 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiFusion: A Unified Framework for Enhanced Cross-Model Reasoning via LLM Fusion
Jan 06, 2025
Large Language Models (LLMs) have demonstrated strong performance across various reasoning tasks, yet building a single model that consistently excels across all domains remains challenging. This paper addresses this problem by exploring strategies to integrate multiple domain-specialized models into an efficient pivot model.We propose two fusion strategies to combine the strengths of multiple LLMs: (1) a pairwise, multi-step fusion approach that sequentially distills each source model into the pivot model, followed by a weight merging step to integrate the distilled models into the final model. This method achieves strong performance but requires substantial training effort; and (2) a unified fusion approach that aggregates all source models' outputs simultaneously.To improve the fusion process, we introduce a novel Rate-Skewness Adaptive Fusion (RSAF) technique, which dynamically adjusts top-K ratios during parameter merging for enhanced flexibility and stability.Furthermore, we propose an uncertainty-based weighting method for the unified approach, which dynamically balances the contributions of source models and outperforms other logits/distribution ensemble methods.We achieved accuracy improvements of 9.27%, 8.80%, and 8.89% on the GSM8K, MATH, and HumanEval tasks, respectively.
TSceneJAL: Joint Active Learning of Traffic Scenes for 3D Object Detection
Dec 25, 2024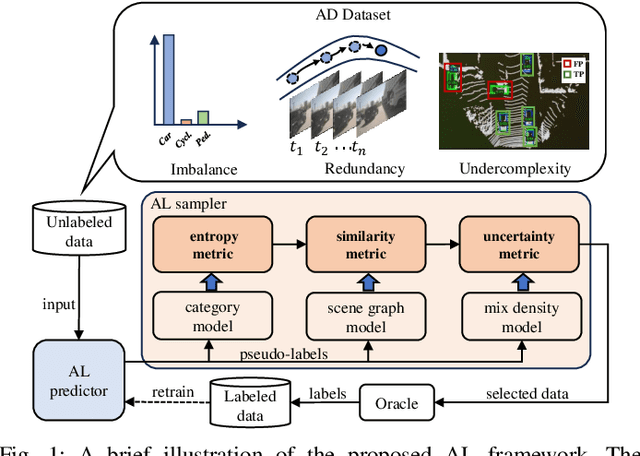
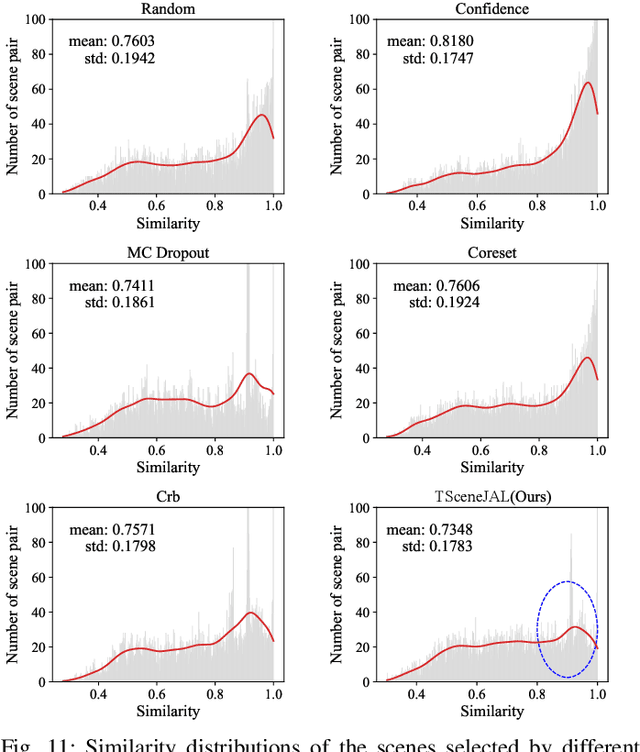
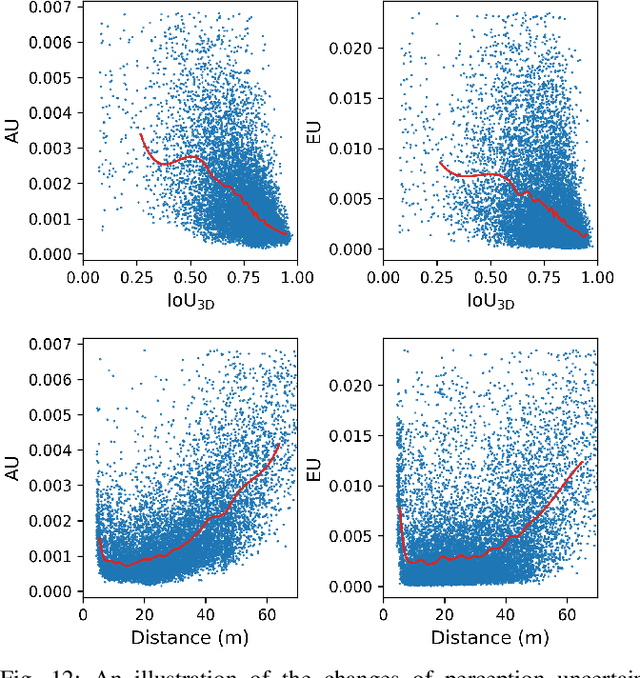
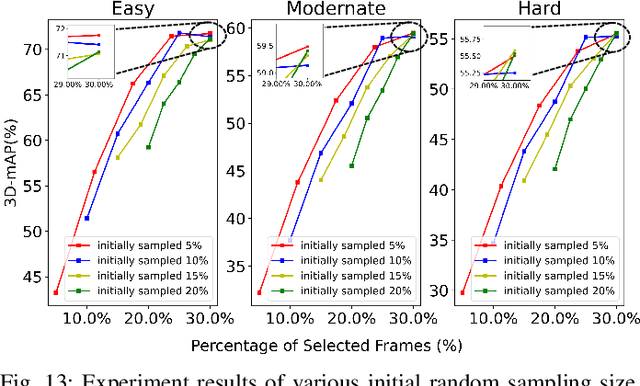
Most autonomous driving (AD) datasets incur substantial costs for collection and labeling, inevitably yielding a plethora of low-quality and redundant data instances, thereby compromising performance and efficiency. Many applications in AD systems necessitate high-quality training datasets using both existing datasets and newly collected data. In this paper, we propose a traffic scene joint active learning (TSceneJAL) framework that can efficiently sample the balanced, diverse, and complex traffic scenes from both labeled and unlabeled data. The novelty of this framework is threefold: 1) a scene sampling scheme based on a category entropy, to identify scenes containing multiple object classes, thus mitigating class imbalance for the active learner; 2) a similarity sampling scheme, estimated through the directed graph representation and a marginalize kernel algorithm, to pick sparse and diverse scenes; 3) an uncertainty sampling scheme, predicted by a mixture density network, to select instances with the most unclear or complex regression outcomes for the learner. Finally, the integration of these three schemes in a joint selection strategy yields an optimal and valuable subdataset. Experiments on the KITTI, Lyft, nuScenes and SUScape datasets demonstrate that our approach outperforms existing state-of-the-art methods on 3D object detection tasks with up to 12% improvements.
