 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMOST: Incremental Memory Mechanism with Online Self-Supervision for Continual Traversability Learning
Sep 21, 2024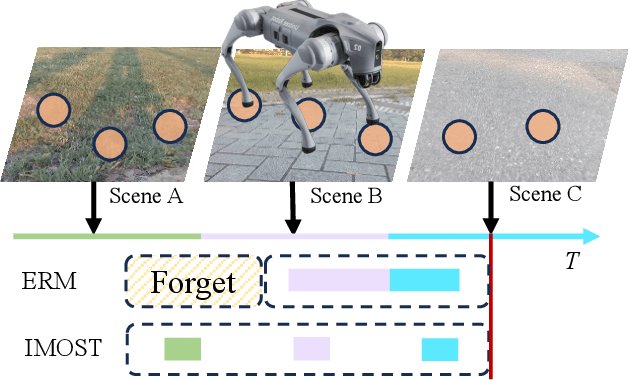
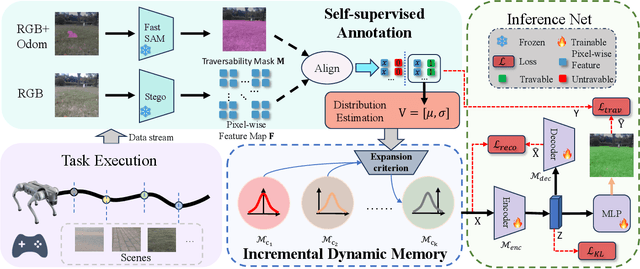


Traversability estimation is the foundation of path planning for a general navigation system. However, complex and dynamic environments pose challenges for the latest methods using self-supervised learning (SSL) technique. Firstly, existing SSL-based methods generate sparse annotations lacking detailed boundary information. Secondly, their strategies focus on hard samples for rapid adaptation, leading to forgetting and biased predictions. In this work, we propose IMOST, a continual traversability learning framework composed of two key modules: incremental dynamic memory (IDM) and self-supervised annotation (SSA). By mimicking human memory mechanisms, IDM allocates novel data samples to new clusters according to information expansion criterion. It also updates clusters based on diversity rule, ensuring a representative characterization of new scene. This mechanism enhances scene-aware knowledge diversity while maintaining a compact memory capacity. The SSA module, integrating FastSAM, utilizes point prompts to generate complete annotations in real time which reduces training complexity. Furthermore, IMOST has been successfully deployed on the quadruped robot, with performance evaluated during the online learning process. Experimental results on both public and self-collected datasets demonstrate that our IMOST outperforms current state-of-the-art method, maintains robust recognition capabilities and adaptability across various scenarios. The code is available at https://github.com/SJTU-MKH/OCLTrav.
iControl3D: An Interactive System for Controllable 3D Scene Generation
Aug 03, 2024

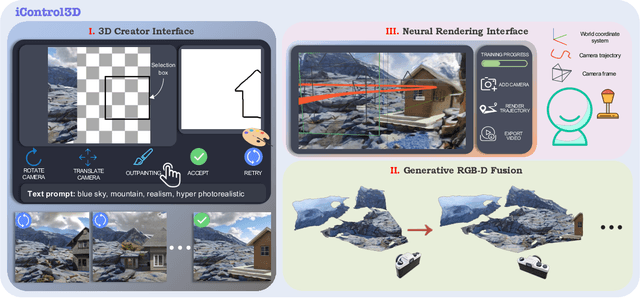
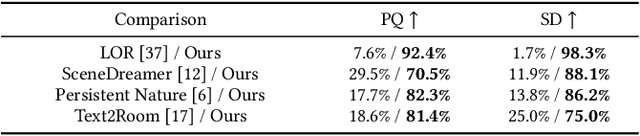
3D content creation has long been a complex and time-consuming process, often requiring specialized skills and resources. While recent advancements have allowed for text-guided 3D object and scene generation, they still fall short of providing sufficient control over the generation process, leading to a gap between the user's creative vision and the generated results. In this paper, we present iControl3D, a novel interactive system that empowers users to generate and render customizable 3D scenes with precise control. To this end, a 3D creator interface has been developed to provide users with fine-grained control over the creation process. Technically, we leverage 3D meshes as an intermediary proxy to iteratively merge individual 2D diffusion-generated images into a cohesive and unified 3D scene representation. To ensure seamless integration of 3D meshes, we propose to perform boundary-aware depth alignment before fusing the newly generated mesh with the existing one in 3D space. Additionally, to effectively manage depth discrepancies between remote content and foreground, we propose to model remote content separately with an environment map instead of 3D meshes. Finally, our neural rendering interface enables users to build a radiance field of their scene online and navigate the entire scene. Extensive experiments have been conducted to demonstrate the effectiveness of our system. The code will be made available at https://github.com/xingyi-li/iControl3D.
