 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticFlow: A Self-Supervised Framework for Joint Scene Flow Prediction and Instance Segmentation in Dynamic Environments
Mar 19, 2025Accurate perception of dynamic traffic scenes is crucial for high-level autonomous driving systems, requiring robust object motion estimation and instance segmentation. However, traditional methods often treat them as separate tasks, leading to suboptimal performance, spatio-temporal inconsistencies, and inefficiency in complex scenarios due to the absence of information sharing. This paper proposes a multi-task SemanticFlow framework to simultaneously predict scene flow and instance segmentation of full-resolution point clouds. The novelty of this work is threefold: 1) developing a coarse-to-fine prediction based multi-task scheme, where an initial coarse segmentation of static backgrounds and dynamic objects is used to provide contextual information for refining motion and semantic information through a shared feature processing module; 2) developing a set of loss functions to enhance the performance of scene flow estimation and instance segmentation, while can help ensure spatial and temporal consistency of both static and dynamic objects within traffic scenes; 3) developing a self-supervised learning scheme, which utilizes coarse segmentation to detect rigid objects and compute their transformation matrices between sequential frames, enabling the generation of self-supervised labels. The proposed framework is validated on the Argoverse and Waymo datasets, demonstrating superior performance in instance segmentation accuracy, scene flow estimation, and computational efficiency, establishing a new benchmark for self-supervised methods in dynamic scene understanding.
Inter3D: A Benchmark and Strong Baseline for Human-Interactive 3D Object Reconstruction
Feb 19, 2025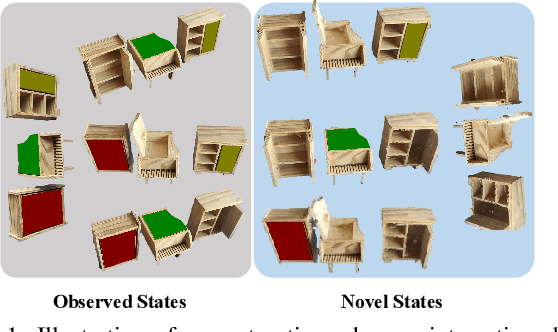

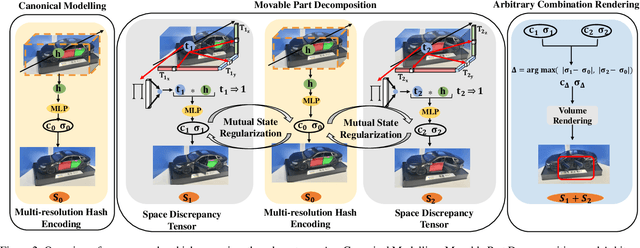

Recent advancements in implicit 3D reconstruction methods, e.g., neural rendering fields and Gaussian splatting, have primarily focused on novel view synthesis of static or dynamic objects with continuous motion states. However, these approaches struggle to efficiently model a human-interactive object with n movable parts, requiring 2^n separate models to represent all discrete states. To overcome this limitation, we propose Inter3D, a new benchmark and approach for novel state synthesis of human-interactive objects. We introduce a self-collected dataset featuring commonly encountered interactive objects and a new evaluation pipeline, where only individual part states are observed during training, while part combination states remain unseen. We also propose a strong baseline approach that leverages Space Discrepancy Tensors to efficiently modelling all states of an object. To alleviate the impractical constraints on camera trajectories across training states, we propose a Mutual State Regularization mechanism to enhance the spatial density consistency of movable parts. In addition, we explore two occupancy grid sampling strategies to facilitate training efficiency. We conduct extensive experiments on the proposed benchmark, showcasing the challenges of the task and the superiority of our approach.
SSF-PAN: Semantic Scene Flow-Based Perception for Autonomous Navigation in Traffic Scenarios
Jan 28, 2025Vehicle detection and localization in complex traffic scenarios pose significant challenges due to the interference of moving objects. Traditional methods often rely on outlier exclusions or semantic segmentations, which suffer from low computational efficiency and accuracy. The proposed SSF-PAN can achieve the functionalities of LiDAR point cloud based object detection/localization and SLAM (Simultaneous Localization and Mapping) with high computational efficiency and accuracy, enabling map-free navigation frameworks. The novelty of this work is threefold: 1) developing a neural network which can achieve segmentation among static and dynamic objects within the scene flows with different motion features, that is, semantic scene flow (SSF); 2) developing an iterative framework which can further optimize the quality of input scene flows and output segmentation results; 3) developing a scene flow-based navigation platform which can test the performance of the SSF perception system in the simulation environment. The proposed SSF-PAN method is validated using the SUScape-CARLA and the KITTI datasets, as well as on the CARLA simulator. Experimental results demonstrate that the proposed approach outperforms traditional methods in terms of scene flow computation accuracy, moving object detection accuracy, computational efficiency, and autonomous navigation effectiveness.