Unconstrained Model Merging for Enhanced LLM Reasoning
Oct 17, 2024



Recent advancements in building domain-specific large language models (LLMs) have shown remarkable success, especially in tasks requiring reasoning abilities like logical inference over complex relationships and multi-step problem solving. However, creating a powerful all-in-one LLM remains challenging due to the need for proprietary data and vast computational resources. As a resource-friendly alternative, we explore the potential of merging multiple expert models into a single LLM. Existing studies on model merging mainly focus on generalist LLMs instead of domain experts, or the LLMs under the same architecture and size. In this work, we propose an unconstrained model merging framework that accommodates both homogeneous and heterogeneous model architectures with a focus on reasoning tasks. A fine-grained layer-wise weight merging strategy is designed for homogeneous models merging, while heterogeneous model merging is built upon the probabilistic distribution knowledge derived from instruction-response fine-tuning data. Across 7 benchmarks and 9 reasoning-optimized LLMs, we reveal key findings that combinatorial reasoning emerges from merging which surpasses simple additive effects. We propose that unconstrained model merging could serve as a foundation for decentralized LLMs, marking a notable progression from the existing centralized LLM framework. This evolution could enhance wider participation and stimulate additional advancement in the field of artificial intelligence, effectively addressing the constraints posed by centralized models.
CTS: Sim-to-Real Unsupervised Domain Adaptation on 3D Detection
Jun 26, 2024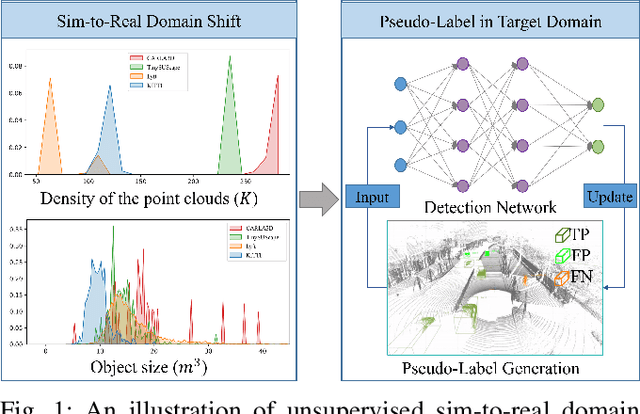
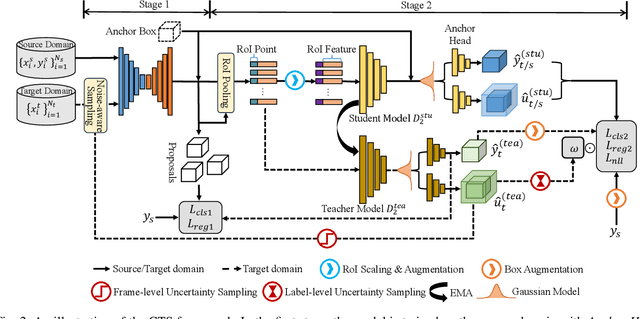
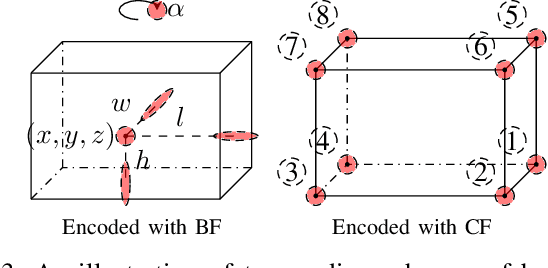
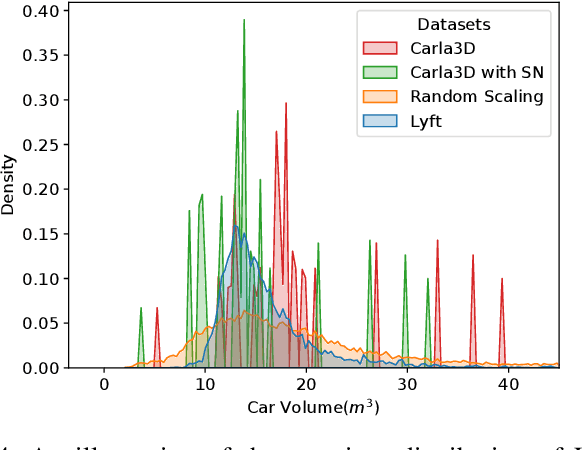
Simulation data can be accurately labeled and have been expected to improve the performance of data-driven algorithms, including object detection. However, due to the various domain inconsistencies from simulation to reality (sim-to-real), cross-domain object detection algorithms usually suffer from dramatic performance drops. While numerous unsupervised domain adaptation (UDA) methods have been developed to address cross-domain tasks between real-world datasets, progress in sim-to-real remains limited. This paper presents a novel Complex-to-Simple (CTS) framework to transfer models from labeled simulation (source) to unlabeled reality (target) domains. Based on a two-stage detector, the novelty of this work is threefold: 1) developing fixed-size anchor heads and RoI augmentation to address