Pseudo-Labeling by Multi-Policy Viewfinder Network for Image Cropping
Jul 02, 2024



Automatic image cropping models predict reframing boxes to enhance image aesthetics. Yet, the scarcity of labeled data hinders the progress of this task. To overcome this limitation, we explore the possibility of utilizing both labeled and unlabeled data together to expand the scale of training data for image cropping models. This idea can be implemented in a pseudo-labeling way: producing pseudo labels for unlabeled data by a teacher model and training a student model with these pseudo labels. However, the student may learn from teacher's mistakes. To address this issue, we propose the multi-policy viewfinder network (MPV-Net) that offers diverse refining policies to rectify the mistakes in original pseudo labels from the teacher. The most reliable policy is selected to generate trusted pseudo labels. The reliability of policies is evaluated via the robustness against box jittering. The efficacy of our method can be evaluated by the improvement compared to the supervised baseline which only uses labeled data. Notably, our MPV-Net outperforms off-the-shelf pseudo-labeling methods, yielding the most substantial improvement over the supervised baseline. Furthermore, our approach achieves state-of-the-art results on both the FCDB and FLMS datasets, signifying the superiority of our approach.
Instance Consistency Regularization for Semi-Supervised 3D Instance Segmentation
Jun 24, 2024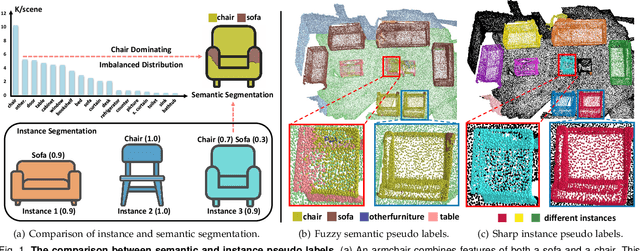
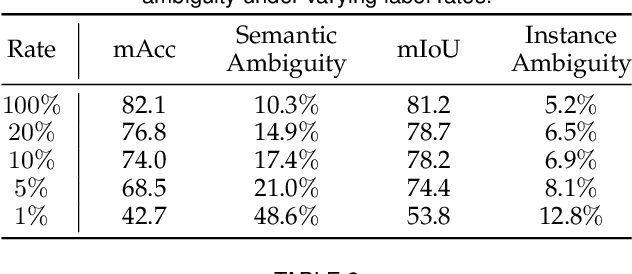
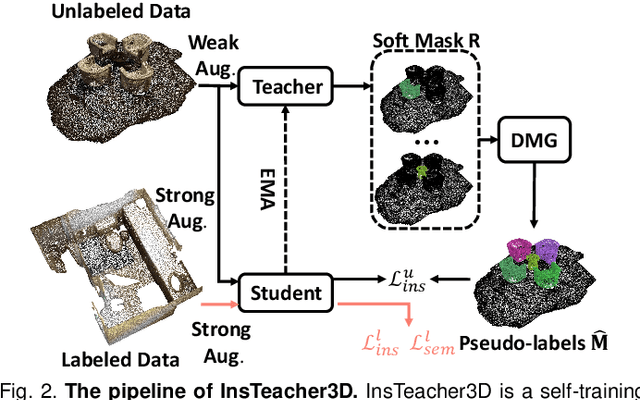

Large-scale datasets with point-wise semantic and instance labels are crucial to 3D instance segmentation but also expensive. To leverage unlabeled data, previous semi-supervised 3D instance segmentation approaches have explored self-training frameworks, which rely on high-quality pseudo labels for consistency regularization. They intuitively utilize both instance and semantic pseudo labels in a joint learning manner. However, semantic pseudo labels contain numerous noise derived from the imbalanced category distribution and natural confusion of similar but distinct categories, which leads to severe collapses in self-training. Motivated by the observation that 3D instances are non-overlapping and spatially separable, we ask whether we can solely rely on instance consistency regularization for improved semi-supervised segmentation. To this end, we propose a novel self-training network InsTeacher3D to explore and exploit pure instance knowledge from unlabeled data. We first build a parallel base 3D instance segmentation model DKNet, which distinguishes each instance from the others via discriminative instance kernels without reliance on semantic segmentation. Based on DKNet, we further design a novel instance consistency regularization framework to generate and leverage high-quality instance pseudo labels. Experimental results on multiple large-scale datasets show that the InsTeacher3D significantly outperforms prior state-of-the-art semi-supervised approaches. Code is available: https://github.com/W1zheng/InsTeacher3D.
