 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scalable Modeling of Compressed Videos for Efficient Action Recognition
Paper and Code
Mar 17, 2025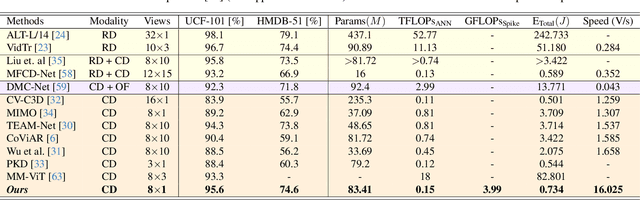
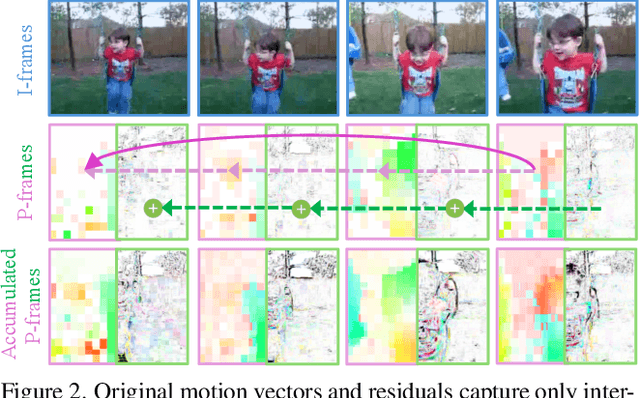

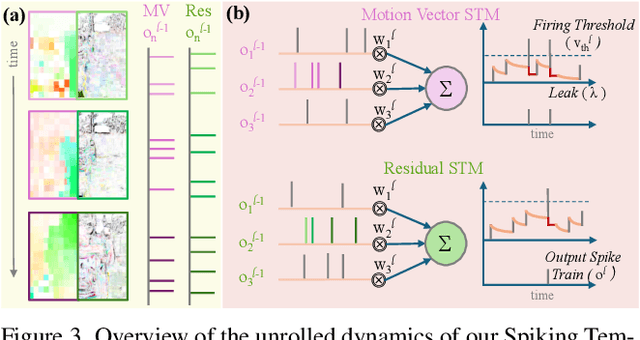
Training robust deep video representations has proven to be computationally challenging due to substantial decoding overheads, the enormous size of raw video streams, and their inherent high temporal redundancy. Different from existing schemes, operating exclusively in the compressed video domain and exploiting all freely available modalities, i.e., I-frames, and P-frames (motion vectors and residuals) offers a compute-efficient alternative. Existing methods approach this task as a naive multi-modality problem, ignoring the temporal correlation and implicit sparsity across P-frames for modeling stronger shared representations for videos of the same action, making training and generalization easier. By revisiting the high-level design of dominant video understanding backbones, we increase inference speed by a factor of $56$ while retaining similar performance. For this, we propose a hybrid end-to-end framework that factorizes learning across three key concepts to reduce inference cost by $330\times$ versus prior art: First, a specially designed dual-encoder scheme with efficient Spiking Temporal Modulators to minimize latency while retaining cross-domain feature aggregation. Second, a unified transformer model to capture inter-modal dependencies using global self-attention to enhance I-frame -- P-frame contextual interactions. Third, a Multi-Modal Mixer Block to model rich representations from the joint spatiotemporal token embeddings. Experiments show that our method results in a lightweight architecture achieving state-of-the-art video recognition performance on UCF-101, HMDB-51, K-400, K-600 and SS-v2 datasets with favorable costs ($0.73$J/V) and fast inference ($16$V/s). Our observations bring new insights into practical design choices for efficient next-generation spatiotemporal learners. Code is available.