size bias and feature diversity between two domains, thereby improving the quality of pseudo-label; 2) developing a novel corner-format representation of aleatoric uncertainty (AU) for the bounding box, to uniformly quantify pseudo-label quality; 3) developing a noise-aware mean teacher domain adaptation method based on AU, as well as object-level and frame-level sampling strategies, to migrate the impact of noisy labels. Experimental results demonstrate that our proposed approach significantly enhances the sim-to-real domain adaptation capability of 3D object detection models, outperforming state-of-the-art cross-domain algorithms, which are usually developed for real-to-real UDA tasks.
Prototypical Model with Novel Information-theoretic Loss Function for Generalized Zero Shot Learning
Dec 06, 2021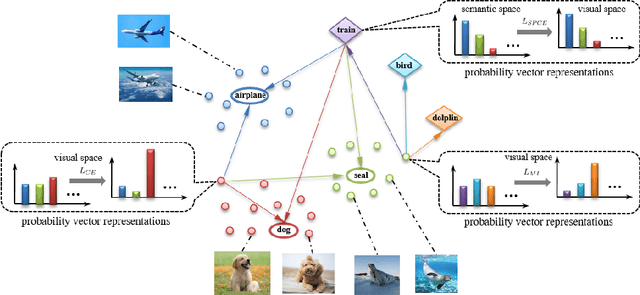
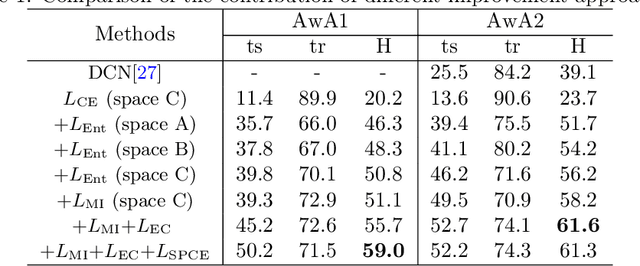
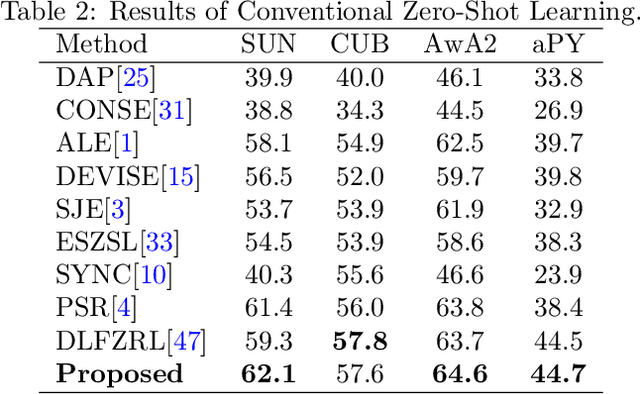
Generalized zero shot learning (GZSL) is still a technical challenge of deep learning as it has to recognize both source and target classes without data from target classes. To preserve the semantic relation between source and target classes when only trained with data from source classes, we address the quantification of the knowledge transfer and semantic relation from an information-theoretic viewpoint. To this end, we follow the prototypical model and format the variables of concern as a probability vector. Leveraging on the proposed probability vector representation, the information measurement such as mutual information and entropy, can be effectively evaluated with simple closed forms. We discuss the choice of common embedding space and distance function when using the prototypical model. Then We propose three information-theoretic loss functions for deterministic GZSL model: a mutual information loss to bridge seen data and target classes; an uncertainty-aware entropy constraint loss to prevent overfitting when using seen data to learn the embedding of target classes; a semantic preserving cross entropy loss to preserve the semantic relation when mapping the semantic representations to the common space. Simulation shows that, as a deterministic model, our proposed method obtains state of the art results on GZSL benchmark datasets. We achieve 21%-64% improvements over the baseline model -- deep calibration network (DCN) and for the first time demonstrate a deterministic model can perform as well as generative ones. Moreover, our proposed model is compatible with generative models. Simulation studies show that by incorporating with f-CLSWGAN, we obtain comparable results compared with advanced generative models.
