 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamingAssistant: Efficient Visual Token Pruning for Accelerating Online Video Understanding
Dec 14, 2025Online video understanding is essential for applications like public surveillance and AI glasses. However, applying Multimodal Large Language Models (MLLMs) to this domain is challenging due to the large number of video frames, resulting in high GPU memory usage and computational latency. To address these challenges, we propose token pruning as a means to reduce context length while retaining critical information. Specifically, we introduce a novel redundancy metric, Maximum Similarity to Spatially Adjacent Video Tokens (MSSAVT), which accounts for both token similarity and spatial position. To mitigate the bidirectional dependency between pruning and redundancy, we further design a masked pruning strategy that ensures only mutually unadjacent tokens are pruned. We also integrate an existing temporal redundancy-based pruning method to eliminate temporal redundancy of the video modality. Experimental results on multiple online and offline video understanding benchmarks demonstrate that our method significantly improves the accuracy (i.e., by 4\% at most) while incurring a negligible pruning latency (i.e., less than 1ms). Our full implementation will be made publicly available.
Using Left and Right Brains Together: Towards Vision and Language Planning
Feb 16, 2024



Large Language Models (LLMs) and Large Multi-modality Models (LMMs) have demonstrated remarkable decision masking capabilities on a variety of tasks. However, they inherently operate planning within the language space, lacking the vision and spatial imagination ability. In contrast, humans utilize both left and right hemispheres of the brain for language and visual planning during the thinking process. Therefore, we introduce a novel vision-language planning framework in this work to perform concurrent visual and language planning for tasks with inputs of any form. Our framework incorporates visual planning to capture intricate environmental details, while language planning enhances the logical coherence of the overall system. We evaluate the effectiveness of our framework across vision-language tasks, vision-only tasks, and language-only tasks. The results demonstrate the superior performance of our approach, indicating that the integration of visual and language planning yields better contextually aware task execution.
CMDFusion: Bidirectional Fusion Network with Cross-modality Knowledge Distillation for LIDAR Semantic Segmentation
Jul 09, 2023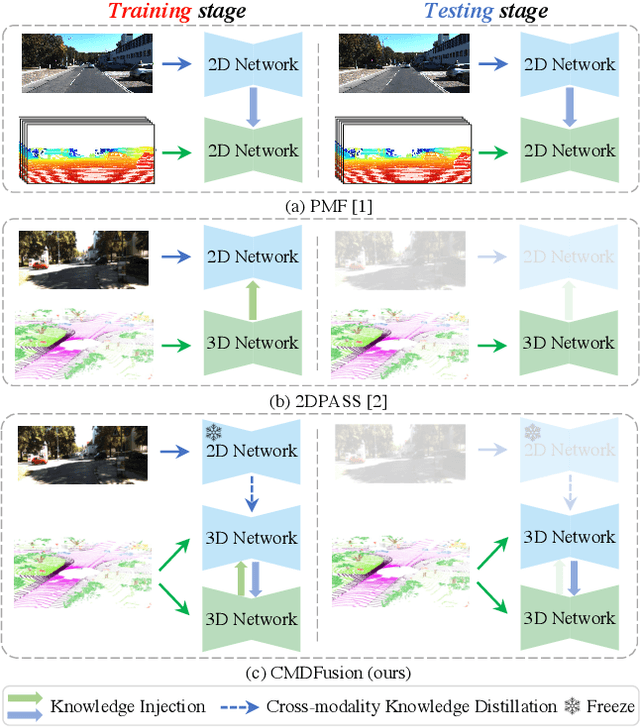
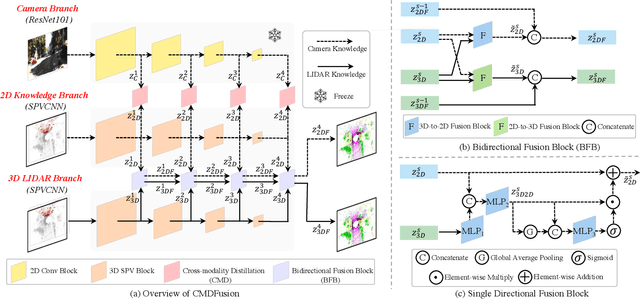
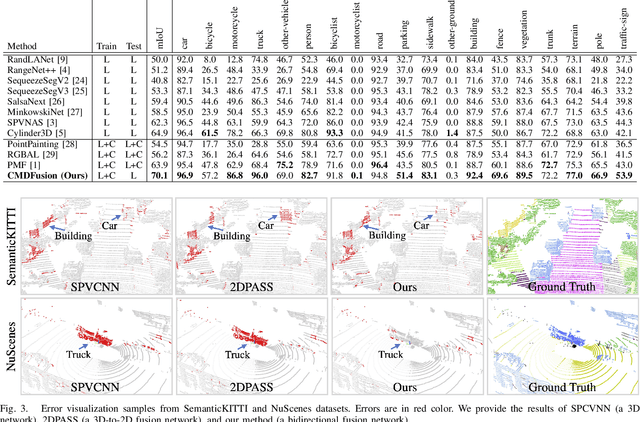

2D RGB images and 3D LIDAR point clouds provide complementary knowledge for the perception system of autonomous vehicles. Several 2D and 3D fusion methods have been explored for the LIDAR semantic segmentation task, but they suffer from different problems. 2D-to-3D fusion methods require strictly paired data during inference, which may not be available in real-world scenarios, while 3D-to-2D fusion methods cannot explicitly make full use of the 2D information. Therefore, we propose a Bidirectional Fusion Network with Cross-Modality Knowledge Distillation (CMDFusion) in this work. Our method has two contributions. First, our bidirectional fusion scheme explicitly and implicitly enhances the 3D feature via 2D-to-3D fusion and 3D-to-2D fusion, respectively, which surpasses either one of the single fusion schemes. Second, we distillate the 2D knowledge from a 2D network (Camera branch) to a 3D network (2D knowledge branch) so that the 3D network can generate 2D information even for those points not in the FOV (field of view) of the camera. In this way, RGB images are not required during inference anymore since the 2D knowledge branch provides 2D information according to the 3D LIDAR input. We show that our CMDFusion achieves the best performance among all fusion-based methods on SemanticKITTI and nuScenes datasets. The code will be released at https://github.com/Jun-CEN/CMDFusion.
