 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoMA: A Real-to-Sim Neural Simulator for Robotic Soft-body Manipulation
Feb 02, 2026Simulating deformable objects under rich interactions remains a fundamental challenge for real-to-sim robot manipulation, with dynamics jointly driven by environmental effects and robot actions. Existing simulators rely on predefined physics or data-driven dynamics without robot-conditioned control, limiting accuracy, stability, and generalization. This paper presents SoMA, a 3D Gaussian Splat simulator for soft-body manipulation. SoMA couples deformable dynamics, environmental forces, and robot joint actions in a unified latent neural space for end-to-end real-to-sim simulation. Modeling interactions over learned Gaussian splats enables controllable, stable long-horizon manipulation and generalization beyond observed trajectories without predefined physical models. SoMA improves resimulation accuracy and generalization on real-world robot manipulation by 20%, enabling stable simulation of complex tasks such as long-horizon cloth folding.
EAG-PT: Emission-Aware Gaussians and Path Tracing for Indoor Scene Reconstruction and Editing
Jan 30, 2026Recent reconstruction methods based on radiance field such as NeRF and 3DGS reproduce indoor scenes with high visual fidelity, but break down under scene editing due to baked illumination and the lack of explicit light transport. In contrast, physically based inverse rendering relies on mesh representations and path tracing, which enforce correct light transport but place strong requirements on geometric fidelity, becoming a practical bottleneck for real indoor scenes. In this work, we propose Emission-Aware Gaussians and Path Tracing (EAG-PT), aiming for physically based light transport with a unified 2D Gaussian representation. Our design is based on three cores: (1) using 2D Gaussians as a unified scene representation and transport-friendly geometry proxy that avoids reconstructed mesh, (2) explicitly separating emissive and non-emissive components during reconstruction for further scene editing, and (3) decoupling reconstruction from final rendering by using efficient single-bounce optimization and high-quality multi-bounce path tracing after scene editing. Experiments on synthetic and real indoor scenes show that EAG-PT produces more natural and physically consistent renders after editing than radiant scene reconstructions, while preserving finer geometric detail and avoiding mesh-induced artifacts compared to mesh-based inverse path tracing. These results suggest promising directions for future use in interior design, XR content creation, and embodied AI.
PLANING: A Loosely Coupled Triangle-Gaussian Framework for Streaming 3D Reconstruction
Jan 29, 2026Streaming reconstruction from monocular image sequences remains challenging, as existing methods typically favor either high-quality rendering or accurate geometry, but rarely both. We present PLANING, an efficient on-the-fly reconstruction framework built on a hybrid representation that loosely couples explicit geometric primitives with neural Gaussians, enabling geometry and appearance to be modeled in a decoupled manner. This decoupling supports an online initialization and optimization strategy that separates geometry and appearance updates, yielding stable streaming reconstruction with substantially reduced structural redundancy. PLANING improves dense mesh Chamfer-L2 by 18.52% over PGSR, surpasses ARTDECO by 1.31 dB PSNR, and reconstructs ScanNetV2 scenes in under 100 seconds, over 5x faster than 2D Gaussian Splatting, while matching the quality of offline per-scene optimization. Beyond reconstruction quality, the structural clarity and computational efficiency of \modelname~make it well suited for a broad range of downstream applications, such as enabling large-scale scene modeling and simulation-ready environments for embodied AI. Project page: https://city-super.github.io/PLANING/ .
MeshSplat: Generalizable Sparse-View Surface Reconstruction via Gaussian Splatting
Aug 25, 2025Surface reconstruction has been widely studied in computer vision and graphics. However, existing surface reconstruction works struggle to recover accurate scene geometry when the input views are extremely sparse. To address this issue, we propose MeshSplat, a generalizable sparse-view surface reconstruction framework via Gaussian Splatting. Our key idea is to leverage 2DGS as a bridge, which connects novel view synthesis to learned geometric priors and then transfers these priors to achieve surface reconstruction. Specifically, we incorporate a feed-forward network to predict per-view pixel-aligned 2DGS, which enables the network to synthesize novel view images and thus eliminates the need for direct 3D ground-truth supervision. To improve the accuracy of 2DGS position and orientation prediction, we propose a Weighted Chamfer Distance Loss to regularize the depth maps, especially in overlapping areas of input views, and also a normal prediction network to align the orientation of 2DGS with normal vectors predicted by a monocular normal estimator. Extensive experiments validate the effectiveness of our proposed improvement, demonstrating that our method achieves state-of-the-art performance in generalizable sparse-view mesh reconstruction tasks. Project Page: https://hanzhichang.github.io/meshsplat_web
Direct Numerical Layout Generation for 3D Indoor Scene Synthesis via Spatial Reasoning
Jun 05, 2025Realistic 3D indoor scene synthesis is vital for embodied AI and digital content creation. It can be naturally divided into two subtasks: object generation and layout generation. While recent generative models have significantly advanced object-level quality and controllability, layout generation remains challenging due to limited datasets. Existing methods either overfit to these datasets or rely on predefined constraints to optimize numerical layout that sacrifice flexibility. As a result, they fail to generate scenes that are both open-vocabulary and aligned with fine-grained user instructions. We introduce DirectLayout, a framework that directly generates numerical 3D layouts from text descriptions using generalizable spatial reasoning of large language models (LLMs). DirectLayout decomposes the generation into three stages: producing a Bird's-Eye View (BEV) layout, lifting it into 3D space, and refining object placements. To enable explicit spatial reasoning and help the model grasp basic principles of object placement, we employ Chain-of-Thought (CoT) Activation based on the 3D-Front dataset. Additionally, we design CoT-Grounded Generative Layout Reward to enhance generalization and spatial planning. During inference, DirectLayout addresses asset-layout mismatches via Iterative Asset-Layout Alignment through in-context learning. Extensive experiments demonstrate that DirectLayout achieves impressive semantic consistency, generalization and physical plausibility.
AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views
May 29, 2025We introduce AnySplat, a feed forward network for novel view synthesis from uncalibrated image collections. In contrast to traditional neural rendering pipelines that demand known camera poses and per scene optimization, or recent feed forward methods that buckle under the computational weight of dense views, our model predicts everything in one shot. A single forward pass yields a set of 3D Gaussian primitives encoding both scene geometry and appearance, and the corresponding camera intrinsics and extrinsics for each input image. This unified design scales effortlessly to casually captured, multi view datasets without any pose annotations. In extensive zero shot evaluations, AnySplat matches the quality of pose aware baselines in both sparse and dense view scenarios while surpassing existing pose free approaches. Moreover, it greatly reduce rendering latency compared to optimization based neural fields, bringing real time novel view synthesis within reach for unconstrained capture settings.Project page: https://city-super.github.io/anysplat/
MV-CoLight: Efficient Object Compositing with Consistent Lighting and Shadow Generation
May 27, 2025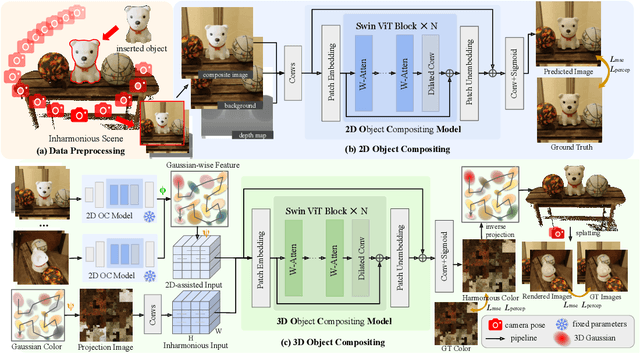
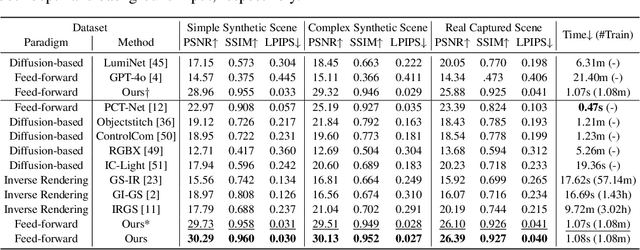
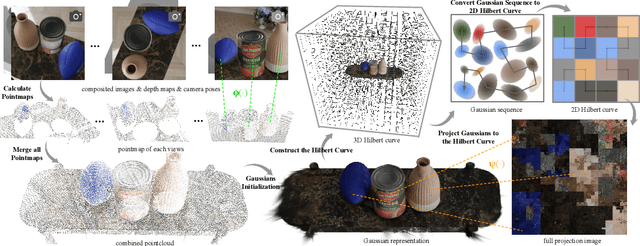
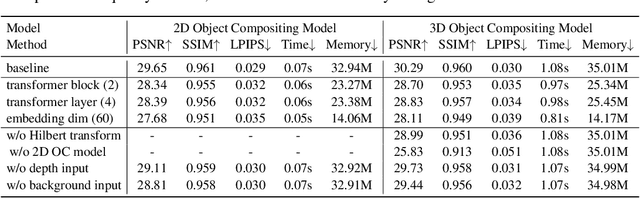
Object compositing offers significant promise for augmented reality (AR) and embodied intelligence applications. Existing approaches predominantly focus on single-image scenarios or intrinsic decomposition techniques, facing challenges with multi-view consistency, complex scenes, and diverse lighting conditions. Recent inverse rendering advancements, such as 3D Gaussian and diffusion-based methods, have enhanced consistency but are limited by scalability, heavy data requirements, or prolonged reconstruction time per scene. To broaden its applicability, we introduce MV-CoLight, a two-stage framework for illumination-consistent object compositing in both 2D images and 3D scenes. Our novel feed-forward architecture models lighting and shadows directly, avoiding the iterative biases of diffusion-based methods. We employ a Hilbert curve-based mapping to align 2D image inputs with 3D Gaussian scene representations seamlessly. To facilitate training and evaluation, we further introduce a large-scale 3D compositing dataset. Experiments demonstrate state-of-the-art harmonized results across standard benchmarks and our dataset, as well as casually captured real-world scenes demonstrate the framework's robustness and wide generalization.
HaloGS: Loose Coupling of Compact Geometry and Gaussian Splats for 3D Scenes
May 26, 2025



High fidelity 3D reconstruction and rendering hinge on capturing precise geometry while preserving photo realistic detail. Most existing methods either fuse these goals into a single cumbersome model or adopt hybrid schemes whose uniform primitives lead to a trade off between efficiency and fidelity. In this paper, we introduce HaloGS, a dual representation that loosely couples coarse triangles for geometry with Gaussian primitives for appearance, motivated by the lightweight classic geometry representations and their proven efficiency in real world applications. Our design yields a compact yet expressive model capable of photo realistic rendering across both indoor and outdoor environments, seamlessly adapting to varying levels of scene complexity. Experiments on multiple benchmark datasets demonstrate that our method yields both compact, accurate geometry and high fidelity renderings, especially in challenging scenarios where robust geometric structure make a clear difference.
Inter3D: A Benchmark and Strong Baseline for Human-Interactive 3D Object Reconstruction
Feb 19, 2025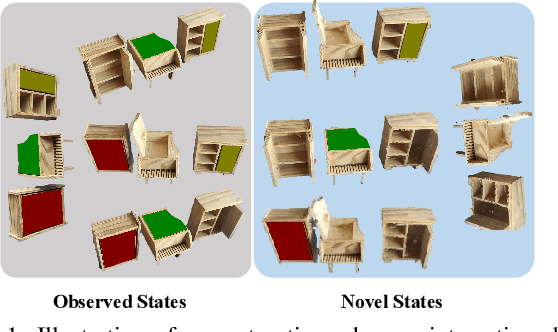

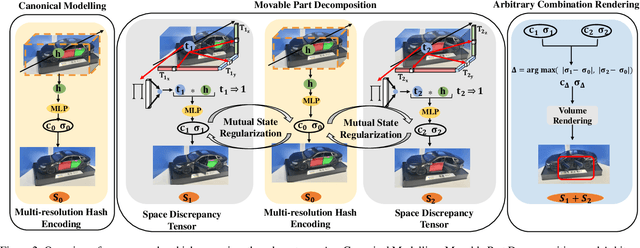

Recent advancements in implicit 3D reconstruction methods, e.g., neural rendering fields and Gaussian splatting, have primarily focused on novel view synthesis of static or dynamic objects with continuous motion states. However, these approaches struggle to efficiently model a human-interactive object with n movable parts, requiring 2^n separate models to represent all discrete states. To overcome this limitation, we propose Inter3D, a new benchmark and approach for novel state synthesis of human-interactive objects. We introduce a self-collected dataset featuring commonly encountered interactive objects and a new evaluation pipeline, where only individual part states are observed during training, while part combination states remain unseen. We also propose a strong baseline approach that leverages Space Discrepancy Tensors to efficiently modelling all states of an object. To alleviate the impractical constraints on camera trajectories across training states, we propose a Mutual State Regularization mechanism to enhance the spatial density consistency of movable parts. In addition, we explore two occupancy grid sampling strategies to facilitate training efficiency. We conduct extensive experiments on the proposed benchmark, showcasing the challenges of the task and the superiority of our approach.
Proc-GS: Procedural Building Generation for City Assembly with 3D Gaussians
Dec 10, 2024



Buildings are primary components of cities, often featuring repeated elements such as windows and doors. Traditional 3D building asset creation is labor-intensive and requires specialized skills to develop design rules. Recent generative models for building creation often overlook these patterns, leading to low visual fidelity and limited scalability. Drawing inspiration from procedural modeling techniques used in the gaming and visual effects industry, our method, Proc-GS, integrates procedural code into the 3D Gaussian Splatting (3D-GS) framework, leveraging their advantages in high-fidelity rendering and efficient asset management from both worlds. By manipulating procedural code, we can streamline this process and generate an infinite variety of buildings. This integration significantly reduces model size by utilizing shared foundational assets, enabling scalable generation with precise control over building assembly. We showcase the potential for expansive cityscape generation while maintaining high rendering fidelity and precise control on both real and synthetic cases.