-based "fingerprints" from a handful of target samples. Such an approach makes TRIM highly efficient and uniquely sensitive to the structural features that define a task. Coresets selected by our method consistently outperform state-of-the-art baselines by up to 9% on downstream tasks and even surpass the performance of full-data fine-tuning in some settings. By avoiding expensive backward passes, TRIM achieves this at a fraction of the computational cost. These findings establish TRIM as a scalable and efficient alternative for building high-quality instruction-tuning datasets.
FedP3E: Privacy-Preserving Prototype Exchange for Non-IID IoT Malware Detection in Cross-Silo Federated Learning
Jul 09, 2025As IoT ecosystems continue to expand across critical sectors, they have become prominent targets for increasingly sophisticated and large-scale malware attacks. The evolving threat landscape, combined with the sensitive nature of IoT-generated data, demands detection frameworks that are both privacy-preserving and resilient to data heterogeneity. Federated Learning (FL) offers a promising solution by enabling decentralized model training without exposing raw data. However, standard FL algorithms such as FedAvg and FedProx often fall short in real-world deployments characterized by class imbalance and non-IID data distributions -- particularly in the presence of rare or disjoint malware classes. To address these challenges, we propose FedP3E (Privacy-Preserving Prototype Exchange), a novel FL framework that supports indirect cross-client representation sharing while maintaining data privacy. Each client constructs class-wise prototypes using Gaussian Mixture Models (GMMs), perturbs them with Gaussian noise, and transmits only these compact summaries to the server. The aggregated prototypes are then distributed back to clients and integrated into local training, supported by SMOTE-based augmentation to enhance representation of minority malware classes. Rather than relying solely on parameter averaging, our prototype-driven mechanism enables clients to enrich their local models with complementary structural patterns observed across the federation -- without exchanging raw data or gradients. This targeted strategy reduces the adverse impact of statistical heterogeneity with minimal communication overhead. We evaluate FedP3E on the N-BaIoT dataset under realistic cross-silo scenarios with varying degrees of data imbalance.