Self-Supervised Class-Agnostic Motion Prediction with Spatial and Temporal Consistency Regularizations
Mar 21, 2024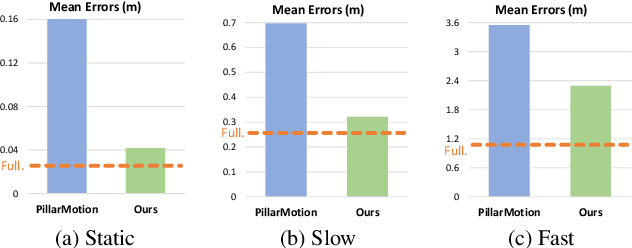
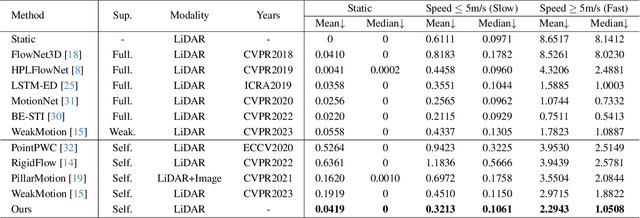
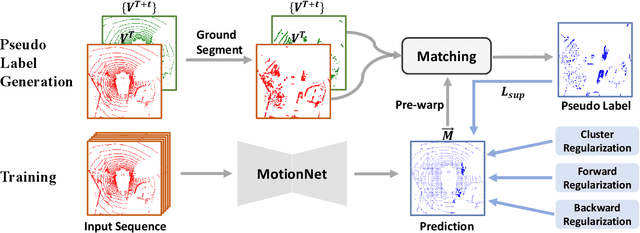
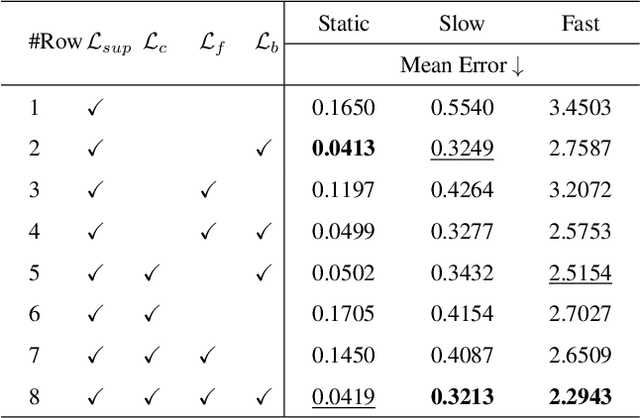
The perception of motion behavior in a dynamic environment holds significant importance for autonomous driving systems, wherein class-agnostic motion prediction methods directly predict the motion of the entire point cloud. While most existing methods rely on fully-supervised learning, the manual labeling of point cloud data is laborious and time-consuming. Therefore, several annotation-efficient methods have been proposed to address this challenge. Although effective, these methods rely on weak annotations or additional multi-modal data like images, and the potential benefits inherent in the point cloud sequence are still underexplored. To this end, we explore the feasibility of self-supervised motion prediction with only unlabeled LiDAR point clouds. Initially, we employ an optimal transport solver to establish coarse correspondences between current and future point clouds as the coarse pseudo motion labels. Training models directly using such coarse labels leads to noticeable spatial and temporal prediction inconsistencies. To mitigate these issues, we introduce three simple spatial and temporal regularization losses, which facilitate the self-supervised training process effectively. Experimental results demonstrate the significant superiority of our approach over the state-of-the-art self-supervised methods.