SAD: Segment Any RGBD
May 23, 2023The Segment Anything Model (SAM) has demonstrated its effectiveness in segmenting any part of 2D RGB images. However, SAM exhibits a stronger emphasis on texture information while paying less attention to geometry information when segmenting RGB images. To address this limitation, we propose the Segment Any RGBD (SAD) model, which is specifically designed to extract geometry information directly from images. Inspired by the natural ability of humans to identify objects through the visualization of depth maps, SAD utilizes SAM to segment the rendered depth map, thus providing cues with enhanced geometry information and mitigating the issue of over-segmentation. We further include the open-vocabulary semantic segmentation in our framework, so that the 3D panoptic segmentation is fulfilled. The project is available on https://github.com/Jun-CEN/SegmentAnyRGBD.
Enlarging Instance-specific and Class-specific Information for Open-set Action Recognition
Mar 25, 2023Open-set action recognition is to reject unknown human action cases which are out of the distribution of the training set. Existing methods mainly focus on learning better uncertainty scores but dismiss the importance of feature representations. We find that features with richer semantic diversity can significantly improve the open-set performance under the same uncertainty scores. In this paper, we begin with analyzing the feature representation behavior in the open-set action recognition (OSAR) problem based on the information bottleneck (IB) theory, and propose to enlarge the instance-specific (IS) and class-specific (CS) information contained in the feature for better performance. To this end, a novel Prototypical Similarity Learning (PSL) framework is proposed to keep the instance variance within the same class to retain more IS information. Besides, we notice that unknown samples sharing similar appearances to known samples are easily misclassified as known classes. To alleviate this issue, video shuffling is further introduced in our PSL to learn distinct temporal information between original and shuffled samples, which we find enlarges the CS information. Extensive experiments demonstrate that the proposed PSL can significantly boost both the open-set and closed-set performance and achieves state-of-the-art results on multiple benchmarks. Code is available at https://github.com/Jun-CEN/PSL.
The Devil is in the Wrongly-classified Samples: Towards Unified Open-set Recognition
Feb 08, 2023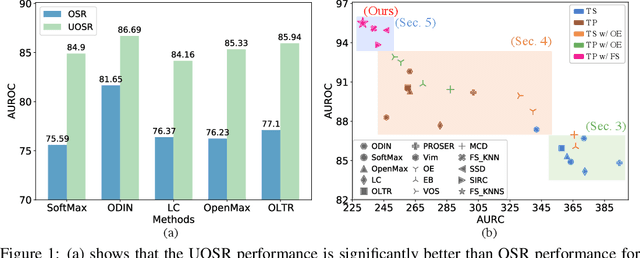
