 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELLA: Efficient Lifelong Learning for Adapters in Large Language Models
Jan 07, 2026Large Language Models (LLMs) suffer severe catastrophic forgetting when adapted sequentially to new tasks in a continual learning (CL) setting. Existing approaches are fundamentally limited: replay-based methods are impractical and privacy-violating, while strict orthogonality-based methods collapse under scale: each new task is projected onto an orthogonal complement, progressively reducing the residual degrees of freedom and eliminating forward transfer by forbidding overlap in shared representations. In this work, we introduce ELLA, a training framework built on the principle of selective subspace de-correlation. Rather than forbidding all overlap, ELLA explicitly characterizes the structure of past updates and penalizes alignments along their high-energy, task-specific directions, while preserving freedom in the low-energy residual subspaces to enable transfer. Formally, this is realized via a lightweight regularizer on a single aggregated update matrix. We prove this mechanism corresponds to an anisotropic shrinkage operator that bounds interference, yielding a penalty that is both memory- and compute-constant regardless of task sequence length. ELLA requires no data replay, no architectural expansion, and negligible storage. Empirically, it achieves state-of-the-art CL performance on three popular benchmarks, with relative accuracy gains of up to $9.6\%$ and a $35\times$ smaller memory footprint. Further, ELLA scales robustly across architectures and actively enhances the model's zero-shot generalization performance on unseen tasks, establishing a principled and scalable solution for constructive lifelong LLM adaptation.
CURE: Concept Unlearning via Orthogonal Representation Editing in Diffusion Models
May 19, 2025As Text-to-Image models continue to evolve, so does the risk of generating unsafe, copyrighted, or privacy-violating content. Existing safety interventions - ranging from training data curation and model fine-tuning to inference-time filtering and guidance - often suffer from incomplete concept removal, susceptibility to jail-breaking, computational inefficiency, or collateral damage to unrelated capabilities. In this paper, we introduce CURE, a training-free concept unlearning framework that operates directly in the weight space of pre-trained diffusion models, enabling fast, interpretable, and highly specific suppression of undesired concepts. At the core of our method is the Spectral Eraser, a closed-form, orthogonal projection module that identifies discriminative subspaces using Singular Value Decomposition over token embeddings associated with the concepts to forget and retain. Intuitively, the Spectral Eraser identifies and isolates features unique to the undesired concept while preserving safe attributes. This operator is then applied in a single step update to yield an edited model in which the target concept is effectively unlearned - without retraining, supervision, or iterative optimization. To balance the trade-off between filtering toxicity and preserving unrelated concepts, we further introduce an Expansion Mechanism for spectral regularization which selectively modulates singular vectors based on their relative significance to control the strength of forgetting. All the processes above are in closed-form, guaranteeing extremely efficient erasure in only $2$ seconds. Benchmarking against prior approaches, CURE achieves a more efficient and thorough removal for targeted artistic styles, objects, identities, or explicit content, with minor damage to original generation ability and demonstrates enhanced robustness against red-teaming.
