 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldFlow3D: Flowing Through 3D Distributions for Unbounded World Generation
Mar 31, 2026Unbounded 3D world generation is emerging as a foundational task for scene modeling in computer vision, graphics, and robotics. In this work, we present WorldFlow3D, a novel method capable of generating unbounded 3D worlds. Building upon a foundational property of flow matching - namely, defining a path of transport between two data distributions - we model 3D generation more generally as a problem of flowing through 3D data distributions, not limited to conditional denoising. We find that our latent-free flow approach generates causal and accurate 3D structure, and can use this as an intermediate distribution to guide the generation of more complex structure and high-quality texture - all while converging more rapidly than existing methods. We enable controllability over generated scenes with vectorized scene layout conditions for geometric structure control and visual texture control through scene attributes. We confirm the effectiveness of WorldFlow3D on both real outdoor driving scenes and synthetic indoor scenes, validating cross-domain generalizability and high-quality generation on real data distributions. We confirm favorable scene generation fidelity over approaches in all tested settings for unbounded scene generation. For more, see https://light.princeton.edu/worldflow3d.
LSD-3D: Large-Scale 3D Driving Scene Generation with Geometry Grounding
Aug 26, 2025Large-scale scene data is essential for training and testing in robot learning. Neural reconstruction methods have promised the capability of reconstructing large physically-grounded outdoor scenes from captured sensor data. However, these methods have baked-in static environments and only allow for limited scene control -- they are functionally constrained in scene and trajectory diversity by the captures from which they are reconstructed. In contrast, generating driving data with recent image or video diffusion models offers control, however, at the cost of geometry grounding and causality. In this work, we aim to bridge this gap and present a method that directly generates large-scale 3D driving scenes with accurate geometry, allowing for causal novel view synthesis with object permanence and explicit 3D geometry estimation. The proposed method combines the generation of a proxy geometry and environment representation with score distillation from learned 2D image priors. We find that this approach allows for high controllability, enabling the prompt-guided geometry and high-fidelity texture and structure that can be conditioned on map layouts -- producing realistic and geometrically consistent 3D generations of complex driving scenes.
iNatAg: Multi-Class Classification Models Enabled by a Large-Scale Benchmark Dataset with 4.7M Images of 2,959 Crop and Weed Species
Mar 25, 2025Accurate identification of crop and weed species is critical for precision agriculture and sustainable farming. However, it remains a challenging task due to a variety of factors -- a high degree of visual similarity among species, environmental variability, and a continued lack of large, agriculture-specific image data. We introduce iNatAg, a large-scale image dataset which contains over 4.7 million images of 2,959 distinct crop and weed species, with precise annotations along the taxonomic hierarchy from binary crop/weed labels to specific species labels. Curated from the broader iNaturalist database, iNatAg contains data from every continent and accurately reflects the variability of natural image captures and environments. Enabled by this data, we train benchmark models built upon the Swin Transformer architecture and evaluate the impact of various modifications such as the incorporation of geospatial data and LoRA finetuning. Our best models achieve state-of-the-art performance across all taxonomic classification tasks, achieving 92.38\% on crop and weed classification. Furthermore, the scale of our dataset enables us to explore incorrect misclassifications and unlock new analytic possiblities for plant species. By combining large-scale species coverage, multi-task labels, and geographic diversity, iNatAg provides a new foundation for building robust, geolocation-aware agricultural classification systems. We release the iNatAg dataset publicly through AgML (https://github.com/Project-AgML/AgML), enabling direct access and integration into agricultural machine learning workflows.
