 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimateGS: Real-Time Climate Simulation with 3D Gaussian Style Transfer
Mar 19, 2025Adverse climate conditions pose significant challenges for autonomous systems, demanding reliable perception and decision-making across diverse environments. To better simulate these conditions, physically-based NeRF rendering methods have been explored for their ability to generate realistic scene representations. However, these methods suffer from slow rendering speeds and long preprocessing times, making them impractical for real-time testing and user interaction. This paper presents ClimateGS, a novel framework integrating 3D Gaussian representations with physical simulation to enable real-time climate effects rendering. The novelty of this work is threefold: 1) developing a linear transformation for 3D Gaussian photorealistic style transfer, enabling direct modification of spherical harmonics across bands for efficient and consistent style adaptation; 2) developing a joint training strategy for 3D style transfer, combining supervised and self-supervised learning to accelerate convergence while preserving original scene details; 3) developing a real-time rendering method for climate simulation, integrating physics-based effects with 3D Gaussian to achieve efficient and realistic rendering. We evaluate ClimateGS on MipNeRF360 and Tanks and Temples, demonstrating real-time rendering with comparable or superior visual quality to SOTA 2D/3D methods, making it suitable for interactive applications.
SemanticFlow: A Self-Supervised Framework for Joint Scene Flow Prediction and Instance Segmentation in Dynamic Environments
Mar 19, 2025Accurate perception of dynamic traffic scenes is crucial for high-level autonomous driving systems, requiring robust object motion estimation and instance segmentation. However, traditional methods often treat them as separate tasks, leading to suboptimal performance, spatio-temporal inconsistencies, and inefficiency in complex scenarios due to the absence of information sharing. This paper proposes a multi-task SemanticFlow framework to simultaneously predict scene flow and instance segmentation of full-resolution point clouds. The novelty of this work is threefold: 1) developing a coarse-to-fine prediction based multi-task scheme, where an initial coarse segmentation of static backgrounds and dynamic objects is used to provide contextual information for refining motion and semantic information through a shared feature processing module; 2) developing a set of loss functions to enhance the performance of scene flow estimation and instance segmentation, while can help ensure spatial and temporal consistency of both static and dynamic objects within traffic scenes; 3) developing a self-supervised learning scheme, which utilizes coarse segmentation to detect rigid objects and compute their transformation matrices between sequential frames, enabling the generation of self-supervised labels. The proposed framework is validated on the Argoverse and Waymo datasets, demonstrating superior performance in instance segmentation accuracy, scene flow estimation, and computational efficiency, establishing a new benchmark for self-supervised methods in dynamic scene understanding.
SSF-PAN: Semantic Scene Flow-Based Perception for Autonomous Navigation in Traffic Scenarios
Jan 28, 2025Vehicle detection and localization in complex traffic scenarios pose significant challenges due to the interference of moving objects. Traditional methods often rely on outlier exclusions or semantic segmentations, which suffer from low computational efficiency and accuracy. The proposed SSF-PAN can achieve the functionalities of LiDAR point cloud based object detection/localization and SLAM (Simultaneous Localization and Mapping) with high computational efficiency and accuracy, enabling map-free navigation frameworks. The novelty of this work is threefold: 1) developing a neural network which can achieve segmentation among static and dynamic objects within the scene flows with different motion features, that is, semantic scene flow (SSF); 2) developing an iterative framework which can further optimize the quality of input scene flows and output segmentation results; 3) developing a scene flow-based navigation platform which can test the performance of the SSF perception system in the simulation environment. The proposed SSF-PAN method is validated using the SUScape-CARLA and the KITTI datasets, as well as on the CARLA simulator. Experimental results demonstrate that the proposed approach outperforms traditional methods in terms of scene flow computation accuracy, moving object detection accuracy, computational efficiency, and autonomous navigation effectiveness.
