 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEGIS: Exploring the Limit of World Knowledge Capabilities for Unified Mulitmodal Models
Jan 02, 2026The capability of Unified Multimodal Models (UMMs) to apply world knowledge across diverse tasks remains a critical, unresolved challenge. Existing benchmarks fall short, offering only siloed, single-task evaluations with limited diagnostic power. To bridge this gap, we propose AEGIS (\emph{i.e.}, \textbf{A}ssessing \textbf{E}diting, \textbf{G}eneration, \textbf{I}nterpretation-Understanding for \textbf{S}uper-intelligence), a comprehensive multi-task benchmark covering visual understanding, generation, editing, and interleaved generation. AEGIS comprises 1,050 challenging, manually-annotated questions spanning 21 topics (including STEM, humanities, daily life, etc.) and 6 reasoning types. To concretely evaluate the performance of UMMs in world knowledge scope without ambiguous metrics, we further propose Deterministic Checklist-based Evaluation (DCE), a protocol that replaces ambiguous prompt-based scoring with atomic ``Y/N'' judgments, to enhance evaluation reliability. Our extensive experiments reveal that most UMMs exhibit severe world knowledge deficits and that performance degrades significantly with complex reasoning. Additionally, simple plug-in reasoning modules can partially mitigate these vulnerabilities, highlighting a promising direction for future research. These results highlight the importance of world-knowledge-based reasoning as a critical frontier for UMMs.
TSceneJAL: Joint Active Learning of Traffic Scenes for 3D Object Detection
Dec 25, 2024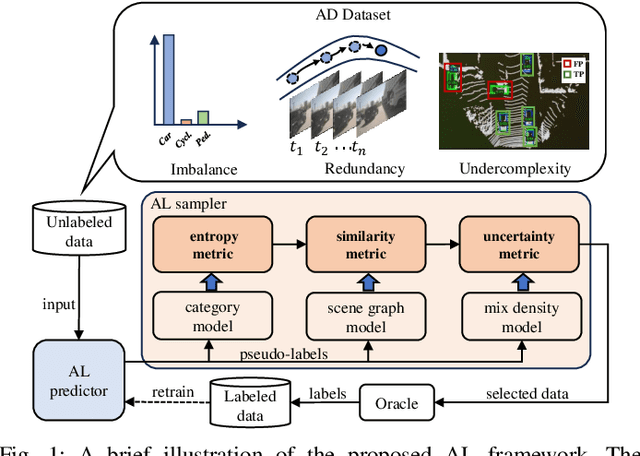
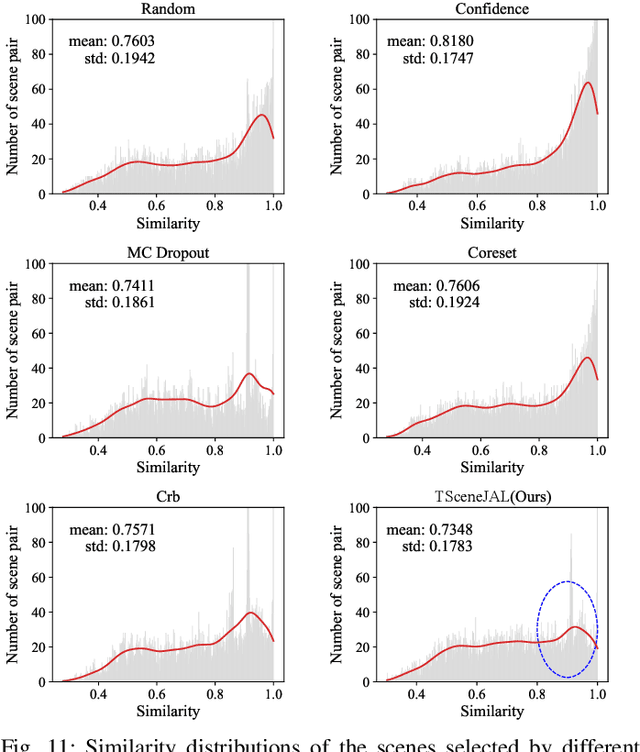
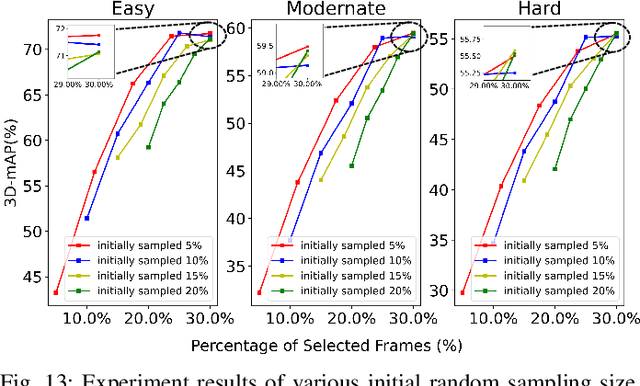
Most autonomous driving (AD) datasets incur substantial costs for collection and labeling, inevitably yielding a plethora of low-quality and redundant data instances, thereby compromising performance and efficiency. Many applications in AD systems necessitate high-quality training datasets using both existing datasets and newly collected data. In this paper, we propose a traffic scene joint active learning (TSceneJAL) framework that can efficiently sample the balanced, diverse, and complex traffic scenes from both labeled and unlabeled data. The novelty of this framework is threefold: 1) a scene sampling scheme based on a category entropy, to identify scenes containing multiple object classes, thus mitigating class imbalance for the active learner; 2) a similarity sampling scheme, estimated through the directed graph representation and a marginalize kernel algorithm, to pick sparse and diverse scenes; 3) an uncertainty sampling scheme, predicted by a mixture density network, to select instances with the most unclear or complex regression outcomes for the learner. Finally, the integration of these three schemes in a joint selection strategy yields an optimal and valuable subdataset. Experiments on the KITTI, Lyft, nuScenes and SUScape datasets demonstrate that our approach outperforms existing state-of-the-art methods on 3D object detection tasks with up to 12% improvements.
