 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fair, Robust and Efficient Client Contribution Evaluation in Federated Learning
Feb 06, 2024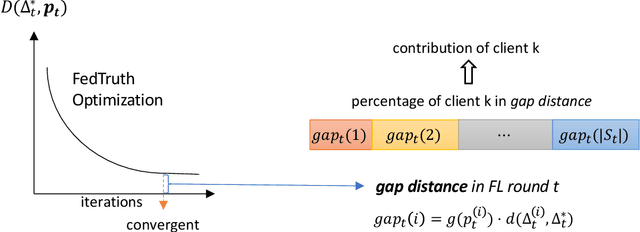
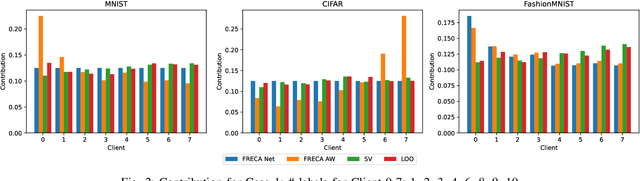
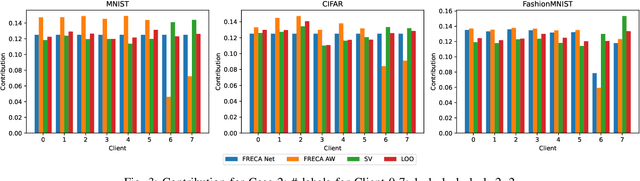
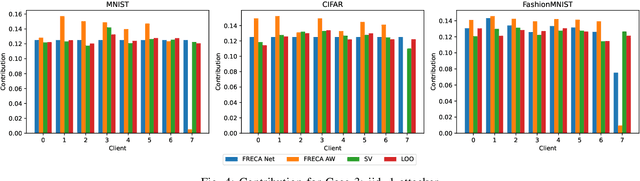
The performance of clients in Federated Learning (FL) can vary due to various reasons. Assessing the contributions of each client is crucial for client selection and compensation. It is challenging because clients often have non-independent and identically distributed (non-iid) data, leading to potentially noisy or divergent updates. The risk of malicious clients amplifies the challenge especially when there's no access to clients' local data or a benchmark root dataset. In this paper, we introduce a novel method called Fair, Robust, and Efficient Client Assessment (FRECA) for quantifying client contributions in FL. FRECA employs a framework called FedTruth to estimate the global model's ground truth update, balancing contributions from all clients while filtering out impacts from malicious ones. This approach is robust against Byzantine attacks and incorporates a Byzantine-resilient aggregation algorithm. FRECA is also efficient, as it operates solely on local model updates and requires no validation operations or datasets. Our experimental results show that FRECA can accurately and efficiently quantify client contributions in a robust manner.
Multi-Criteria Client Selection and Scheduling with Fairness Guarantee for Federated Learning Service
Dec 05, 2023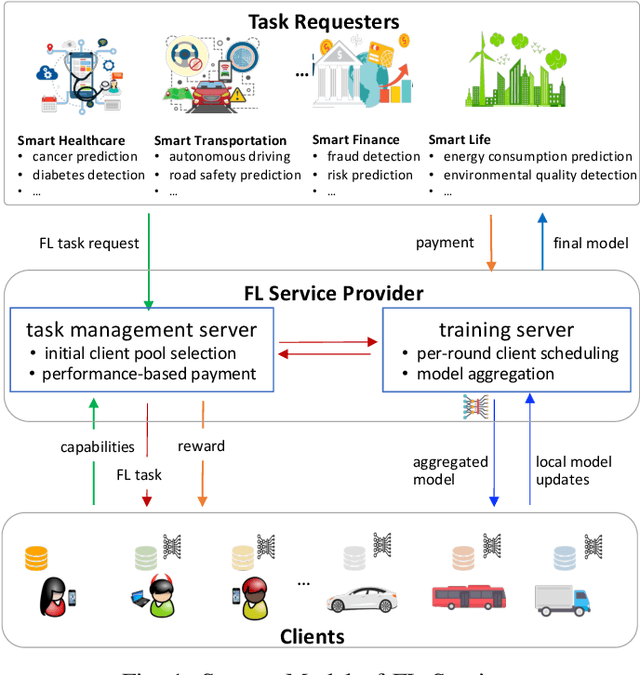
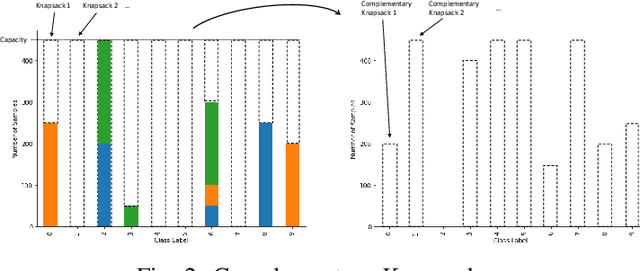
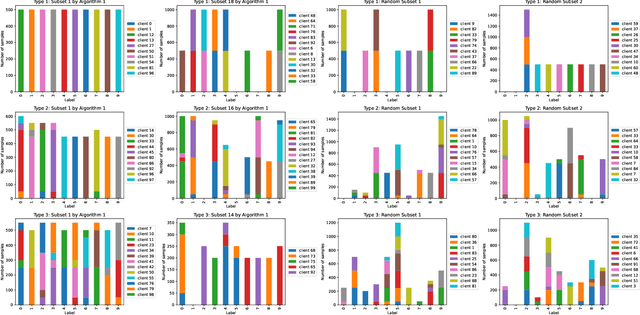
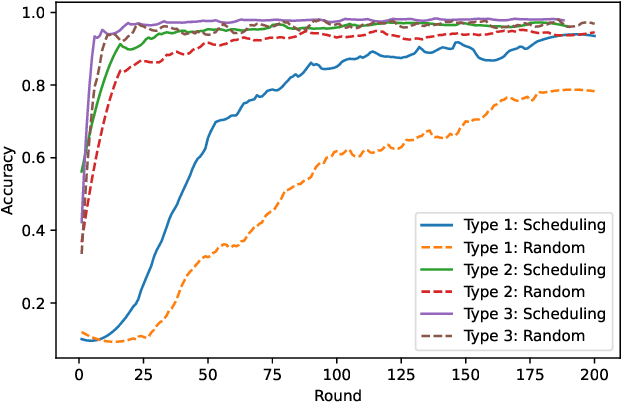
Federated Learning (FL) enables multiple clients to train machine learning models collaboratively without sharing the raw training data. However, for a given FL task, how to select a group of appropriate clients fairly becomes a challenging problem due to budget restrictions and client heterogeneity. In this paper, we propose a multi-criteria client selection and scheduling scheme with a fairness guarantee, comprising two stages: 1) preliminary client pool selection, and 2) per-round client scheduling. Specifically, we first define a client selection metric informed by several criteria, such as client resources, data quality, and client behaviors. Then, we formulate the initial client pool selection problem into an optimization problem that aims to maximize the overall scores of selected clients within a given budget and propose a greedy algorithm to solve it. To guarantee fairness, we further formulate the per-round client scheduling problem and propose a heuristic algorithm to divide the client pool into several subsets such that every client is selected at least once while guaranteeing that the `integrated' dataset in a subset is close to an independent and identical distribution (iid). Our experimental results show that our scheme can improve the model quality especially when data are non-iid.