 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating DNN Training in Wireless Federated Edge Learning System
Paper and Code
May 23, 2019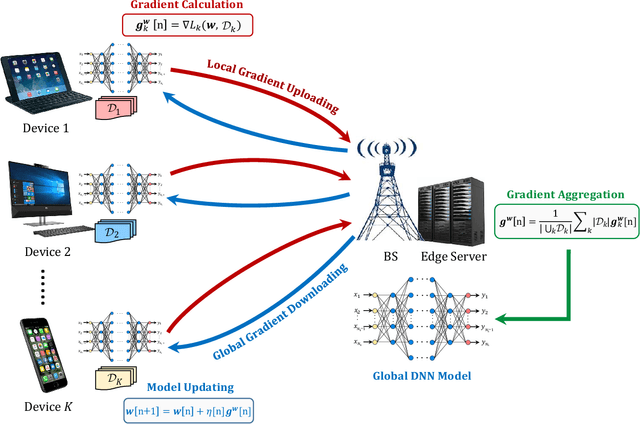
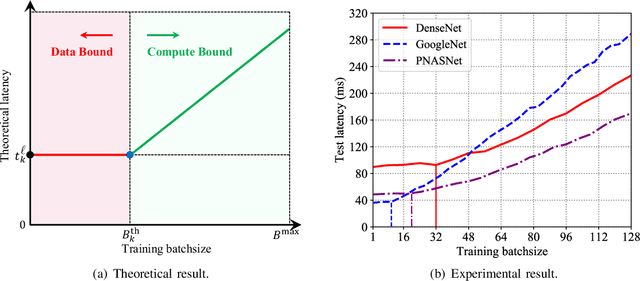
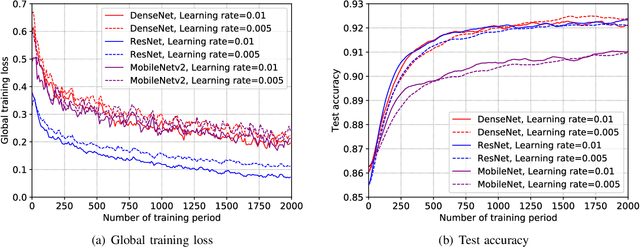
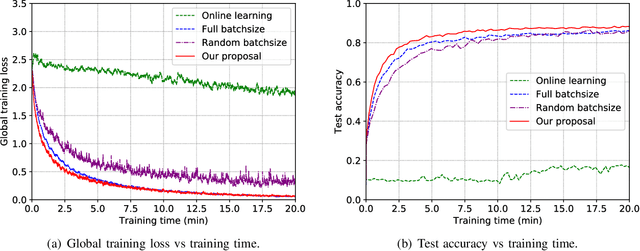
Training task in classical machine learning models, such as deep neural networks (DNN), is generally implemented at the remote computationally-adequate cloud center for centralized learning, which is typically time-consuming and resource-hungry. It also incurs serious privacy issue and long communication latency since massive data are transmitted to the centralized node. To overcome these shortcomings, we consider a newly-emerged framework, namely federated edge learning (FEEL), to aggregate the local learning updates at the edge server instead of users' raw data. Aiming at accelerating the training process while guaranteeing the learning accuracy, we first define a novel performance evaluation criterion, called learning efficiency and formulate a training acceleration optimization problem in the CPU scenario, where each user device is equipped with CPU. The closed-form expressions for joint batchsize selection and communication resource allocation are developed and some insightful results are also highlighted. Further, we extend our learning framework into the GPU scenario and propose a novel training function to characterize the learning property of general GPU modules. The optimal solution in this case is manifested to have the similar structure as that of the CPU scenario, recommending that our proposed algorithm is applicable in more general systems. Finally, extensive experiments validate our theoretical analysis and demonstrate that our proposal can reduce the training time and improve the learning accuracy simultaneously.