TSceneJAL: Joint Active Learning of Traffic Scenes for 3D Object Detection
Dec 25, 2024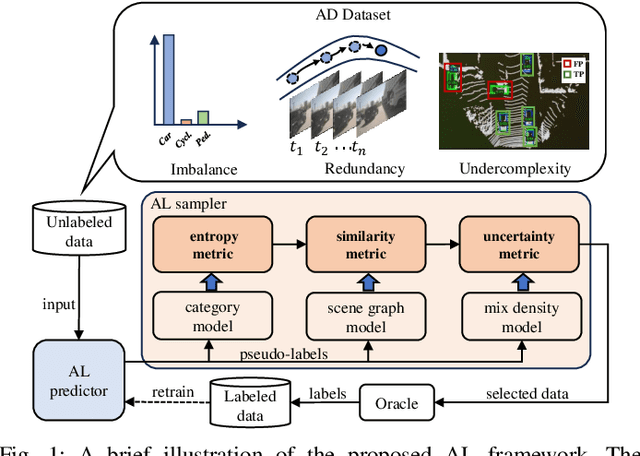
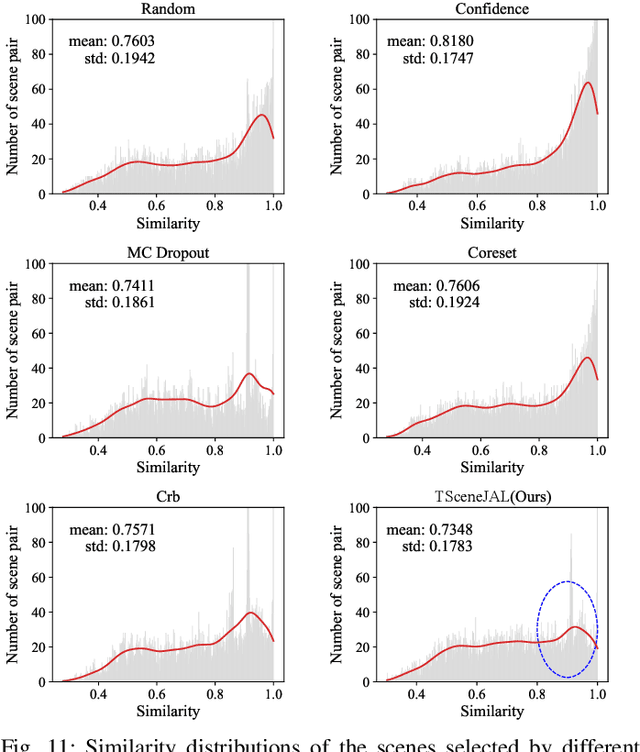
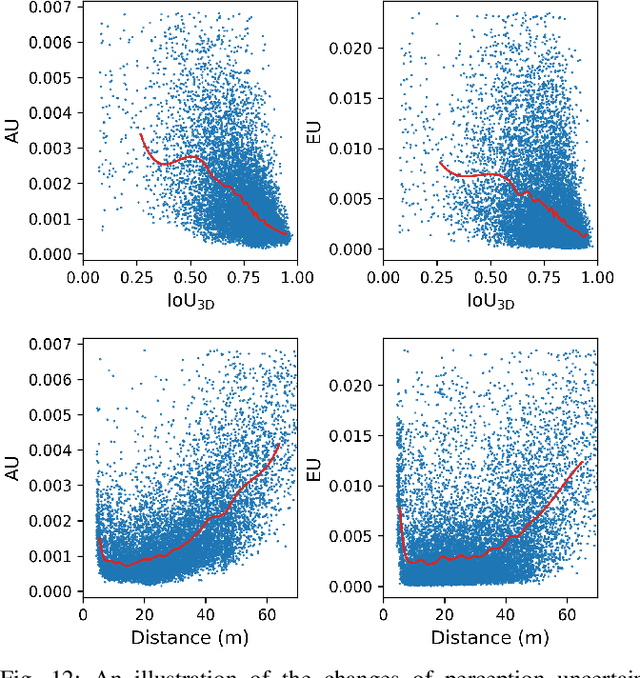
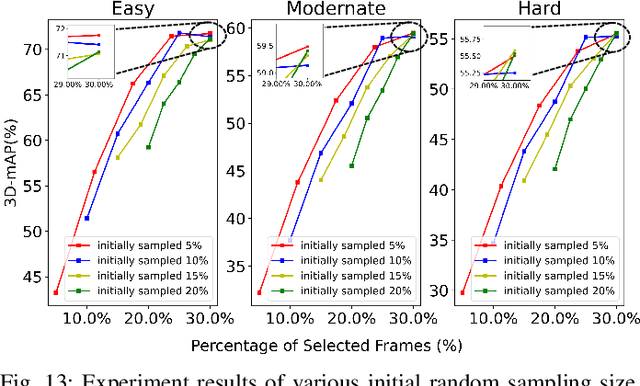
Most autonomous driving (AD) datasets incur substantial costs for collection and labeling, inevitably yielding a plethora of low-quality and redundant data instances, thereby compromising performance and efficiency. Many applications in AD systems necessitate high-quality training datasets using both existing datasets and newly collected data. In this paper, we propose a traffic scene joint active learning (TSceneJAL) framework that can efficiently sample the balanced, diverse, and complex traffic scenes from both labeled and unlabeled data. The novelty of this framework is threefold: 1) a scene sampling scheme based on a category entropy, to identify scenes containing multiple object classes, thus mitigating class imbalance for the active learner; 2) a similarity sampling scheme, estimated through the directed graph representation and a marginalize kernel algorithm, to pick sparse and diverse scenes; 3) an uncertainty sampling scheme, predicted by a mixture density network, to select instances with the most unclear or complex regression outcomes for the learner. Finally, the integration of these three schemes in a joint selection strategy yields an optimal and valuable subdataset. Experiments on the KITTI, Lyft, nuScenes and SUScape datasets demonstrate that our approach outperforms existing state-of-the-art methods on 3D object detection tasks with up to 12% improvements.