SimCMF: A Simple Cross-modal Fine-tuning Strategy from Vision Foundation Models to Any Imaging Modality
Nov 27, 2024



Foundation models like ChatGPT and Sora that are trained on a huge scale of data have made a revolutionary social impact. However, it is extremely challenging for sensors in many different fields to collect similar scales of natural images to train strong foundation models. To this end, this work presents a simple and effective framework, SimCMF, to study an important problem: cross-modal fine-tuning from vision foundation models trained on natural RGB images to other imaging modalities of different physical properties (e.g., polarization). In SimCMF, we conduct a thorough analysis of different basic components from the most naive design and ultimately propose a novel cross-modal alignment module to address the modality misalignment problem. We apply SimCMF to a representative vision foundation model Segment Anything Model (SAM) to support any evaluated new imaging modality. Given the absence of relevant benchmarks, we construct a benchmark for performance evaluation. Our experiments confirm the intriguing potential of transferring vision foundation models in enhancing other sensors' performance. SimCMF can improve the segmentation performance (mIoU) from 22.15% to 53.88% on average for evaluated modalities and consistently outperforms other baselines. The code is available at https://github.com/mt-cly/SimCMF
Adaptive Domain Learning for Cross-domain Image Denoising
Nov 03, 2024



Different camera sensors have different noise patterns, and thus an image denoising model trained on one sensor often does not generalize well to a different sensor. One plausible solution is to collect a large dataset for each sensor for training or fine-tuning, which is inevitably time-consuming. To address this cross-domain challenge, we present a novel adaptive domain learning (ADL) scheme for cross-domain RAW image denoising by utilizing existing data from different sensors (source domain) plus a small amount of data from the new sensor (target domain). The ADL training scheme automatically removes the data in the source domain that are harmful to fine-tuning a model for the target domain (some data are harmful as adding them during training lowers the performance due to domain gaps). Also, we introduce a modulation module to adopt sensor-specific information (sensor type and ISO) to understand input data for image denoising. We conduct extensive experiments on public datasets with various smartphone and DSLR cameras, which show our proposed model outperforms prior work on cross-domain image denoising, given a small amount of image data from the target domain sensor.