TSceneJAL: Joint Active Learning of Traffic Scenes for 3D Object Detection
Dec 25, 2024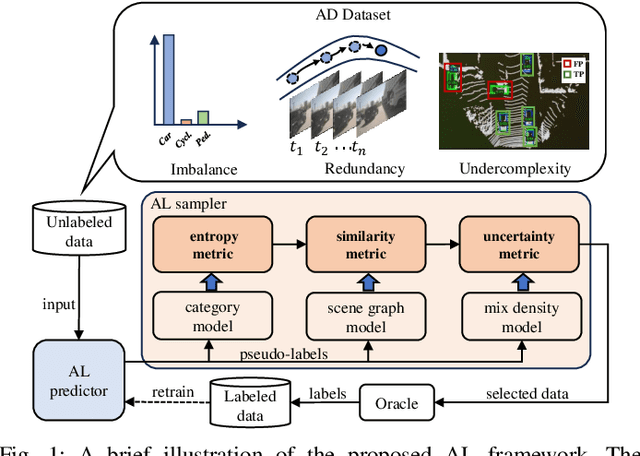
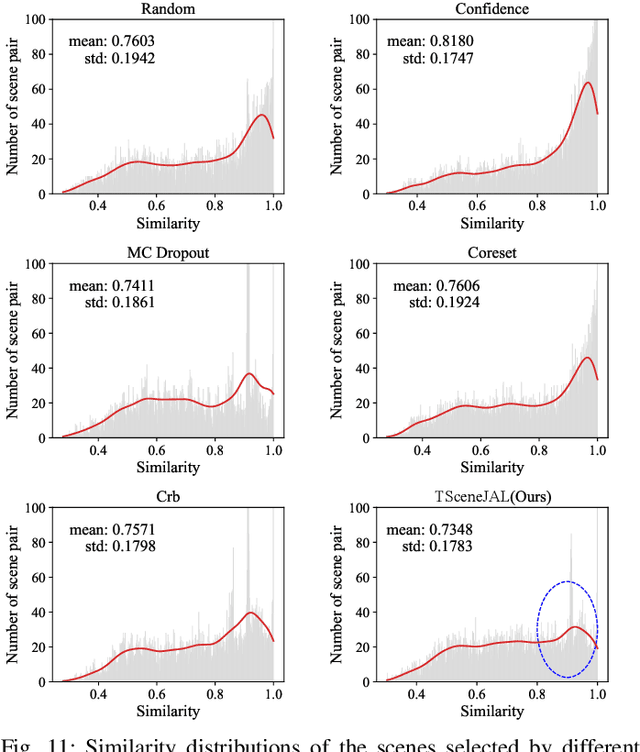
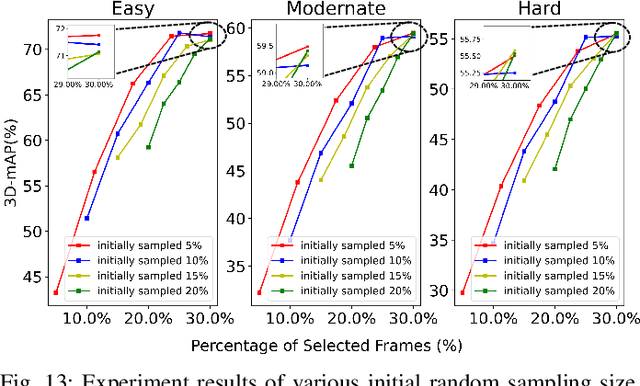
Most autonomous driving (AD) datasets incur substantial costs for collection and labeling, inevitably yielding a plethora of low-quality and redundant data instances, thereby compromising performance and efficiency. Many applications in AD systems necessitate high-quality training datasets using both existing datasets and newly collected data. In this paper, we propose a traffic scene joint active learning (TSceneJAL) framework that can efficiently sample the balanced, diverse, and complex traffic scenes from both labeled and unlabeled data. The novelty of this framework is threefold: 1) a scene sampling scheme based on a category entropy, to identify scenes containing multiple object classes, thus mitigating class imbalance for the active learner; 2) a similarity sampling scheme, estimated through the directed graph representation and a marginalize kernel algorithm, to pick sparse and diverse scenes; 3) an uncertainty sampling scheme, predicted by a mixture density network, to select instances with the most unclear or complex regression outcomes for the learner. Finally, the integration of these three schemes in a joint selection strategy yields an optimal and valuable subdataset. Experiments on the KITTI, Lyft, nuScenes and SUScape datasets demonstrate that our approach outperforms existing state-of-the-art methods on 3D object detection tasks with up to 12% improvements.
