 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTS: Sim-to-Real Unsupervised Domain Adaptation on 3D Detection
Jun 26, 2024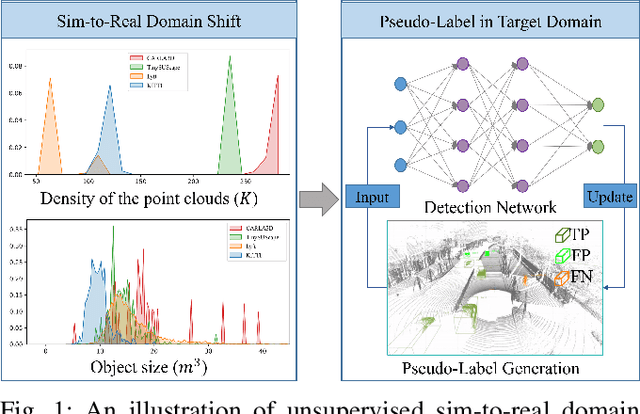
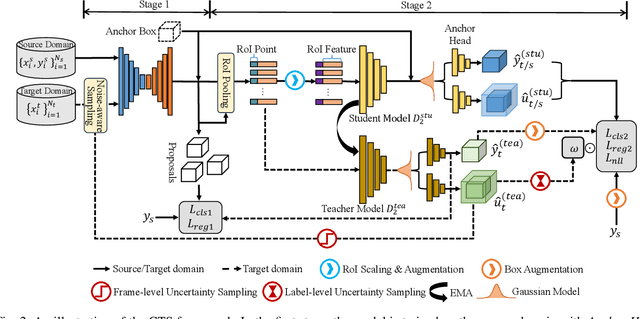
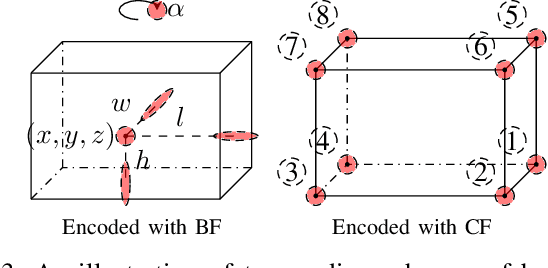
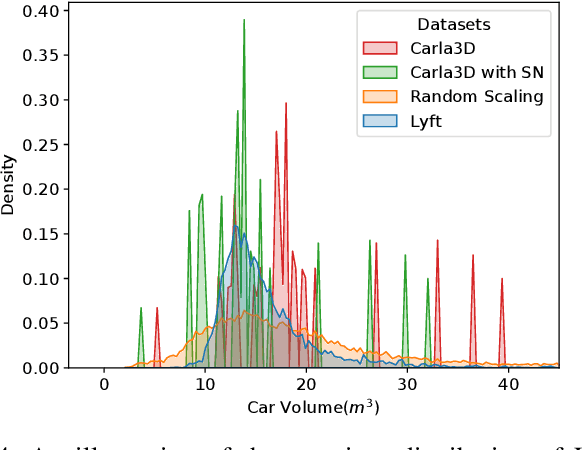
Simulation data can be accurately labeled and have been expected to improve the performance of data-driven algorithms, including object detection. However, due to the various domain inconsistencies from simulation to reality (sim-to-real), cross-domain object detection algorithms usually suffer from dramatic performance drops. While numerous unsupervised domain adaptation (UDA) methods have been developed to address cross-domain tasks between real-world datasets, progress in sim-to-real remains limited. This paper presents a novel Complex-to-Simple (CTS) framework to transfer models from labeled simulation (source) to unlabeled reality (target) domains. Based on a two-stage detector, the novelty of this work is threefold: 1) developing fixed-size anchor heads and RoI augmentation to address size bias and feature diversity between two domains, thereby improving the quality of pseudo-label; 2) developing a novel corner-format representation of aleatoric uncertainty (AU) for the bounding box, to uniformly quantify pseudo-label quality; 3) developing a noise-aware mean teacher domain adaptation method based on AU, as well as object-level and frame-level sampling strategies, to migrate the impact of noisy labels. Experimental results demonstrate that our proposed approach significantly enhances the sim-to-real domain adaptation capability of 3D object detection models, outperforming state-of-the-art cross-domain algorithms, which are usually developed for real-to-real UDA tasks.
