 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWEDepth: Efficient Adaptation of World Knowledge for Monocular Depth Estimation
Nov 11, 2025Monocular depth estimation (MDE) has widely applicable but remains highly challenging due to the inherently ill-posed nature of reconstructing 3D scenes from single 2D images. Modern Vision Foundation Models (VFMs), pre-trained on large-scale diverse datasets, exhibit remarkable world understanding capabilities that benefit for various vision tasks. Recent studies have demonstrated significant improvements in MDE through fine-tuning these VFMs. Inspired by these developments, we propose WEDepth, a novel approach that adapts VFMs for MDE without modi-fying their structures and pretrained weights, while effec-tively eliciting and leveraging their inherent priors. Our method employs the VFM as a multi-level feature en-hancer, systematically injecting prior knowledge at differ-ent representation levels. Experiments on NYU-Depth v2 and KITTI datasets show that WEDepth establishes new state-of-the-art (SOTA) performance, achieving competi-tive results compared to both diffusion-based approaches (which require multiple forward passes) and methods pre-trained on relative depth. Furthermore, we demonstrate our method exhibits strong zero-shot transfer capability across diverse scenarios.
Towards Fair, Robust and Efficient Client Contribution Evaluation in Federated Learning
Feb 06, 2024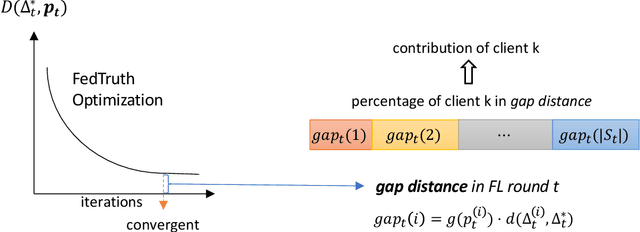
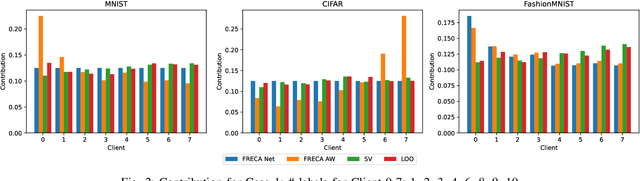
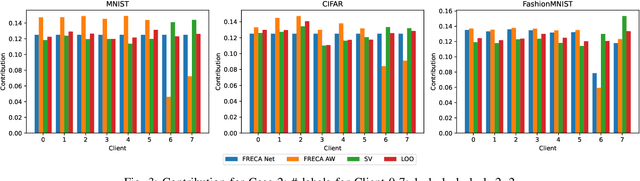
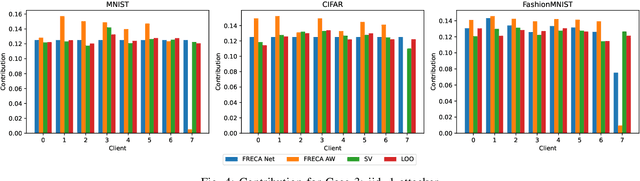
The performance of clients in Federated Learning (FL) can vary due to various reasons. Assessing the contributions of each client is crucial for client selection and compensation. It is challenging because clients often have non-independent and identically distributed (non-iid) data, leading to potentially noisy or divergent updates. The risk of malicious clients amplifies the challenge especially when there's no access to clients' local data or a benchmark root dataset. In this paper, we introduce a novel method called Fair, Robust, and Efficient Client Assessment (FRECA) for quantifying client contributions in FL. FRECA employs a framework called FedTruth to estimate the global model's ground truth update, balancing contributions from all clients while filtering out impacts from malicious ones. This approach is robust against Byzantine attacks and incorporates a Byzantine-resilient aggregation algorithm. FRECA is also efficient, as it operates solely on local model updates and requires no validation operations or datasets. Our experimental results show that FRECA can accurately and efficiently quantify client contributions in a robust manner.