SimMAT: Exploring Transferability from Vision Foundation Models to Any Image Modality
Sep 12, 2024



Foundation models like ChatGPT and Sora that are trained on a huge scale of data have made a revolutionary social impact. However, it is extremely challenging for sensors in many different fields to collect similar scales of natural images to train strong foundation models. To this end, this work presents a simple and effective framework SimMAT to study an open problem: the transferability from vision foundation models trained on natural RGB images to other image modalities of different physical properties (e.g., polarization). SimMAT consists of a modality-agnostic transfer layer (MAT) and a pretrained foundation model. We apply SimMAT to a representative vision foundation model Segment Anything Model (SAM) to support any evaluated new image modality. Given the absence of relevant benchmarks, we construct a new benchmark to evaluate the transfer learning performance. Our experiments confirm the intriguing potential of transferring vision foundation models in enhancing other sensors' performance. Specifically, SimMAT can improve the segmentation performance (mIoU) from 22.15% to 53.88% on average for evaluated modalities and consistently outperforms other baselines. We hope that SimMAT can raise awareness of cross-modal transfer learning and benefit various fields for better results with vision foundation models.
CTS: Sim-to-Real Unsupervised Domain Adaptation on 3D Detection
Jun 26, 2024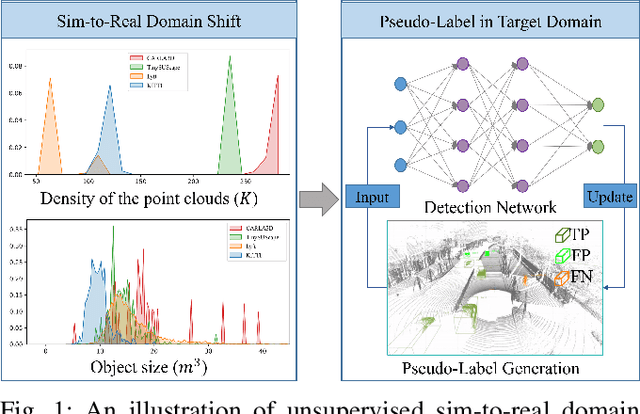
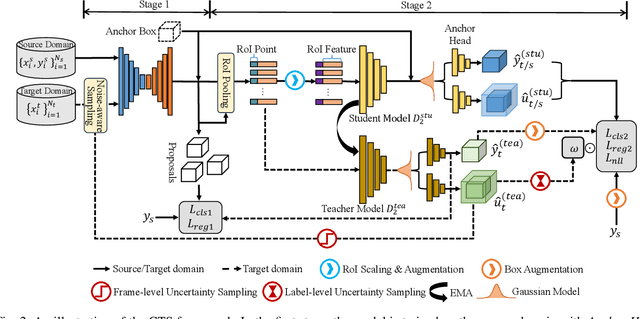
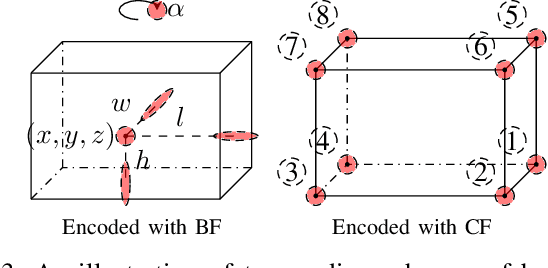
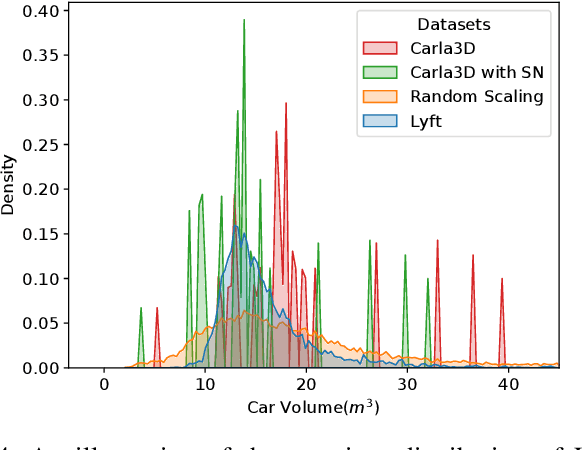
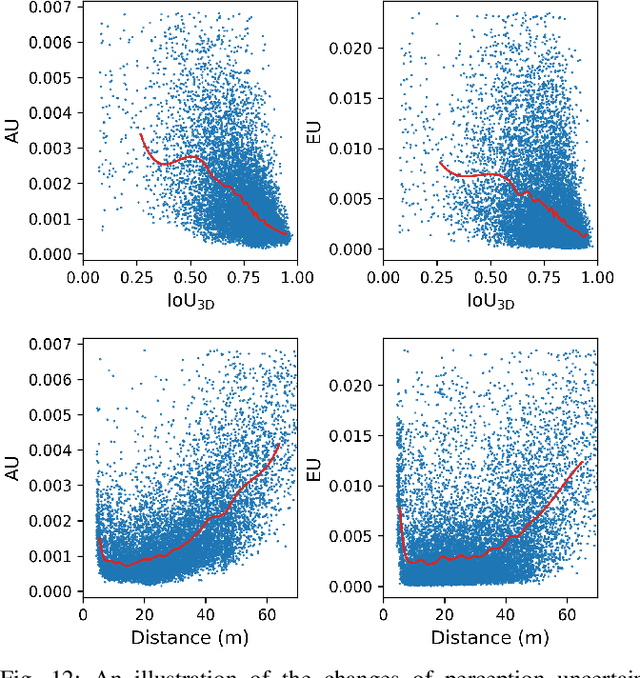
Simulation data can be accurately labeled and have been expected to improve the performance of data-driven algorithms, including object detection. However, due to the various domain inconsistencies from simulation to reality (sim-to-real), cross-domain object detection algorithms usually suffer from dramatic performance drops. While numerous unsupervised domain adaptation (UDA) methods have been developed to address cross-domain tasks between real-world datasets, progress in sim-to-real remains limited. This paper presents a novel Complex-to-Simple (CTS) framework to transfer models from labeled simulation (source) to unlabeled reality (target) domains. Based on a two-stage detector, the novelty of this work is threefold: 1) developing fixed-size anchor heads and RoI augmentation to address size bias and feature diversity between two domains, thereby improving the quality of pseudo-label; 2) developing a novel corner-format representation of aleatoric uncertainty (AU) for the bounding box, to uniformly quantify pseudo-label quality; 3) developing a noise-aware mean teacher domain adaptation method based on AU, as well as object-level and frame-level sampling strategies, to migrate the impact of noisy labels. Experimental results demonstrate that our proposed approach significantly enhances the sim-to-real domain adaptation capability of 3D object detection models, outperforming state-of-the-art cross-domain algorithms, which are usually developed for real-to-real UDA tasks.
Polarization Wavefront Lidar: Learning Large Scene Reconstruction from Polarized Wavefronts
Jun 05, 2024



Lidar has become a cornerstone sensing modality for 3D vision, especially for large outdoor scenarios and autonomous driving. Conventional lidar sensors are capable of providing centimeter-accurate distance information by emitting laser pulses into a scene and measuring the time-of-flight (ToF) of the reflection. However, the polarization of the received light that depends on the surface orientation and material properties is usually not considered. As such, the polarization modality has the potential to improve scene reconstruction beyond distance measurements. In this work, we introduce a novel long-range polarization wavefront lidar sensor (PolLidar) that modulates the polarization of the emitted and received light. Departing from conventional lidar sensors, PolLidar allows access to the raw time-resolved polarimetric wavefronts. We leverage polarimetric wavefronts to estimate normals, distance, and material properties in outdoor scenarios with a novel learned reconstruction method. To train and evaluate the method, we introduce a simulated and real-world long-range dataset with paired raw lidar data, ground truth distance, and normal maps. We find that the proposed method improves normal and distance reconstruction by 53\% mean angular error and 41\% mean absolute error compared to existing shape-from-polarization (SfP) and ToF methods. Code and data are open-sourced at https://light.princeton.edu/pollidar.