Towards Scalable Modeling of Compressed Videos for Efficient Action Recognition
Mar 17, 2025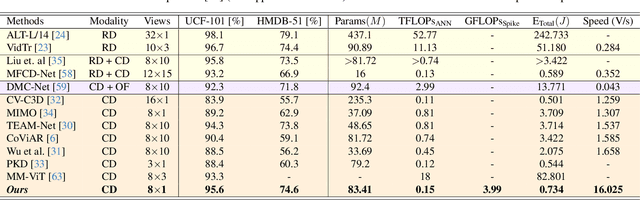
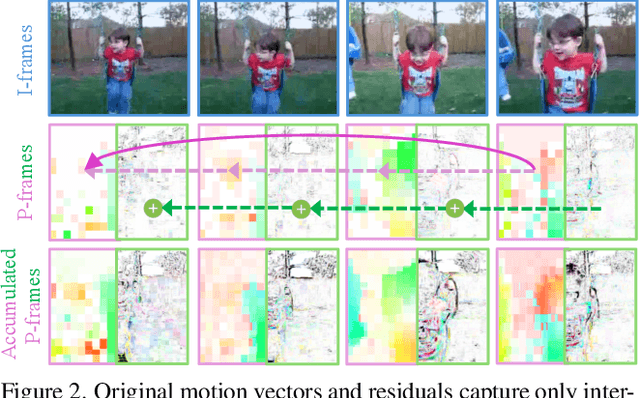

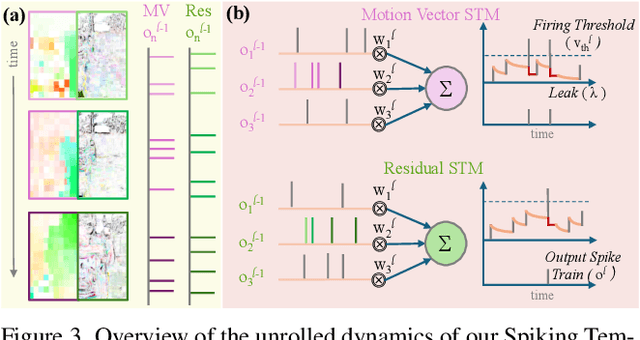
Training robust deep video representations has proven to be computationally challenging due to substantial decoding overheads, the enormous size of raw video streams, and their inherent high temporal redundancy. Different from existing schemes, operating exclusively in the compressed video domain and exploiting all freely available modalities, i.e., I-frames, and P-frames (motion vectors and residuals) offers a compute-efficient alternative. Existing methods approach this task as a naive multi-modality problem, ignoring the temporal correlation and implicit sparsity across P-frames for modeling stronger shared representations for videos of the same action, making training and generalization easier. By revisiting the high-level design of dominant video understanding backbones, we increase inference speed by a factor of $56$ while retaining similar performance. For this, we propose a hybrid end-to-end framework that factorizes learning across three key concepts to reduce inference cost by $330\times$ versus prior art: First, a specially designed dual-encoder scheme with efficient Spiking Temporal Modulators to minimize latency while retaining cross-domain feature aggregation. Second, a unified transformer model to capture inter-modal dependencies using global self-attention to enhance I-frame -- P-frame contextual interactions. Third, a Multi-Modal Mixer Block to model rich representations from the joint spatiotemporal token embeddings. Experiments show that our method results in a lightweight architecture achieving state-of-the-art video recognition performance on UCF-101, HMDB-51, K-400, K-600 and SS-v2 datasets with favorable costs ($0.73$J/V) and fast inference ($16$V/s). Our observations bring new insights into practical design choices for efficient next-generation spatiotemporal learners. Code is available.
HALSIE - Hybrid Approach to Learning Segmentation by Simultaneously Exploiting Image and Event Modalities
Nov 22, 2022Standard frame-based algorithms fail to retrieve accurate segmentation maps in challenging real-time applications like autonomous navigation, owing to the limited dynamic range and motion blur prevalent in traditional cameras. Event cameras address these limitations by asynchronously detecting changes in per-pixel intensity to generate event streams with high temporal resolution, high dynamic range, and no motion blur. However, event camera outputs cannot be directly used to generate reliable segmentation maps as they only capture information at the pixels in motion. To augment the missing contextual information, we postulate that fusing spatially dense frames with temporally dense events can generate semantic maps with fine-grained predictions. To this end, we propose HALSIE, a hybrid approach to learning segmentation by simultaneously leveraging image and event modalities. To enable efficient learning across modalities, our proposed hybrid framework comprises two input branches, a Spiking Neural Network (SNN) branch and a standard Artificial Neural Network (ANN) branch to process event and frame data respectively, while exploiting their corresponding neural dynamics. Our hybrid network outperforms the state-of-the-art semantic segmentation benchmarks on DDD17 and MVSEC datasets and shows comparable performance on the DSEC-Semantic dataset with upto 33.23$\times$ reduction in network parameters. Further, our method shows upto 18.92$\times$ improvement in inference cost compared to existing SOTA approaches, making it suitable for resource-constrained edge applications.