Multi-Criteria Client Selection and Scheduling with Fairness Guarantee for Federated Learning Service
Dec 05, 2023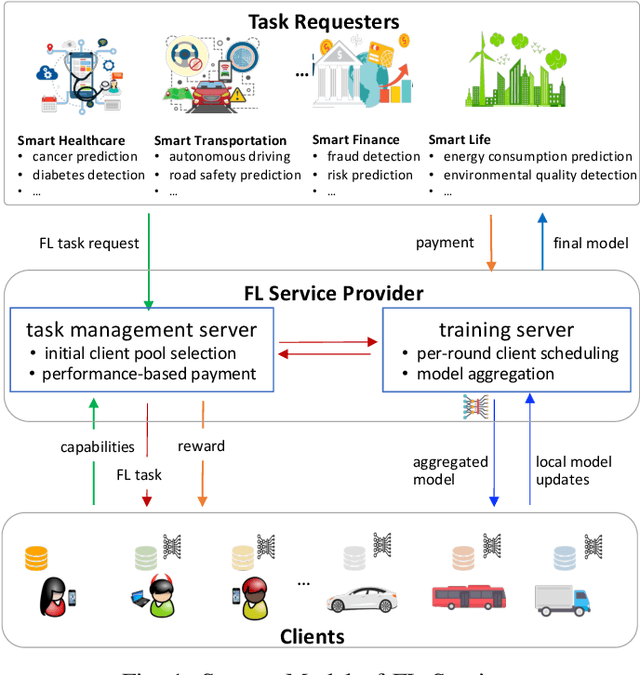
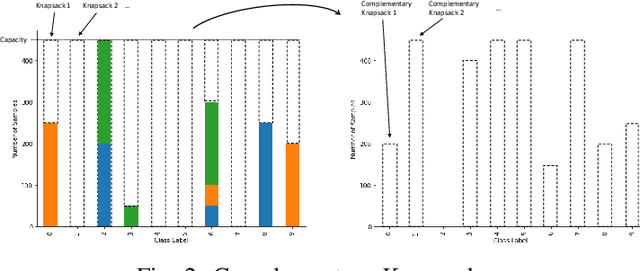
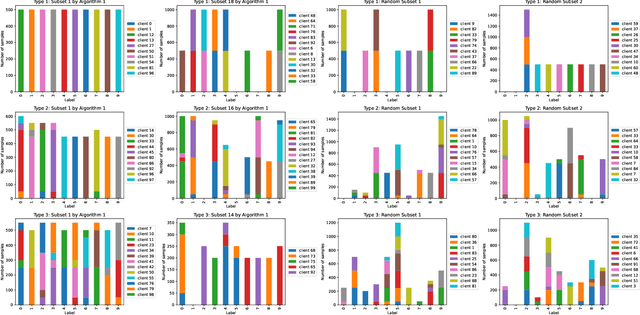
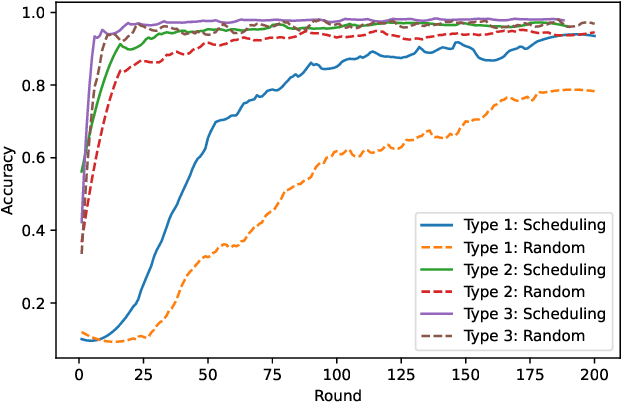
Federated Learning (FL) enables multiple clients to train machine learning models collaboratively without sharing the raw training data. However, for a given FL task, how to select a group of appropriate clients fairly becomes a challenging problem due to budget restrictions and client heterogeneity. In this paper, we propose a multi-criteria client selection and scheduling scheme with a fairness guarantee, comprising two stages: 1) preliminary client pool selection, and 2) per-round client scheduling. Specifically, we first define a client selection metric informed by several criteria, such as client resources, data quality, and client behaviors. Then, we formulate the initial client pool selection problem into an optimization problem that aims to maximize the overall scores of selected clients within a given budget and propose a greedy algorithm to solve it. To guarantee fairness, we further formulate the per-round client scheduling problem and propose a heuristic algorithm to divide the client pool into several subsets such that every client is selected at least once while guaranteeing that the `integrated' dataset in a subset is close to an independent and identical distribution (iid). Our experimental results show that our scheme can improve the model quality especially when data are non-iid.