CTS: Sim-to-Real Unsupervised Domain Adaptation on 3D Detection
Jun 26, 2024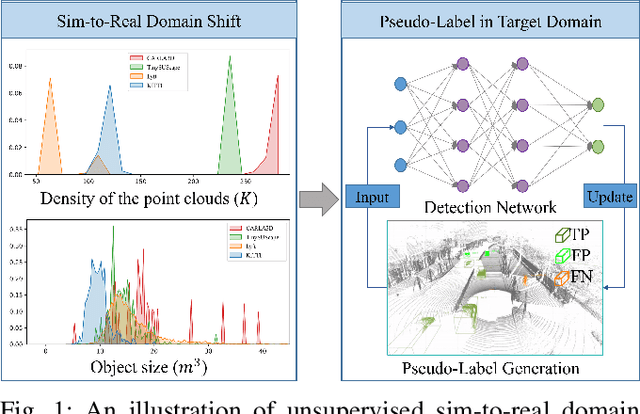
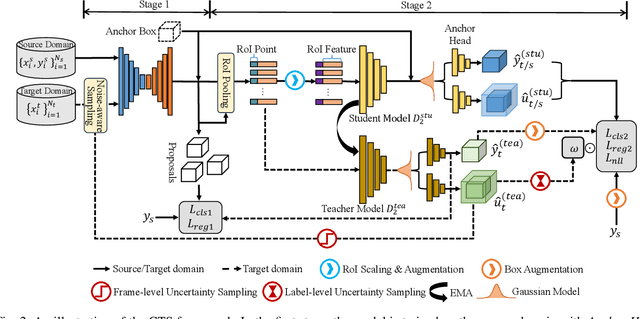
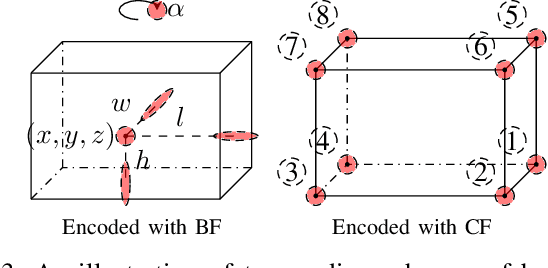
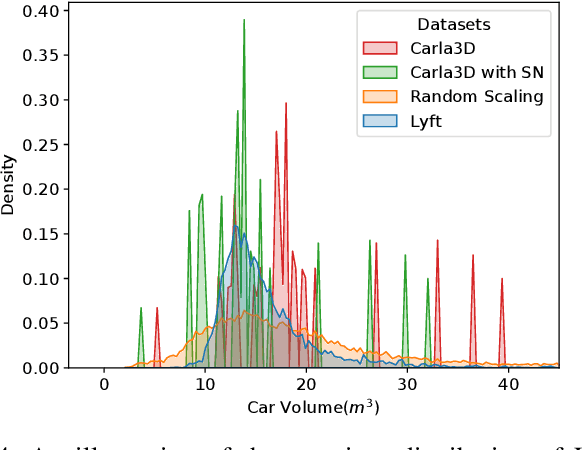
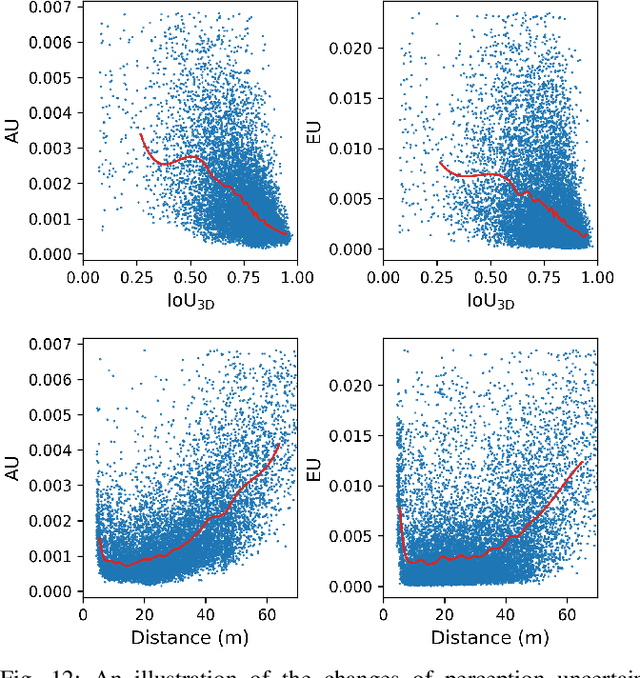
Simulation data can be accurately labeled and have been expected to improve the performance of data-driven algorithms, including object detection. However, due to the various domain inconsistencies from simulation to reality (sim-to-real), cross-domain object detection algorithms usually suffer from dramatic performance drops. While numerous unsupervised domain adaptation (UDA) methods have been developed to address cross-domain tasks between real-world datasets, progress in sim-to-real remains limited. This paper presents a novel Complex-to-Simple (CTS) framework to transfer models from labeled simulation (source) to unlabeled reality (target) domains. Based on a two-stage detector, the novelty of this work is threefold: 1) developing fixed-size anchor heads and RoI augmentation to address size bias and feature diversity between two domains, thereby improving the quality of pseudo-label; 2) developing a novel corner-format representation of aleatoric uncertainty (AU) for the bounding box, to uniformly quantify pseudo-label quality; 3) developing a noise-aware mean teacher domain adaptation method based on AU, as well as object-level and frame-level sampling strategies, to migrate the impact of noisy labels. Experimental results demonstrate that our proposed approach significantly enhances the sim-to-real domain adaptation capability of 3D object detection models, outperforming state-of-the-art cross-domain algorithms, which are usually developed for real-to-real UDA tasks.