Real-Time Neuromorphic Navigation: Guiding Physical Robots with Event-Based Sensing and Task-Specific Reconfigurable Autonomy Stack
Mar 11, 2025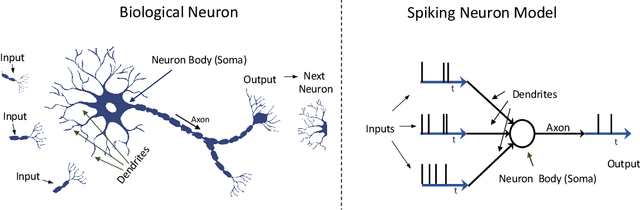
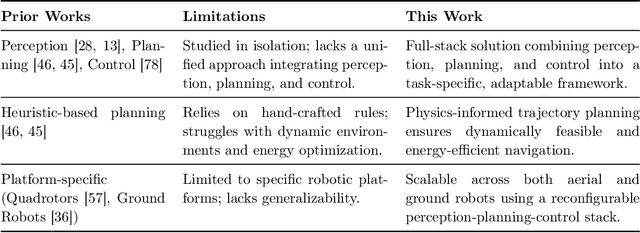
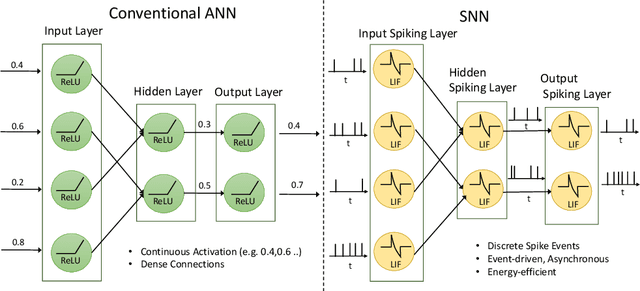
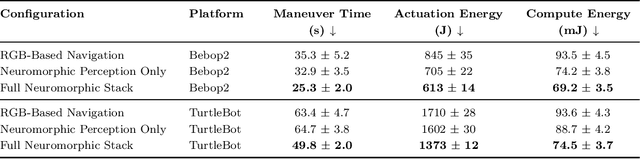
Neuromorphic vision, inspired by biological neural systems, has recently gained significant attention for its potential in enhancing robotic autonomy. This paper presents a systematic exploration of a proposed Neuromorphic Navigation framework that uses event-based neuromorphic vision to enable efficient, real-time navigation in robotic systems. We discuss the core concepts of neuromorphic vision and navigation, highlighting their impact on improving robotic perception and decision-making. The proposed reconfigurable Neuromorphic Navigation framework adapts to the specific needs of both ground robots (Turtlebot) and aerial robots (Bebop2 quadrotor), addressing the task-specific design requirements (algorithms) for optimal performance across the autonomous navigation stack -- Perception, Planning, and Control. We demonstrate the versatility and the effectiveness of the framework through two case studies: a Turtlebot performing local replanning for real-time navigation and a Bebop2 quadrotor navigating through moving gates. Our work provides a scalable approach to task-specific, real-time robot autonomy leveraging neuromorphic systems, paving the way for energy-efficient autonomous navigation.
Energy-Efficient Autonomous Aerial Navigation with Dynamic Vision Sensors: A Physics-Guided Neuromorphic Approach
Feb 09, 2025



Vision-based object tracking is a critical component for achieving autonomous aerial navigation, particularly for obstacle avoidance. Neuromorphic Dynamic Vision Sensors (DVS) or event cameras, inspired by biological vision, offer a promising alternative to conventional frame-based cameras. These cameras can detect changes in intensity asynchronously, even in challenging lighting conditions, with a high dynamic range and resistance to motion blur. Spiking neural networks (SNNs) are increasingly used to process these event-based signals efficiently and asynchronously. Meanwhile, physics-based artificial intelligence (AI) provides a means to incorporate system-level knowledge into neural networks via physical modeling. This enhances robustness, energy efficiency, and provides symbolic explainability. In this work, we present a neuromorphic navigation framework for autonomous drone navigation. The focus is on detecting and navigating through moving gates while avoiding collisions. We use event cameras for detecting moving objects through a shallow SNN architecture in an unsupervised manner. This is combined with a lightweight energy-aware physics-guided neural network (PgNN) trained with depth inputs to predict optimal flight times, generating near-minimum energy paths. The system is implemented in the Gazebo simulator and integrates a sensor-fused vision-to-planning neuro-symbolic framework built with the Robot Operating System (ROS) middleware. This work highlights the future potential of integrating event-based vision with physics-guided planning for energy-efficient autonomous navigation, particularly for low-latency decision-making.
Neuro-LIFT: A Neuromorphic, LLM-based Interactive Framework for Autonomous Drone FlighT at the Edge
Jan 31, 2025



The integration of human-intuitive interactions into autonomous systems has been limited. Traditional Natural Language Processing (NLP) systems struggle with context and intent understanding, severely restricting human-robot interaction. Recent advancements in Large Language Models (LLMs) have transformed this dynamic, allowing for intuitive and high-level communication through speech and text, and bridging the gap between human commands and robotic actions. Additionally, autonomous navigation has emerged as a central focus in robotics research, with artificial intelligence (AI) increasingly being leveraged to enhance these systems. However, existing AI-based navigation algorithms face significant challenges in latency-critical tasks where rapid decision-making is critical. Traditional frame-based vision systems, while effective for high-level decision-making, suffer from high energy consumption and latency, limiting their applicability in real-time scenarios. Neuromorphic vision systems, combining event-based cameras and spiking neural networks (SNNs), offer a promising alternative by enabling energy-efficient, low-latency navigation. Despite their potential, real-world implementations of these systems, particularly on physical platforms such as drones, remain scarce. In this work, we present Neuro-LIFT, a real-time neuromorphic navigation framework implemented on a Parrot Bebop2 quadrotor. Leveraging an LLM for natural language processing, Neuro-LIFT translates human speech into high-level planning commands which are then autonomously executed using event-based neuromorphic vision and physics-driven planning. Our framework demonstrates its capabilities in navigating in a dynamic environment, avoiding obstacles, and adapting to human instructions in real-time.
Understanding the Limits of Vision Language Models Through the Lens of the Binding Problem
Oct 31, 2024



Recent work has documented striking heterogeneity in the performance of state-of-the-art vision language models (VLMs), including both multimodal language models and text-to-image models. These models are able to describe and generate a diverse array of complex, naturalistic images, yet they exhibit surprising failures on basic multi-object reasoning tasks -- such as counting, localization, and simple forms of visual analogy -- that humans perform with near perfect accuracy. To better understand this puzzling pattern of successes and failures, we turn to theoretical accounts of the binding problem in cognitive science and neuroscience, a fundamental problem that arises when a shared set of representational resources must be used to represent distinct entities (e.g., to represent multiple objects in an image), necessitating the use of serial processing to avoid interference. We find that many of the puzzling failures of state-of-the-art VLMs can be explained as arising due to the binding problem, and that these failure modes are strikingly similar to the limitations exhibited by rapid, feedforward processing in the human brain.
Neural Light Spheres for Implicit Image Stitching and View Synthesis
Sep 26, 2024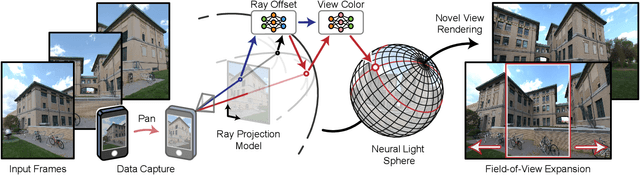
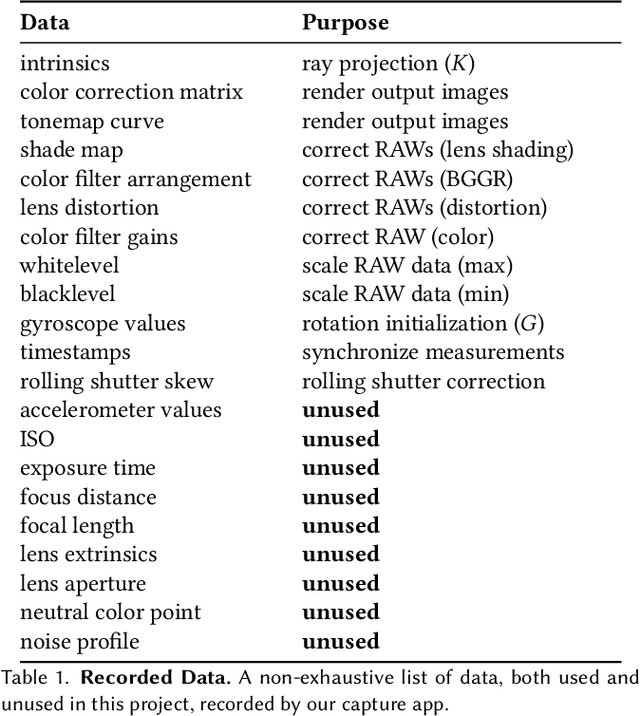
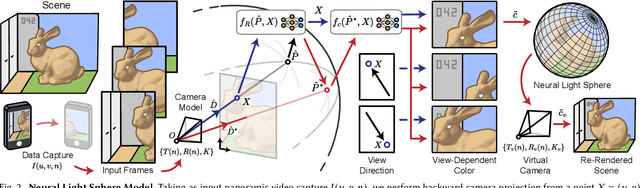
Challenging to capture, and challenging to display on a cellphone screen, the panorama paradoxically remains both a staple and underused feature of modern mobile camera applications. In this work we address both of these challenges with a spherical neural light field model for implicit panoramic image stitching and re-rendering; able to accommodate for depth parallax, view-dependent lighting, and local scene motion and color changes during capture. Fit during test-time to an arbitrary path panoramic video capture -- vertical, horizontal, random-walk -- these neural light spheres jointly estimate the camera path and a high-resolution scene reconstruction to produce novel wide field-of-view projections of the environment. Our single-layer model avoids expensive volumetric sampling, and decomposes the scene into compact view-dependent ray offset and color components, with a total model size of 80 MB per scene, and real-time (50 FPS) rendering at 1080p resolution. We demonstrate improved reconstruction quality over traditional image stitching and radiance field methods, with significantly higher tolerance to scene motion and non-ideal capture settings.