FedTruth: Byzantine-Robust and Backdoor-Resilient Federated Learning Framework
Nov 17, 2023Federated Learning (FL) enables collaborative machine learning model training across multiple parties without sharing raw data. However, FL's distributed nature allows malicious clients to impact model training through Byzantine or backdoor attacks, using erroneous model updates. Existing defenses measure the deviation of each update from a 'ground-truth model update.' They often rely on a benign root dataset on the server or use trimmed mean or median for clipping, both methods having limitations. We introduce FedTruth, a robust defense against model poisoning in FL. FedTruth doesn't assume specific data distributions nor requires a benign root dataset. It estimates a global model update with dynamic aggregation weights, considering contributions from all benign clients. Empirical studies demonstrate FedTruth's efficacy in mitigating the impacts of poisoned updates from both Byzantine and backdoor attacks.
Intra-Ensemble in Neural Networks
Apr 09, 2019
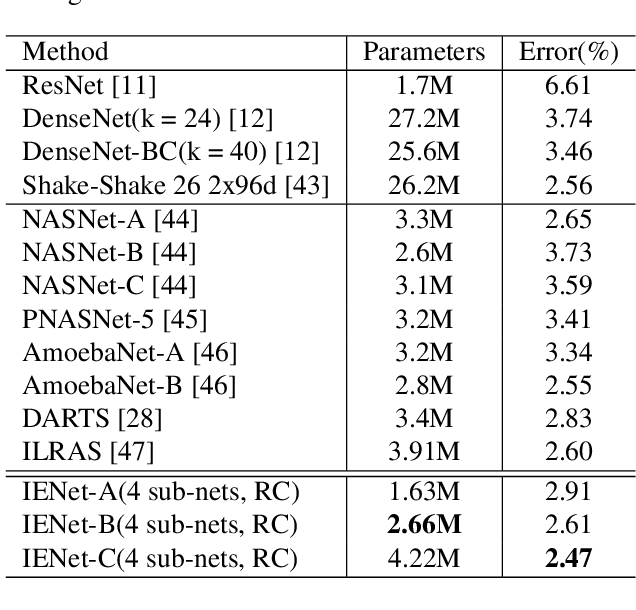
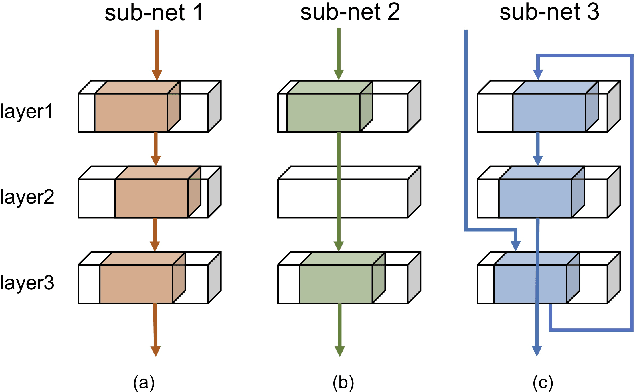
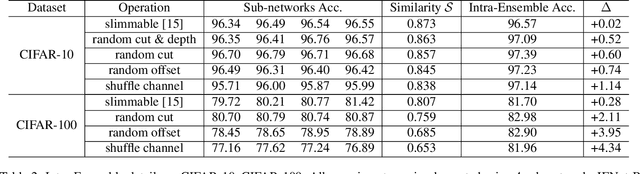
Improving model performance is always the key problem in machine learning including deep learning. However, stand-alone neural networks always suffer from marginal effect when stacking more layers. At the same time, ensemble is a useful technique to further enhance model performance. Nevertheless, training several independent stand-alone deep neural networks costs multiple resources. In this work, we propose Intra-Ensemble, an end-to-end strategy with stochastic training operations to train several sub-networks simultaneously within one neural network. Additional parameter size is marginal since the majority of parameters are mutually shared. Meanwhile, stochastic training increases the diversity of sub-networks with weight sharing, which significantly enhances intra-ensemble performance. Extensive experiments prove the applicability of intra-ensemble on various kinds of datasets and network architectures. Our models achieve comparable results with the state-of-the-art architectures on CIFAR-10 and CIFAR-100.