S-DyRF: Reference-Based Stylized Radiance Fields for Dynamic Scenes
Mar 13, 2024



Current 3D stylization methods often assume static scenes, which violates the dynamic nature of our real world. To address this limitation, we present S-DyRF, a reference-based spatio-temporal stylization method for dynamic neural radiance fields. However, stylizing dynamic 3D scenes is inherently challenging due to the limited availability of stylized reference images along the temporal axis. Our key insight lies in introducing additional temporal cues besides the provided reference. To this end, we generate temporal pseudo-references from the given stylized reference. These pseudo-references facilitate the propagation of style information from the reference to the entire dynamic 3D scene. For coarse style transfer, we enforce novel views and times to mimic the style details present in pseudo-references at the feature level. To preserve high-frequency details, we create a collection of stylized temporal pseudo-rays from temporal pseudo-references. These pseudo-rays serve as detailed and explicit stylization guidance for achieving fine style transfer. Experiments on both synthetic and real-world datasets demonstrate that our method yields plausible stylized results of space-time view synthesis on dynamic 3D scenes.
Semi-Supervised Class-Agnostic Motion Prediction with Pseudo Label Regeneration and BEVMix
Dec 14, 2023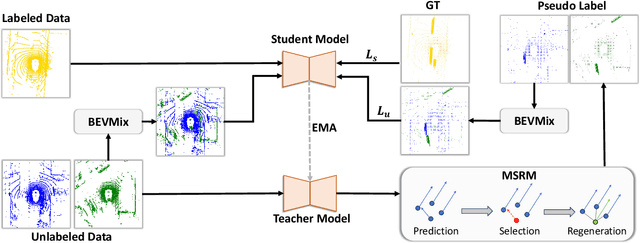
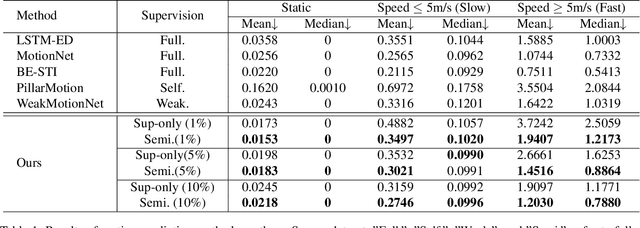
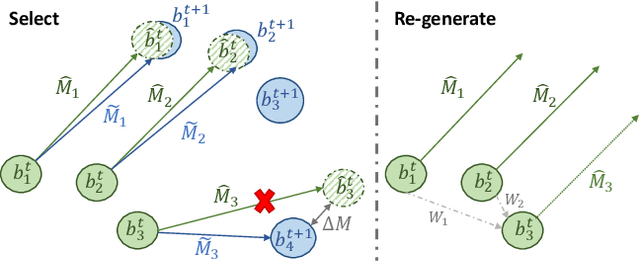
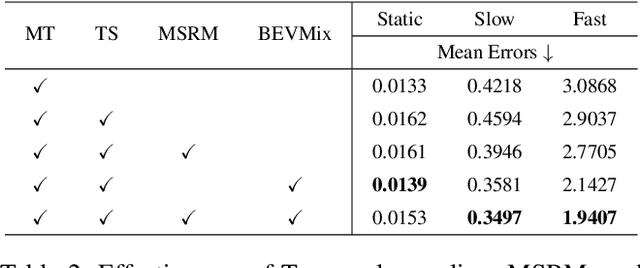
Class-agnostic motion prediction methods aim to comprehend motion within open-world scenarios, holding significance for autonomous driving systems. However, training a high-performance model in a fully-supervised manner always requires substantial amounts of manually annotated data, which can be both expensive and time-consuming to obtain. To address this challenge, our study explores the potential of semi-supervised learning (SSL) for class-agnostic motion prediction. Our SSL framework adopts a consistency-based self-training paradigm, enabling the model to learn from unlabeled data by generating pseudo labels through test-time inference. To improve the quality of pseudo labels, we propose a novel motion selection and re-generation module. This module effectively selects reliable pseudo labels and re-generates unreliable ones. Furthermore, we propose two data augmentation strategies: temporal sampling and BEVMix. These strategies facilitate consistency regularization in SSL. Experiments conducted on nuScenes demonstrate that our SSL method can surpass the self-supervised approach by a large margin by utilizing only a tiny fraction of labeled data. Furthermore, our method exhibits comparable performance to weakly and some fully supervised methods. These results highlight the ability of our method to strike a favorable balance between annotation costs and performance. Code will be available at https://github.com/kwwcv/SSMP.