SHIRE: Enhancing Sample Efficiency using Human Intuition in REinforcement Learning
Sep 16, 2024The ability of neural networks to perform robotic perception and control tasks such as depth and optical flow estimation, simultaneous localization and mapping (SLAM), and automatic control has led to their widespread adoption in recent years. Deep Reinforcement Learning has been used extensively in these settings, as it does not have the unsustainable training costs associated with supervised learning. However, DeepRL suffers from poor sample efficiency, i.e., it requires a large number of environmental interactions to converge to an acceptable solution. Modern RL algorithms such as Deep Q Learning and Soft Actor-Critic attempt to remedy this shortcoming but can not provide the explainability required in applications such as autonomous robotics. Humans intuitively understand the long-time-horizon sequential tasks common in robotics. Properly using such intuition can make RL policies more explainable while enhancing their sample efficiency. In this work, we propose SHIRE, a novel framework for encoding human intuition using Probabilistic Graphical Models (PGMs) and using it in the Deep RL training pipeline to enhance sample efficiency. Our framework achieves 25-78% sample efficiency gains across the environments we evaluate at negligible overhead cost. Additionally, by teaching RL agents the encoded elementary behavior, SHIRE enhances policy explainability. A real-world demonstration further highlights the efficacy of policies trained using our framework.
Real-Time Neuromorphic Navigation: Integrating Event-Based Vision and Physics-Driven Planning on a Parrot Bebop2 Quadrotor
Jul 01, 2024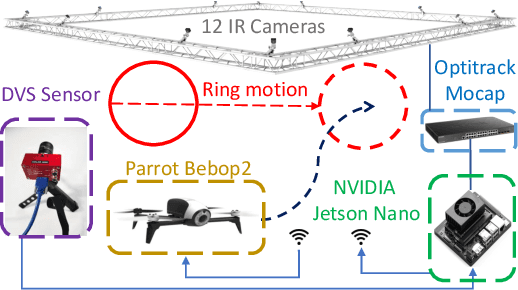
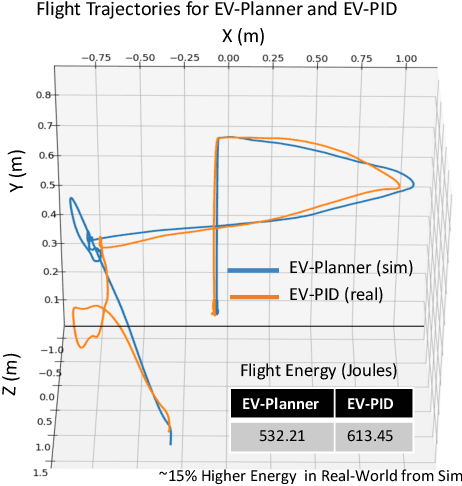
In autonomous aerial navigation, real-time and energy-efficient obstacle avoidance remains a significant challenge, especially in dynamic and complex indoor environments. This work presents a novel integration of neuromorphic event cameras with physics-driven planning algorithms implemented on a Parrot Bebop2 quadrotor. Neuromorphic event cameras, characterized by their high dynamic range and low latency, offer significant advantages over traditional frame-based systems, particularly in poor lighting conditions or during high-speed maneuvers. We use a DVS camera with a shallow Spiking Neural Network (SNN) for event-based object detection of a moving ring in real-time in an indoor lab. Further, we enhance drone control with physics-guided empirical knowledge inside a neural network training mechanism, to predict energy-efficient flight paths to fly through the moving ring. This integration results in a real-time, low-latency navigation system capable of dynamically responding to environmental changes while minimizing energy consumption. We detail our hardware setup, control loop, and modifications necessary for real-world applications, including the challenges of sensor integration without burdening the flight capabilities. Experimental results demonstrate the effectiveness of our approach in achieving robust, collision-free, and energy-efficient flight paths, showcasing the potential of neuromorphic vision and physics-driven planning in enhancing autonomous navigation systems.