Stochastic Variational Inference via Upper Bound
Dec 02, 2019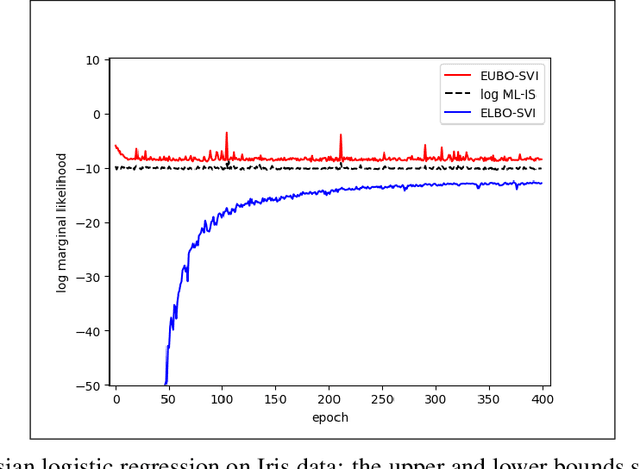
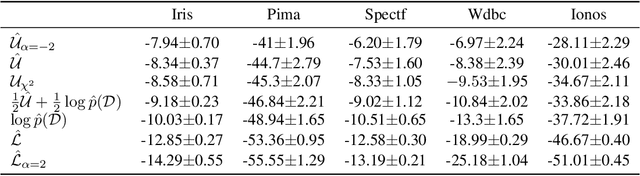
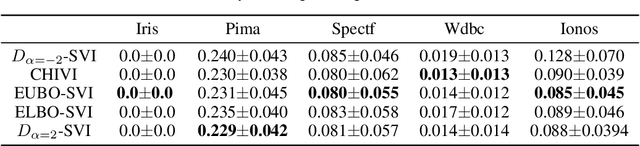
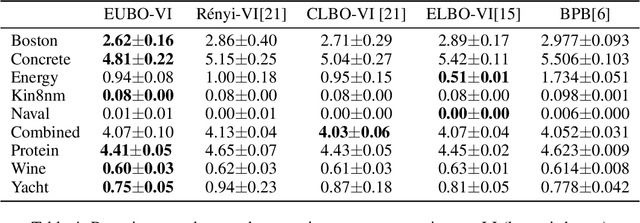
Stochastic variational inference (SVI) plays a key role in Bayesian deep learning. Recently various divergences have been proposed to design the surrogate loss for variational inference. We present a simple upper bound of the evidence as the surrogate loss. This evidence upper bound (EUBO) equals to the log marginal likelihood plus the KL-divergence between the posterior and the proposal. We show that the proposed EUBO is tighter than previous upper bounds introduced by $\chi$-divergence or $\alpha$-divergence. To facilitate scalable inference, we present the numerical approximation of the gradient of the EUBO and apply the SGD algorithm to optimize the variational parameters iteratively. Simulation study with Bayesian logistic regression shows that the upper and lower bounds well sandwich the evidence and the proposed upper bound is favorably tight. For Bayesian neural network, the proposed EUBO-VI algorithm outperforms state-of-the-art results for various examples.