SAD: Segment Any RGBD
May 23, 2023The Segment Anything Model (SAM) has demonstrated its effectiveness in segmenting any part of 2D RGB images. However, SAM exhibits a stronger emphasis on texture information while paying less attention to geometry information when segmenting RGB images. To address this limitation, we propose the Segment Any RGBD (SAD) model, which is specifically designed to extract geometry information directly from images. Inspired by the natural ability of humans to identify objects through the visualization of depth maps, SAD utilizes SAM to segment the rendered depth map, thus providing cues with enhanced geometry information and mitigating the issue of over-segmentation. We further include the open-vocabulary semantic segmentation in our framework, so that the 3D panoptic segmentation is fulfilled. The project is available on https://github.com/Jun-CEN/SegmentAnyRGBD.
Robust Object Detection With Inaccurate Bounding Boxes
Jul 20, 2022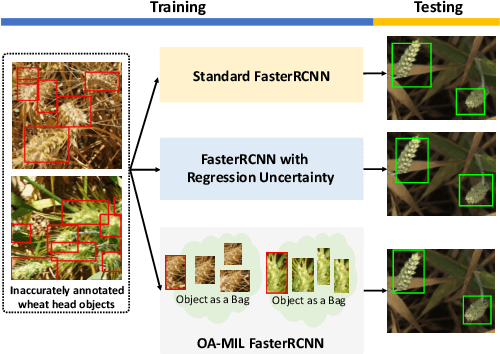
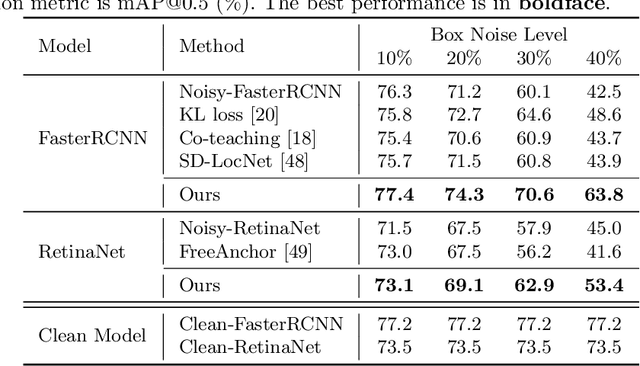
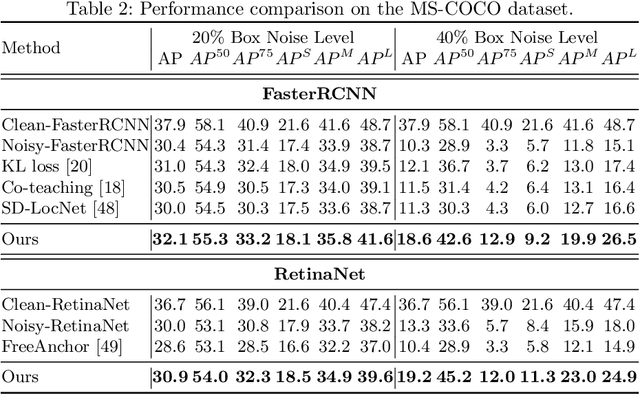
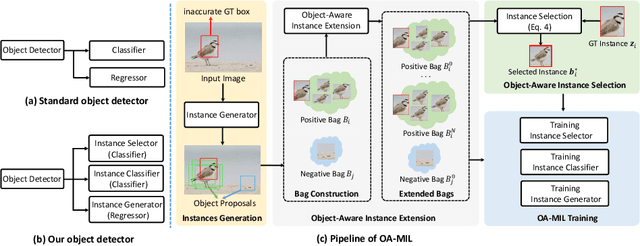
Learning accurate object detectors often requires large-scale training data with precise object bounding boxes. However, labeling such data is expensive and time-consuming. As the crowd-sourcing labeling process and the ambiguities of the objects may raise noisy bounding box annotations, the object detectors will suffer from the degenerated training data. In this work, we aim to address the challenge of learning robust object detectors with inaccurate bounding boxes. Inspired by the fact that localization precision suffers significantly from inaccurate bounding boxes while classification accuracy is less affected, we propose leveraging classification as a guidance signal for refining localization results. Specifically, by treating an object as a bag of instances, we introduce an Object-Aware Multiple Instance Learning approach (OA-MIL), featured with object-aware instance selection and object-aware instance extension. The former aims to select accurate instances for training, instead of directly using inaccurate box annotations. The latter focuses on generating high-quality instances for selection. Extensive experiments on synthetic noisy datasets (i.e., noisy PASCAL VOC and MS-COCO) and a real noisy wheat head dataset demonstrate the effectiveness of our OA-MIL. Code is available at https://github.com/cxliu0/OA-MIL.