BiTrack: Bidirectional Offline 3D Multi-Object Tracking Using Camera-LiDAR Data
Jun 26, 2024



Compared with real-time multi-object tracking (MOT), offline multi-object tracking (OMOT) has the advantages to perform 2D-3D detection fusion, erroneous link correction, and full track optimization but has to deal with the challenges from bounding box misalignment and track evaluation, editing, and refinement. This paper proposes "BiTrack", a 3D OMOT framework that includes modules of 2D-3D detection fusion, initial trajectory generation, and bidirectional trajectory re-optimization to achieve optimal tracking results from camera-LiDAR data. The novelty of this paper includes threefold: (1) development of a point-level object registration technique that employs a density-based similarity metric to achieve accurate fusion of 2D-3D detection results; (2) development of a set of data association and track management skills that utilizes a vertex-based similarity metric as well as false alarm rejection and track recovery mechanisms to generate reliable bidirectional object trajectories; (3) development of a trajectory re-optimization scheme that re-organizes track fragments of different fidelities in a greedy fashion, as well as refines each trajectory with completion and smoothing techniques. The experiment results on the KITTI dataset demonstrate that BiTrack achieves the state-of-the-art performance for 3D OMOT tasks in terms of accuracy and efficiency.
Towards Fair, Robust and Efficient Client Contribution Evaluation in Federated Learning
Feb 06, 2024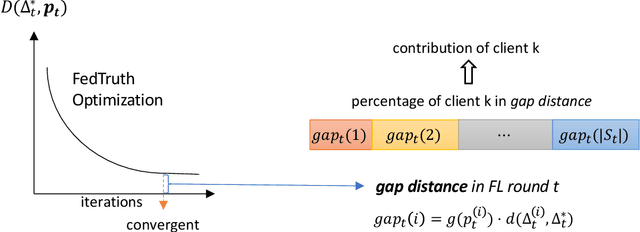
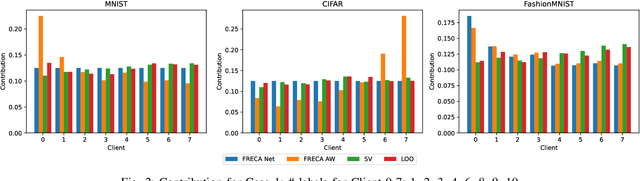
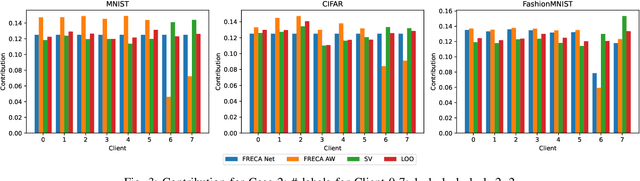
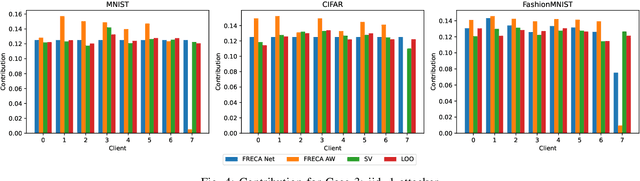
The performance of clients in Federated Learning (FL) can vary due to various reasons. Assessing the contributions of each client is crucial for client selection and compensation. It is challenging because clients often have non-independent and identically distributed (non-iid) data, leading to potentially noisy or divergent updates. The risk of malicious clients amplifies the challenge especially when there's no access to clients' local data or a benchmark root dataset. In this paper, we introduce a novel method called Fair, Robust, and Efficient Client Assessment (FRECA) for quantifying client contributions in FL. FRECA employs a framework called FedTruth to estimate the global model's ground truth update, balancing contributions from all clients while filtering out impacts from malicious ones. This approach is robust against Byzantine attacks and incorporates a Byzantine-resilient aggregation algorithm. FRECA is also efficient, as it operates solely on local model updates and requires no validation operations or datasets. Our experimental results show that FRECA can accurately and efficiently quantify client contributions in a robust manner.