Accelerating DNN Training in Wireless Federated Edge Learning System
May 23, 2019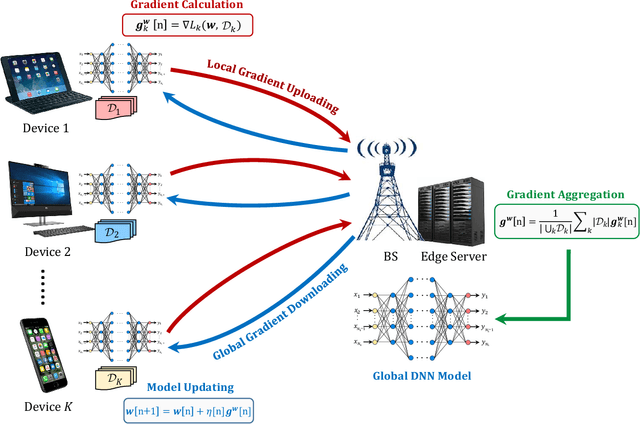
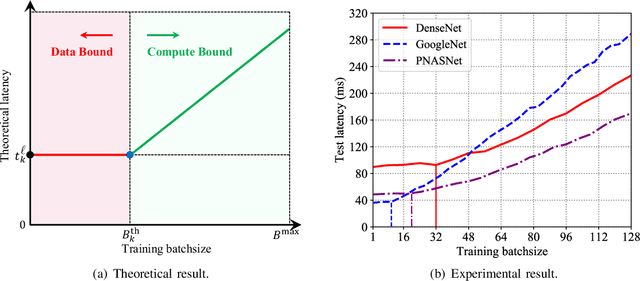
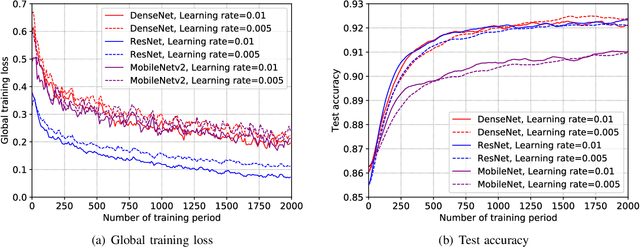
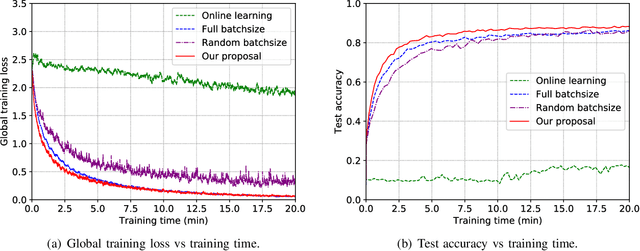
Training task in classical machine learning models, such as deep neural networks (DNN), is generally implemented at the remote computationally-adequate cloud center for centralized learning, which is typically time-consuming and resource-hungry. It also incurs serious privacy issue and long communication latency since massive data are transmitted to the centralized node. To overcome these shortcomings, we consider a newly-emerged framework, namely federated edge learning (FEEL), to aggregate the local learning updates at the edge server instead of users' raw data. Aiming at accelerating the training process while guaranteeing the learning accuracy, we first define a novel performance evaluation criterion, called learning efficiency and formulate a training acceleration optimization problem in the CPU scenario, where each user device is equipped with CPU. The closed-form expressions for joint batchsize selection and communication resource allocation are developed and some insightful results are also highlighted. Further, we extend our learning framework into the GPU scenario and propose a novel training function to characterize the learning property of general GPU modules. The optimal solution in this case is manifested to have the similar structure as that of the CPU scenario, recommending that our proposed algorithm is applicable in more general systems. Finally, extensive experiments validate our theoretical analysis and demonstrate that our proposal can reduce the training time and improve the learning accuracy simultaneously.