Towards Flexible Interactive Reflection Removal with Human Guidance
Jun 03, 2024Single image reflection removal is inherently ambiguous, as both the reflection and transmission components requiring separation may follow natural image statistics. Existing methods attempt to address the issue by using various types of low-level and physics-based cues as sources of reflection signals. However, these cues are not universally applicable, since they are only observable in specific capture scenarios. This leads to a significant performance drop when test images do not align with their assumptions. In this paper, we aim to explore a novel flexible interactive reflection removal approach that leverages various forms of sparse human guidance, such as points and bounding boxes, as auxiliary high-level prior to achieve robust reflection removal. However, incorporating the raw user guidance naively into the existing reflection removal network does not result in performance gains. To this end, we innovatively transform raw user input into a unified form -- reflection masks using an Interactive Segmentation Foundation Model. Such a design absorbs the quintessence of the foundational segmentation model and flexible human guidance, thereby mitigating the challenges of reflection separations. Furthermore, to fully utilize user guidance and reduce user annotation costs, we design a mask-guided reflection removal network, comprising our proposed self-adaptive prompt block. This block adaptively incorporates user guidance as anchors and refines transmission features via cross-attention mechanisms. Extensive results on real-world images validate that our method demonstrates state-of-the-art performance on various datasets with the help of flexible and sparse user guidance. Our code and dataset will be publicly available here https://github.com/ShawnChenn/FlexibleReflectionRemoval.
DC-Gaussian: Improving 3D Gaussian Splatting for Reflective Dash Cam Videos
May 29, 2024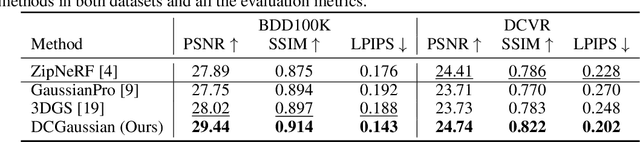

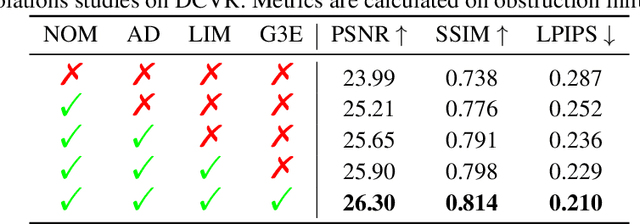
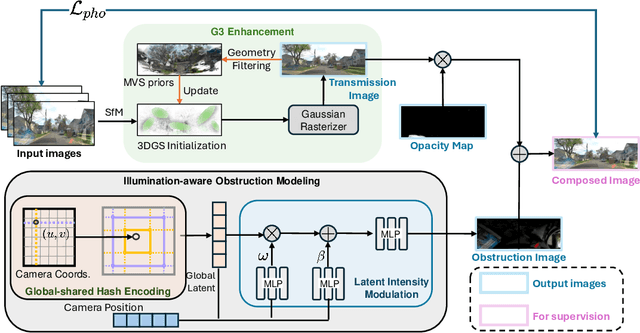
We present DC-Gaussian, a new method for generating novel views from in-vehicle dash cam videos. While neural rendering techniques have made significant strides in driving scenarios, existing methods are primarily designed for videos collected by autonomous vehicles. However, these videos are limited in both quantity and diversity compared to dash cam videos, which are more widely used across various types of vehicles and capture a broader range of scenarios. Dash cam videos often suffer from severe obstructions such as reflections and occlusions on the windshields, which significantly impede the application of neural rendering techniques. To address this challenge, we develop DC-Gaussian based on the recent real-time neural rendering technique 3D Gaussian Splatting (3DGS). Our approach includes an adaptive image decomposition module to model reflections and occlusions in a unified manner. Additionally, we introduce illumination-aware obstruction modeling to manage reflections and occlusions under varying lighting conditions. Lastly, we employ a geometry-guided Gaussian enhancement strategy to improve rendering details by incorporating additional geometry priors. Experiments on self-captured and public dash cam videos show that our method not only achieves state-of-the-art performance in novel view synthesis, but also accurately reconstructing captured scenes getting rid of obstructions.
Automatic Controllable Colorization via Imagination
Apr 08, 2024We propose a framework for automatic colorization that allows for iterative editing and modifications. The core of our framework lies in an imagination module: by understanding the content within a grayscale image, we utilize a pre-trained image generation model to generate multiple images that contain the same content. These images serve as references for coloring, mimicking the process of human experts. As the synthesized images can be imperfect or different from the original grayscale image, we propose a Reference Refinement Module to select the optimal reference composition. Unlike most previous end-to-end automatic colorization algorithms, our framework allows for iterative and localized modifications of the colorization results because we explicitly model the coloring samples. Extensive experiments demonstrate the superiority of our framework over existing automatic colorization algorithms in editability and flexibility. Project page: https://xy-cong.github.io/imagine-colorization.