Multi-Criteria Client Selection and Scheduling with Fairness Guarantee for Federated Learning Service
Dec 05, 2023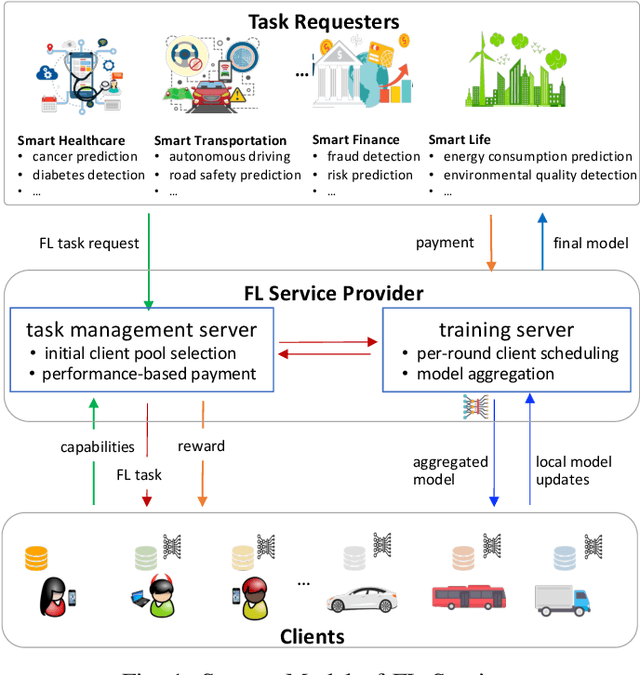
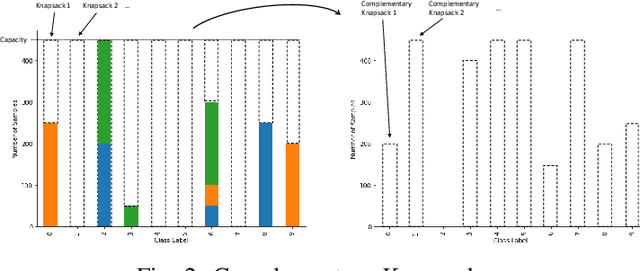
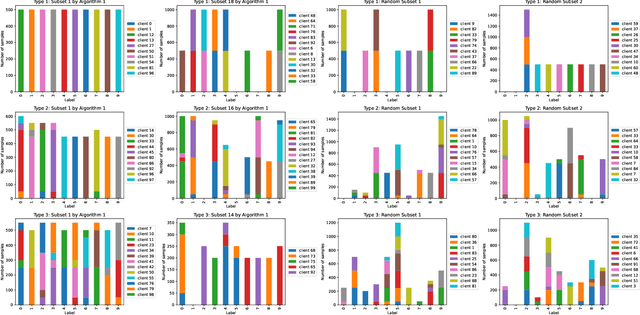
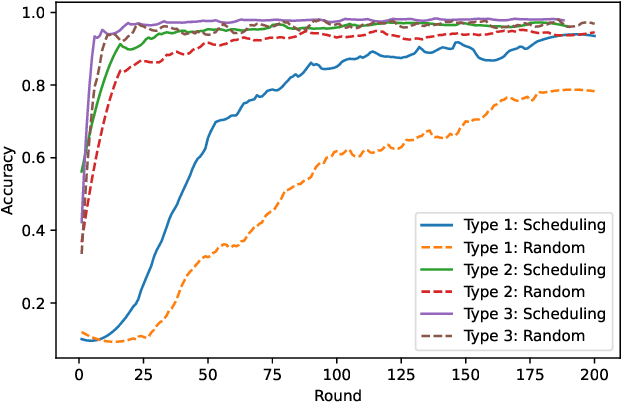
Federated Learning (FL) enables multiple clients to train machine learning models collaboratively without sharing the raw training data. However, for a given FL task, how to select a group of appropriate clients fairly becomes a challenging problem due to budget restrictions and client heterogeneity. In this paper, we propose a multi-criteria client selection and scheduling scheme with a fairness guarantee, comprising two stages: 1) preliminary client pool selection, and 2) per-round client scheduling. Specifically, we first define a client selection metric informed by several criteria, such as client resources, data quality, and client behaviors. Then, we formulate the initial client pool selection problem into an optimization problem that aims to maximize the overall scores of selected clients within a given budget and propose a greedy algorithm to solve it. To guarantee fairness, we further formulate the per-round client scheduling problem and propose a heuristic algorithm to divide the client pool into several subsets such that every client is selected at least once while guaranteeing that the `integrated' dataset in a subset is close to an independent and identical distribution (iid). Our experimental results show that our scheme can improve the model quality especially when data are non-iid.