SSR-HEF: Crowd Counting with Multi-Scale Semantic Refining and Hard Example Focusing
Apr 15, 2022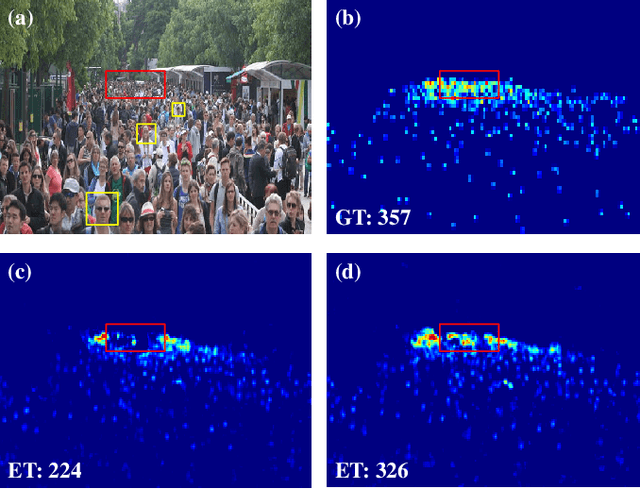
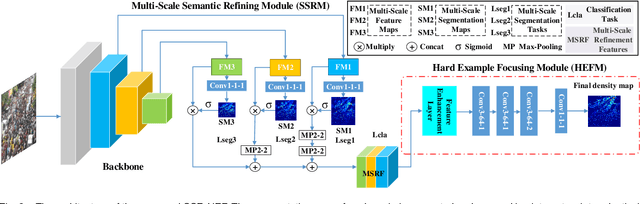
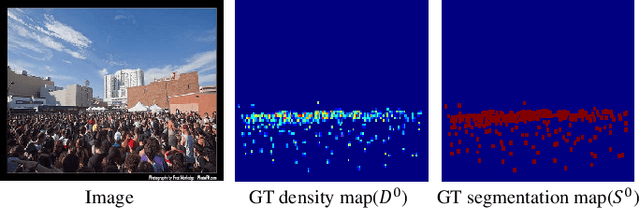
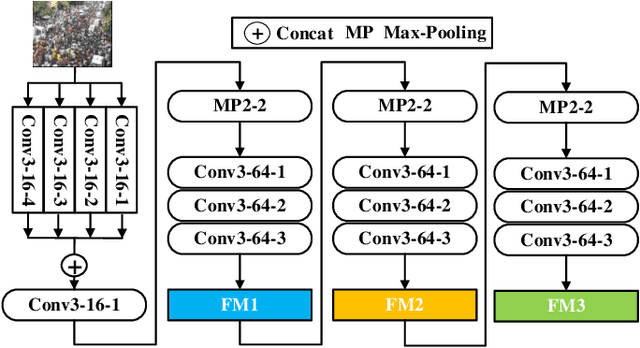
Crowd counting based on density maps is generally regarded as a regression task.Deep learning is used to learn the mapping between image content and crowd density distribution. Although great success has been achieved, some pedestrians far away from the camera are difficult to be detected. And the number of hard examples is often larger. Existing methods with simple Euclidean distance algorithm indiscriminately optimize the hard and easy examples so that the densities of hard examples are usually incorrectly predicted to be lower or even zero, which results in large counting errors. To address this problem, we are the first to propose the Hard Example Focusing(HEF) algorithm for the regression task of crowd counting. The HEF algorithm makes our model rapidly focus on hard examples by attenuating the contribution of easy examples.Then higher importance will be given to the hard examples with wrong estimations. Moreover, the scale variations in crowd scenes are large, and the scale annotations are labor-intensive and expensive. By proposing a multi-Scale Semantic Refining (SSR) strategy, lower layers of our model can break through the limitation of deep learning to capture semantic features of different scales to sufficiently deal with the scale variation. We perform extensive experiments on six benchmark datasets to verify the proposed method. Results indicate the superiority of our proposed method over the state-of-the-art methods. Moreover, our designed model is smaller and faster.
* Accepted by IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS