 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Light Spheres for Implicit Image Stitching and View Synthesis
Sep 26, 2024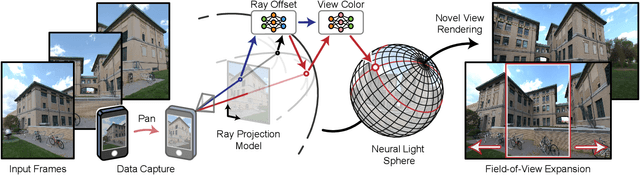
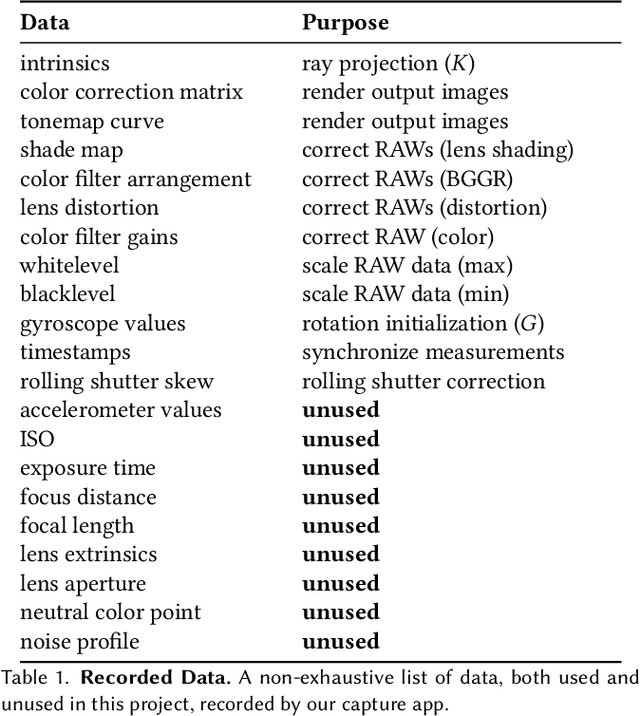
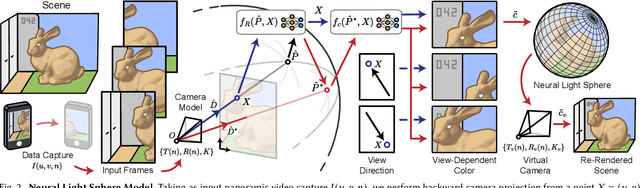
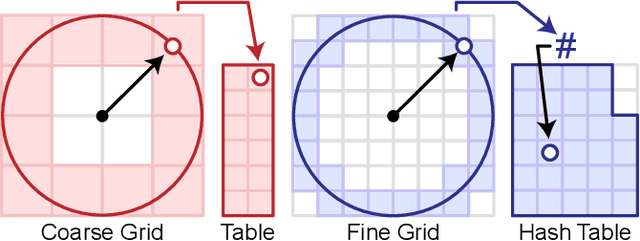
Challenging to capture, and challenging to display on a cellphone screen, the panorama paradoxically remains both a staple and underused feature of modern mobile camera applications. In this work we address both of these challenges with a spherical neural light field model for implicit panoramic image stitching and re-rendering; able to accommodate for depth parallax, view-dependent lighting, and local scene motion and color changes during capture. Fit during test-time to an arbitrary path panoramic video capture -- vertical, horizontal, random-walk -- these neural light spheres jointly estimate the camera path and a high-resolution scene reconstruction to produce novel wide field-of-view projections of the environment. Our single-layer model avoids expensive volumetric sampling, and decomposes the scene into compact view-dependent ray offset and color components, with a total model size of 80 MB per scene, and real-time (50 FPS) rendering at 1080p resolution. We demonstrate improved reconstruction quality over traditional image stitching and radiance field methods, with significantly higher tolerance to scene motion and non-ideal capture settings.
Neural Spline Fields for Burst Image Fusion and Layer Separation
Dec 21, 2023


Each photo in an image burst can be considered a sample of a complex 3D scene: the product of parallax, diffuse and specular materials, scene motion, and illuminant variation. While decomposing all of these effects from a stack of misaligned images is a highly ill-conditioned task, the conventional align-and-merge burst pipeline takes the other extreme: blending them into a single image. In this work, we propose a versatile intermediate representation: a two-layer alpha-composited image plus flow model constructed with neural spline fields -- networks trained to map input coordinates to spline control points. Our method is able to, during test-time optimization, jointly fuse a burst image capture into one high-resolution reconstruction and decompose it into transmission and obstruction layers. Then, by discarding the obstruction layer, we can perform a range of tasks including seeing through occlusions, reflection suppression, and shadow removal. Validated on complex synthetic and in-the-wild captures we find that, with no post-processing steps or learned priors, our generalizable model is able to outperform existing dedicated single-image and multi-view obstruction removal approaches.
Shakes on a Plane: Unsupervised Depth Estimation from Unstabilized Photography
Dec 22, 2022Modern mobile burst photography pipelines capture and merge a short sequence of frames to recover an enhanced image, but often disregard the 3D nature of the scene they capture, treating pixel motion between images as a 2D aggregation problem. We show that in a "long-burst", forty-two 12-megapixel RAW frames captured in a two-second sequence, there is enough parallax information from natural hand tremor alone to recover high-quality scene depth. To this end, we devise a test-time optimization approach that fits a neural RGB-D representation to long-burst data and simultaneously estimates scene depth and camera motion. Our plane plus depth model is trained end-to-end, and performs coarse-to-fine refinement by controlling which multi-resolution volume features the network has access to at what time during training. We validate the method experimentally, and demonstrate geometrically accurate depth reconstructions with no additional hardware or separate data pre-processing and pose-estimation steps.
GenSDF: Two-Stage Learning of Generalizable Signed Distance Functions
Jun 06, 2022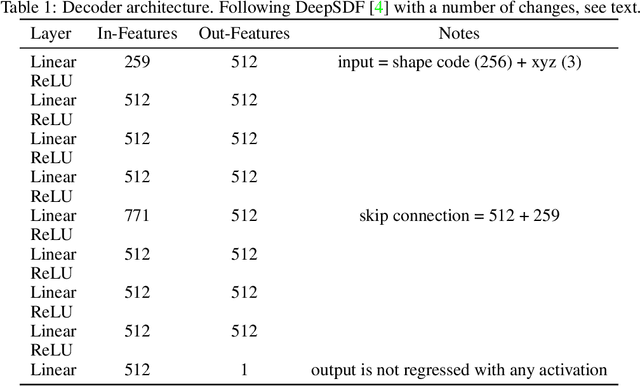
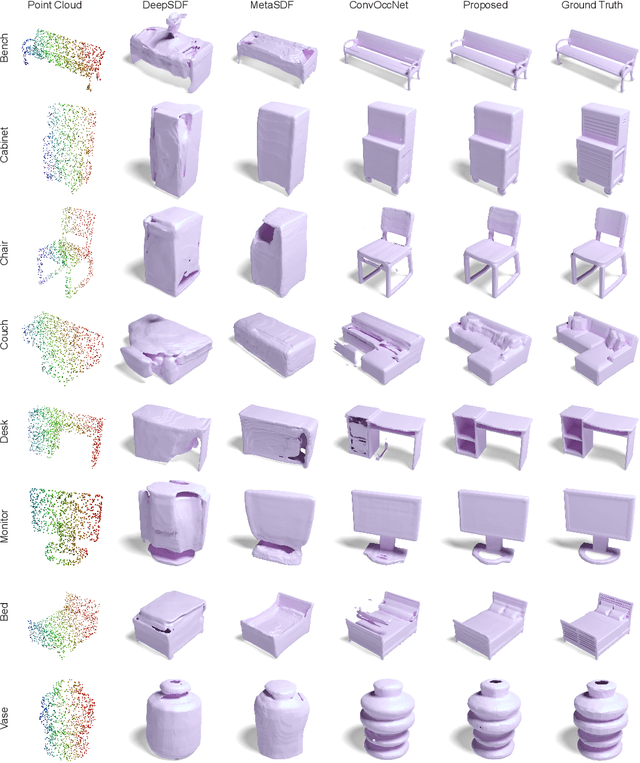
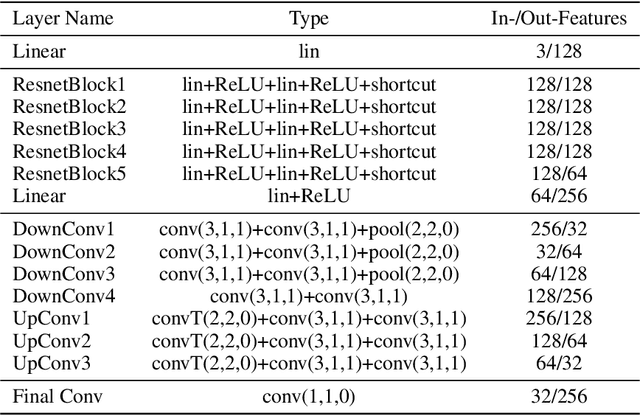

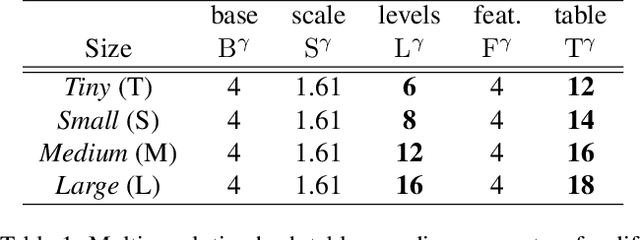
We investigate the generalization capabilities of neural signed distance functions (SDFs) for learning 3D object representations for unseen and unlabeled point clouds. Existing methods can fit SDFs to a handful of object classes and boast fine detail or fast inference speeds, but do not generalize well to unseen shapes. We introduce a two-stage semi-supervised meta-learning approach that transfers shape priors from labeled to unlabeled data to reconstruct unseen object categories. The first stage uses an episodic training scheme to simulate training on unlabeled data and meta-learns initial shape priors. The second stage then introduces unlabeled data with disjoint classes in a semi-supervised scheme to diversify these priors and achieve generalization. We assess our method on both synthetic data and real collected point clouds. Experimental results and analysis validate that our approach outperforms existing neural SDF methods and is capable of robust zero-shot inference on 100+ unseen classes. Code can be found at https://github.com/princeton-computational-imaging/gensdf.
The Implicit Values of A Good Hand Shake: Handheld Multi-Frame Neural Depth Refinement
Nov 26, 2021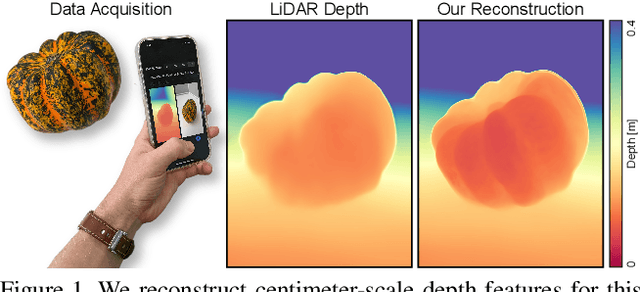
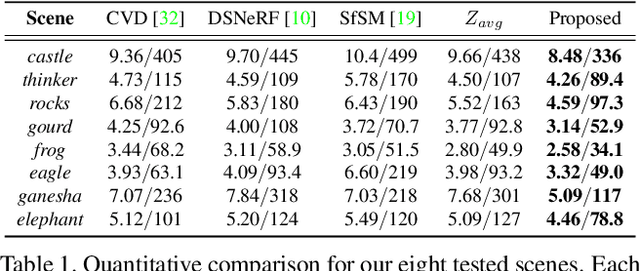

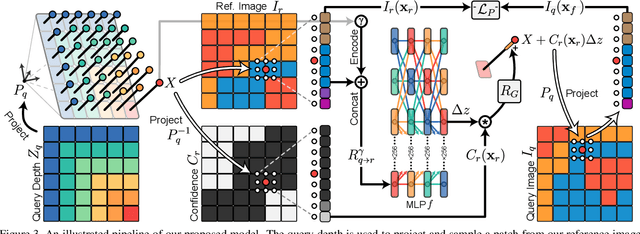
Modern smartphones can continuously stream multi-megapixel RGB images at 60~Hz, synchronized with high-quality 3D pose information and low-resolution LiDAR-driven depth estimates. During a snapshot photograph, the natural unsteadiness of the photographer's hands offers millimeter-scale variation in camera pose, which we can capture along with RGB and depth in a circular buffer. In this work we explore how, from a bundle of these measurements acquired during viewfinding, we can combine dense micro-baseline parallax cues with kilopixel LiDAR depth to distill a high-fidelity depth map. We take a test-time optimization approach and train a coordinate MLP to output photometrically and geometrically consistent depth estimates at the continuous coordinates along the path traced by the photographer's natural hand shake. The proposed method brings high-resolution depth estimates to 'point-and-shoot' tabletop photography and requires no additional hardware, artificial hand motion, or user interaction beyond the press of a button.
Centimeter-Wave Free-Space Time-of-Flight Imaging
May 25, 2021


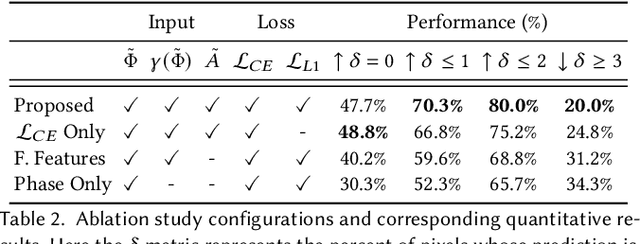
Depth cameras are emerging as a cornerstone modality with diverse applications that directly or indirectly rely on measured depth, including personal devices, robotics, and self-driving vehicles. Although time-of-flight (ToF) methods have fueled these applications, the precision and robustness of ToF methods is limited by relying on photon time-tagging or modulation after photo-conversion. Successful optical modulation approaches have been restricted fiber-coupled modulation with large coupling losses or interferometric modulation with sub-cm range, and the precision gap between interferometric methods and ToF methods is more than three orders of magnitudes. In this work, we close this gap and propose a computational imaging method for all-optical free-space correlation before photo-conversion that achieves micron-scale depth resolution with robustness to surface reflectance and ambient light with conventional silicon intensity sensors. To this end, we solve two technical challenges: modulating at GHz rates and computational phase unwrapping. We propose an imaging approach with resonant polarization modulators and devise a novel optical dual-pass frequency-doubling which achieves high modulation contrast at more than 10GHz. At the same time, centimeter-wave modulation together with a small modulation bandwidth render existing phase unwrapping methods ineffective. We tackle this problem with a neural phase unwrapping method that exploits that adjacent wraps are often highly correlated. We validate the proposed method in simulation and experimentally, where it achieves micron-scale depth precision. We demonstrate precise depth sensing independently of surface texture and ambient light and compare against existing analog demodulation methods, which we outperform across all tested scenarios.
Mask-ToF: Learning Microlens Masks for Flying Pixel Correction in Time-of-Flight Imaging
Mar 30, 2021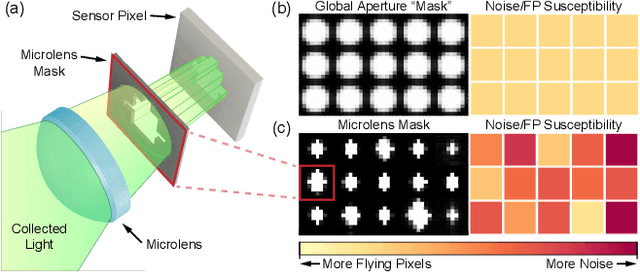



We introduce Mask-ToF, a method to reduce flying pixels (FP) in time-of-flight (ToF) depth captures. FPs are pervasive artifacts which occur around depth edges, where light paths from both an object and its background are integrated over the aperture. This light mixes at a sensor pixel to produce erroneous depth estimates, which can adversely affect downstream 3D vision tasks. Mask-ToF starts at the source of these FPs, learning a microlens-level occlusion mask which effectively creates a custom-shaped sub-aperture for each sensor pixel. This modulates the selection of foreground and background light mixtures on a per-pixel basis and thereby encodes scene geometric information directly into the ToF measurements. We develop a differentiable ToF simulator to jointly train a convolutional neural network to decode this information and produce high-fidelity, low-FP depth reconstructions. We test the effectiveness of Mask-ToF on a simulated light field dataset and validate the method with an experimental prototype. To this end, we manufacture the learned amplitude mask and design an optical relay system to virtually place it on a high-resolution ToF sensor. We find that Mask-ToF generalizes well to real data without retraining, cutting FP counts in half.
Duodepth: Static Gesture Recognition Via Dual Depth Sensors
Jun 25, 2020



Static gesture recognition is an effective non-verbal communication channel between a user and their devices; however many modern methods are sensitive to the relative pose of the user's hands with respect to the capture device, as parts of the gesture can become occluded. We present two methodologies for gesture recognition via synchronized recording from two depth cameras to alleviate this occlusion problem. One is a more classic approach using iterative closest point registration to accurately fuse point clouds and a single PointNet architecture for classification, and the other is a dual Point-Net architecture for classification without registration. On a manually collected data-set of 20,100 point clouds we show a 39.2% reduction in misclassification for the fused point cloud method, and 53.4% for the dual PointNet, when compared to a standard single camera pipeline.
* 26th International Conference on Image Processing