Prototypical Model with Novel Information-theoretic Loss Function for Generalized Zero Shot Learning
Dec 06, 2021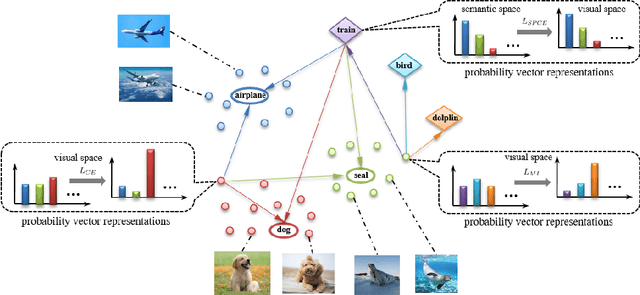
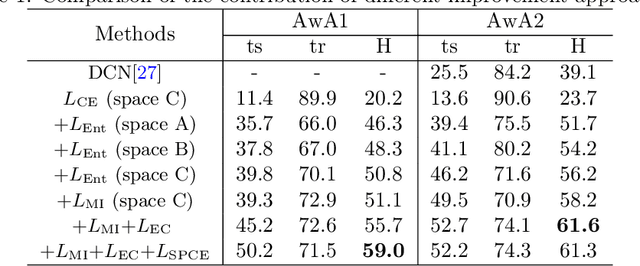
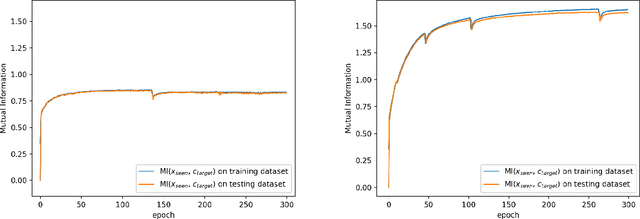
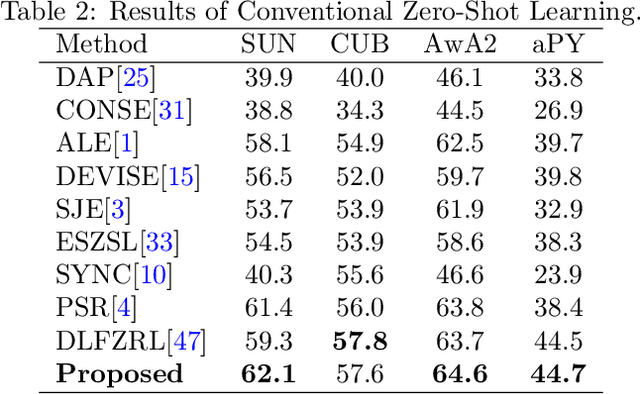
Generalized zero shot learning (GZSL) is still a technical challenge of deep learning as it has to recognize both source and target classes without data from target classes. To preserve the semantic relation between source and target classes when only trained with data from source classes, we address the quantification of the knowledge transfer and semantic relation from an information-theoretic viewpoint. To this end, we follow the prototypical model and format the variables of concern as a probability vector. Leveraging on the proposed probability vector representation, the information measurement such as mutual information and entropy, can be effectively evaluated with simple closed forms. We discuss the choice of common embedding space and distance function when using the prototypical model. Then We propose three information-theoretic loss functions for deterministic GZSL model: a mutual information loss to bridge seen data and target classes; an uncertainty-aware entropy constraint loss to prevent overfitting when using seen data to learn the embedding of target classes; a semantic preserving cross entropy loss to preserve the semantic relation when mapping the semantic representations to the common space. Simulation shows that, as a deterministic model, our proposed method obtains state of the art results on GZSL benchmark datasets. We achieve 21%-64% improvements over the baseline model -- deep calibration network (DCN) and for the first time demonstrate a deterministic model can perform as well as generative ones. Moreover, our proposed model is compatible with generative models. Simulation studies show that by incorporating with f-CLSWGAN, we obtain comparable results compared with advanced generative models.