 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRynnBrain: Open Embodied Foundation Models
Feb 13, 2026Despite rapid progress in multimodal foundation models, embodied intelligence community still lacks a unified, physically grounded foundation model that integrates perception, reasoning, and planning within real-world spatial-temporal dynamics. We introduce RynnBrain, an open-source spatiotemporal foundation model for embodied intelligence. RynnBrain strengthens four core capabilities in a unified framework: comprehensive egocentric understanding, diverse spatiotemporal localization, physically grounded reasoning, and physics-aware planning. The RynnBrain family comprises three foundation model scales (2B, 8B, and 30B-A3B MoE) and four post-trained variants tailored for downstream embodied tasks (i.e., RynnBrain-Nav, RynnBrain-Plan, and RynnBrain-VLA) or complex spatial reasoning tasks (i.e., RynnBrain-CoP). In terms of extensive evaluations on 20 embodied benchmarks and 8 general vision understanding benchmarks, our RynnBrain foundation models largely outperform existing embodied foundation models by a significant margin. The post-trained model suite further substantiates two key potentials of the RynnBrain foundation model: (i) enabling physically grounded reasoning and planning, and (ii) serving as a strong pretrained backbone that can be efficiently adapted to diverse embodied tasks.
InspecSafe-V1: A Multimodal Benchmark for Safety Assessment in Industrial Inspection Scenarios
Jan 29, 2026With the rapid development of industrial intelligence and unmanned inspection, reliable perception and safety assessment for AI systems in complex and dynamic industrial sites has become a key bottleneck for deploying predictive maintenance and autonomous inspection. Most public datasets remain limited by simulated data sources, single-modality sensing, or the absence of fine-grained object-level annotations, which prevents robust scene understanding and multimodal safety reasoning for industrial foundation models. To address these limitations, InspecSafe-V1 is released as the first multimodal benchmark dataset for industrial inspection safety assessment that is collected from routine operations of real inspection robots in real-world environments. InspecSafe-V1 covers five representative industrial scenarios, including tunnels, power facilities, sintering equipment, oil and gas petrochemical plants, and coal conveyor trestles. The dataset is constructed from 41 wheeled and rail-mounted inspection robots operating at 2,239 valid inspection sites, yielding 5,013 inspection instances. For each instance, pixel-level segmentation annotations are provided for key objects in visible-spectrum images. In addition, a semantic scene description and a corresponding safety level label are provided according to practical inspection tasks. Seven synchronized sensing modalities are further included, including infrared video, audio, depth point clouds, radar point clouds, gas measurements, temperature, and humidity, to support multimodal anomaly recognition, cross-modal fusion, and comprehensive safety assessment in industrial environments.
Vision-Language-Action Models for Autonomous Driving: Past, Present, and Future
Dec 18, 2025Autonomous driving has long relied on modular "Perception-Decision-Action" pipelines, where hand-crafted interfaces and rule-based components often break down in complex or long-tailed scenarios. Their cascaded design further propagates perception errors, degrading downstream planning and control. Vision-Action (VA) models address some limitations by learning direct mappings from visual inputs to actions, but they remain opaque, sensitive to distribution shifts, and lack structured reasoning or instruction-following capabilities. Recent progress in Large Language Models (LLMs) and multimodal learning has motivated the emergence of Vision-Language-Action (VLA) frameworks, which integrate perception with language-grounded decision making. By unifying visual understanding, linguistic reasoning, and actionable outputs, VLAs offer a pathway toward more interpretable, generalizable, and human-aligned driving policies. This work provides a structured characterization of the emerging VLA landscape for autonomous driving. We trace the evolution from early VA approaches to modern VLA frameworks and organize existing methods into two principal paradigms: End-to-End VLA, which integrates perception, reasoning, and planning within a single model, and Dual-System VLA, which separates slow deliberation (via VLMs) from fast, safety-critical execution (via planners). Within these paradigms, we further distinguish subclasses such as textual vs. numerical action generators and explicit vs. implicit guidance mechanisms. We also summarize representative datasets and benchmarks for evaluating VLA-based driving systems and highlight key challenges and open directions, including robustness, interpretability, and instruction fidelity. Overall, this work aims to establish a coherent foundation for advancing human-compatible autonomous driving systems.
Token Expand-Merge: Training-Free Token Compression for Vision-Language-Action Models
Dec 10, 2025Vision-Language-Action (VLA) models pretrained on large-scale multimodal datasets have emerged as powerful foundations for robotic perception and control. However, their massive scale, often billions of parameters, poses significant challenges for real-time deployment, as inference becomes computationally expensive and latency-sensitive in dynamic environments. To address this, we propose Token Expand-and-Merge-VLA (TEAM-VLA), a training-free token compression framework that accelerates VLA inference while preserving task performance. TEAM-VLA introduces a dynamic token expansion mechanism that identifies and samples additional informative tokens in the spatial vicinity of attention-highlighted regions, enhancing contextual completeness. These expanded tokens are then selectively merged in deeper layers under action-aware guidance, effectively reducing redundancy while maintaining semantic coherence. By coupling expansion and merging within a single feed-forward pass, TEAM-VLA achieves a balanced trade-off between efficiency and effectiveness, without any retraining or parameter updates. Extensive experiments on LIBERO benchmark demonstrate that TEAM-VLA consistently improves inference speed while maintaining or even surpassing the task success rate of full VLA models. The code is public available on \href{https://github.com/Jasper-aaa/TEAM-VLA}{https://github.com/Jasper-aaa/TEAM-VLA}
VLSA: Vision-Language-Action Models with Plug-and-Play Safety Constraint Layer
Dec 09, 2025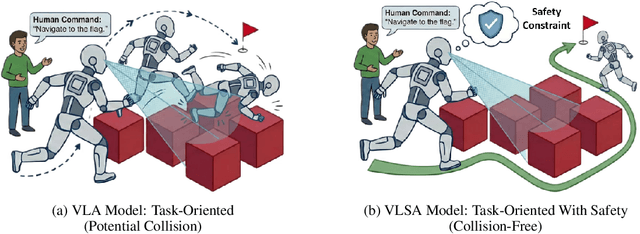
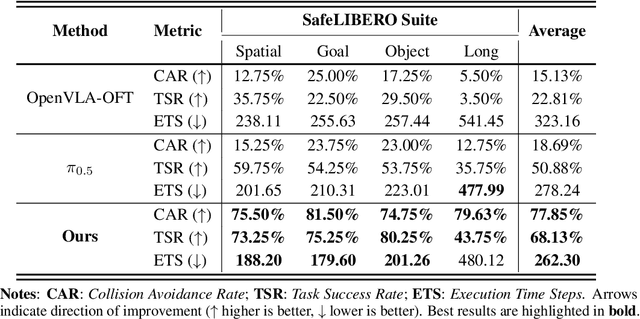
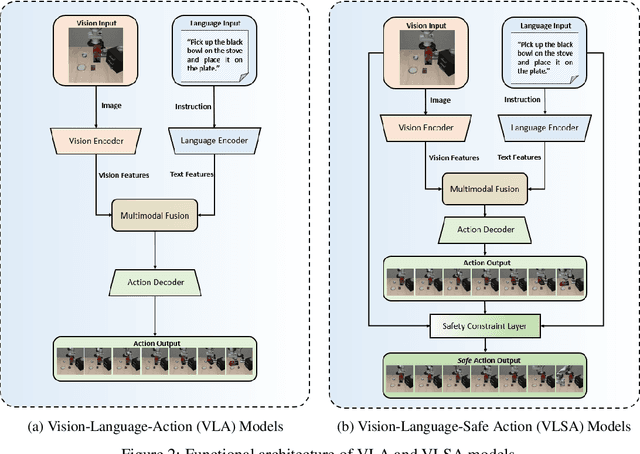
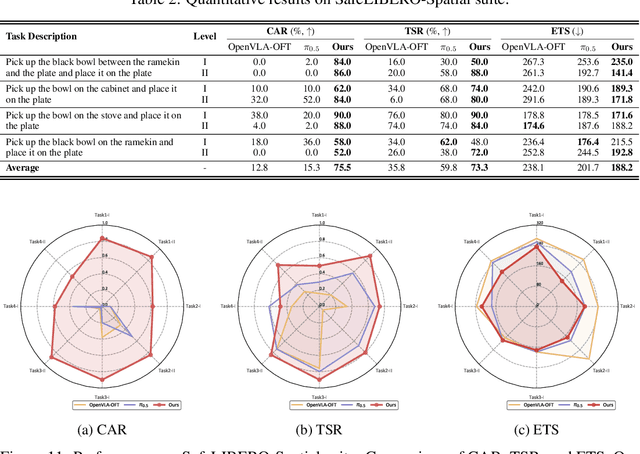
Vision-Language-Action (VLA) models have demonstrated remarkable capabilities in generalizing across diverse robotic manipulation tasks. However, deploying these models in unstructured environments remains challenging due to the critical need for simultaneous task compliance and safety assurance, particularly in preventing potential collisions during physical interactions. In this work, we introduce a Vision-Language-Safe Action (VLSA) architecture, named AEGIS, which contains a plug-and-play safety constraint (SC) layer formulated via control barrier functions. AEGIS integrates directly with existing VLA models to improve safety with theoretical guarantees, while maintaining their original instruction-following performance. To evaluate the efficacy of our architecture, we construct a comprehensive safety-critical benchmark SafeLIBERO, spanning distinct manipulation scenarios characterized by varying degrees of spatial complexity and obstacle intervention. Extensive experiments demonstrate the superiority of our method over state-of-the-art baselines. Notably, AEGIS achieves a 59.16% improvement in obstacle avoidance rate while substantially increasing the task execution success rate by 17.25%. To facilitate reproducibility and future research, we make our code, models, and the benchmark datasets publicly available at https://vlsa-aegis.github.io/.
RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation
Sep 18, 2025This paper presents RynnVLA-001, a vision-language-action(VLA) model built upon large-scale video generative pretraining from human demonstrations. We propose a novel two-stage pretraining methodology. The first stage, Ego-Centric Video Generative Pretraining, trains an Image-to-Video model on 12M ego-centric manipulation videos to predict future frames conditioned on an initial frame and a language instruction. The second stage, Human-Centric Trajectory-Aware Modeling, extends this by jointly predicting future keypoint trajectories, thereby effectively bridging visual frame prediction with action prediction. Furthermore, to enhance action representation, we propose ActionVAE, a variational autoencoder that compresses sequences of actions into compact latent embeddings, reducing the complexity of the VLA output space. When finetuned on the same downstream robotics datasets, RynnVLA-001 achieves superior performance over state-of-the-art baselines, demonstrating that the proposed pretraining strategy provides a more effective initialization for VLA models.
Towards Affordance-Aware Robotic Dexterous Grasping with Human-like Priors
Aug 12, 2025A dexterous hand capable of generalizable grasping objects is fundamental for the development of general-purpose embodied AI. However, previous methods focus narrowly on low-level grasp stability metrics, neglecting affordance-aware positioning and human-like poses which are crucial for downstream manipulation. To address these limitations, we propose AffordDex, a novel framework with two-stage training that learns a universal grasping policy with an inherent understanding of both motion priors and object affordances. In the first stage, a trajectory imitator is pre-trained on a large corpus of human hand motions to instill a strong prior for natural movement. In the second stage, a residual module is trained to adapt these general human-like motions to specific object instances. This refinement is critically guided by two components: our Negative Affordance-aware Segmentation (NAA) module, which identifies functionally inappropriate contact regions, and a privileged teacher-student distillation process that ensures the final vision-based policy is highly successful. Extensive experiments demonstrate that AffordDex not only achieves universal dexterous grasping but also remains remarkably human-like in posture and functionally appropriate in contact location. As a result, AffordDex significantly outperforms state-of-the-art baselines across seen objects, unseen instances, and even entirely novel categories.
WorldVLA: Towards Autoregressive Action World Model
Jun 26, 2025We present WorldVLA, an autoregressive action world model that unifies action and image understanding and generation. Our WorldVLA intergrates Vision-Language-Action (VLA) model and world model in one single framework. The world model predicts future images by leveraging both action and image understanding, with the purpose of learning the underlying physics of the environment to improve action generation. Meanwhile, the action model generates the subsequent actions based on image observations, aiding in visual understanding and in turn helps visual generation of the world model. We demonstrate that WorldVLA outperforms standalone action and world models, highlighting the mutual enhancement between the world model and the action model. In addition, we find that the performance of the action model deteriorates when generating sequences of actions in an autoregressive manner. This phenomenon can be attributed to the model's limited generalization capability for action prediction, leading to the propagation of errors from earlier actions to subsequent ones. To address this issue, we propose an attention mask strategy that selectively masks prior actions during the generation of the current action, which shows significant performance improvement in the action chunk generation task.
MathFlow: Enhancing the Perceptual Flow of MLLMs for Visual Mathematical Problems
Mar 19, 2025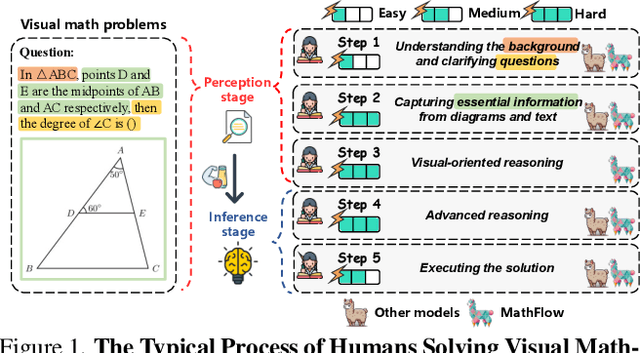
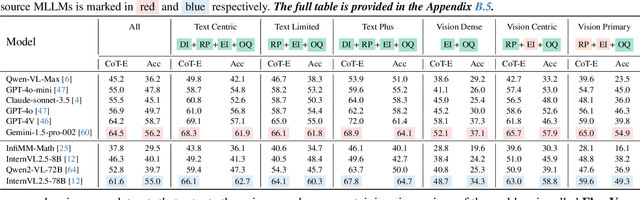
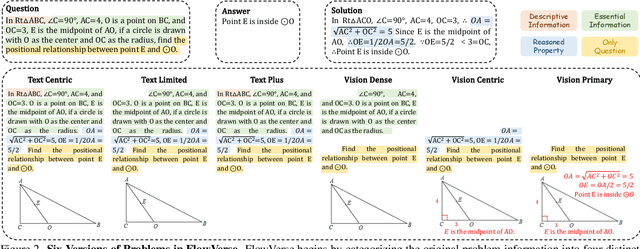
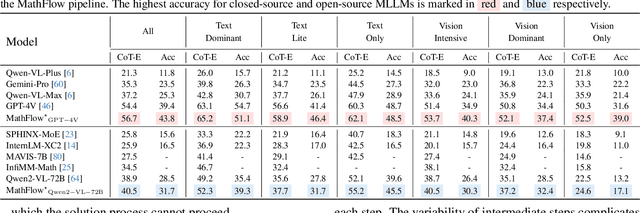
Despite impressive performance across diverse tasks, Multimodal Large Language Models (MLLMs) have yet to fully demonstrate their potential in visual mathematical problem-solving, particularly in accurately perceiving and interpreting diagrams. Inspired by typical processes of humans, we hypothesize that the perception capabilities to extract meaningful information from diagrams is crucial, as it directly impacts subsequent inference processes. To validate this hypothesis, we developed FlowVerse, a comprehensive benchmark that categorizes all information used during problem-solving into four components, which are then combined into six problem versions for evaluation. Our preliminary results on FlowVerse reveal that existing MLLMs exhibit substantial limitations when extracting essential information and reasoned property from diagrams and performing complex reasoning based on these visual inputs. In response, we introduce MathFlow, a modular problem-solving pipeline that decouples perception and inference into distinct stages, thereby optimizing each independently. Given the perceptual limitations observed in current MLLMs, we trained MathFlow-P-7B as a dedicated perception model. Experimental results indicate that MathFlow-P-7B yields substantial performance gains when integrated with various closed-source and open-source inference models. This demonstrates the effectiveness of the MathFlow pipeline and its compatibility to diverse inference frameworks. The FlowVerse benchmark and code are available at https://github.com/MathFlow-zju/MathFlow.
Generative Artificial Intelligence in Robotic Manipulation: A Survey
Mar 05, 2025



This survey provides a comprehensive review on recent advancements of generative learning models in robotic manipulation, addressing key challenges in the field. Robotic manipulation faces critical bottlenecks, including significant challenges in insufficient data and inefficient data acquisition, long-horizon and complex task planning, and the multi-modality reasoning ability for robust policy learning performance across diverse environments. To tackle these challenges, this survey introduces several generative model paradigms, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), diffusion models, probabilistic flow models, and autoregressive models, highlighting their strengths and limitations. The applications of these models are categorized into three hierarchical layers: the Foundation Layer, focusing on data generation and reward generation; the Intermediate Layer, covering language, code, visual, and state generation; and the Policy Layer, emphasizing grasp generation and trajectory generation. Each layer is explored in detail, along with notable works that have advanced the state of the art. Finally, the survey outlines future research directions and challenges, emphasizing the need for improved efficiency in data utilization, better handling of long-horizon tasks, and enhanced generalization across diverse robotic scenarios. All the related resources, including research papers, open-source data, and projects, are collected for the community in https://github.com/GAI4Manipulation/AwesomeGAIManipulation