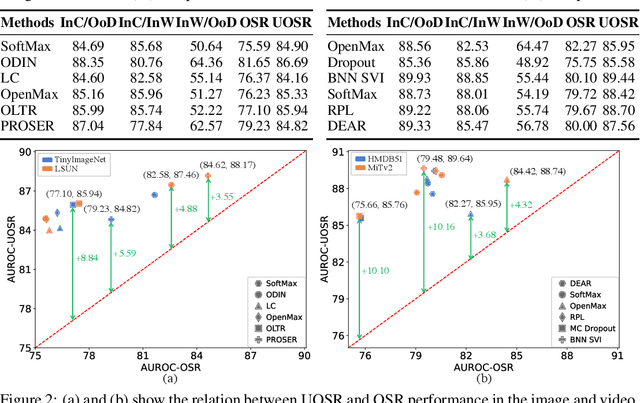
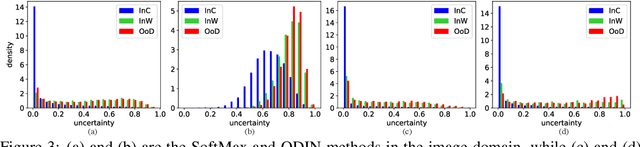
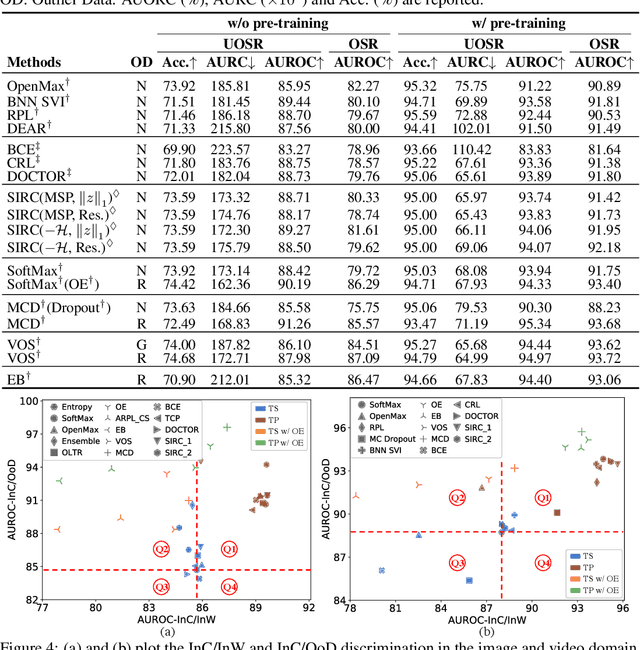
Open-set Recognition (OSR) aims to identify test samples whose classes are not seen during the training process. Recently, Unified Open-set Recognition (UOSR) has been proposed to reject not only unknown samples but also known but wrongly classified samples, which tends to be more practical in real-world applications. The UOSR draws little attention since it is proposed, but we find sometimes it is even more practical than OSR in the real world applications, as evaluation results of known but wrongly classified samples are also wrong like unknown samples. In this paper, we deeply analyze the UOSR task under different training and evaluation settings to shed light on this promising research direction. For this purpose, we first evaluate the UOSR performance of several OSR methods and show a significant finding that the UOSR performance consistently surpasses the OSR performance by a large margin for the same method. We show that the reason lies in the known but wrongly classified samples, as their uncertainty distribution is extremely close to unknown samples rather than known and correctly classified samples. Second, we analyze how the two training settings of OSR (i.e., pre-training and outlier exposure) influence the UOSR. We find although they are both beneficial for distinguishing known and correctly classified samples from unknown samples, pre-training is also helpful for identifying known but wrongly classified samples while outlier exposure is not. In addition to different training settings, we also formulate a new evaluation setting for UOSR which is called few-shot UOSR, where only one or five samples per unknown class are available during evaluation to help identify unknown samples. We propose FS-KNNS for the few-shot UOSR to achieve state-of-the-art performance under all settings.
Learning a Condensed Frame for Memory-Efficient Video Class-Incremental Learning
Nov 02, 2022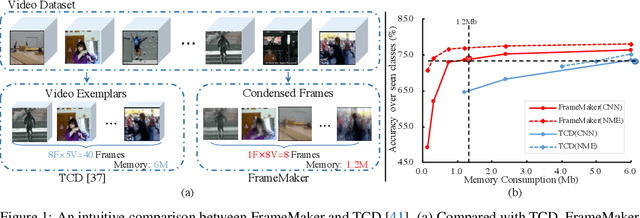
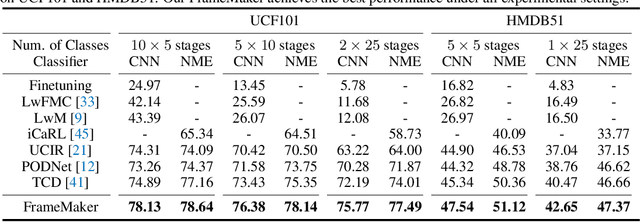
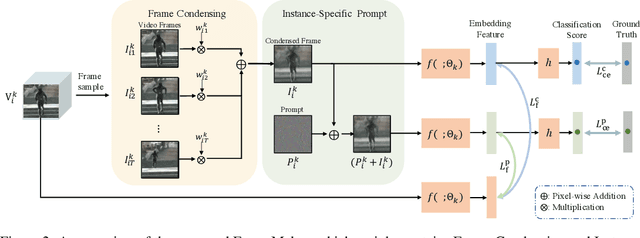
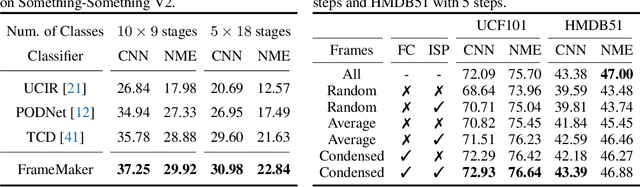
Recent incremental learning for action recognition usually stores representative videos to mitigate catastrophic forgetting. However, only a few bulky videos can be stored due to the limited memory. To address this problem, we propose FrameMaker, a memory-efficient video class-incremental learning approach that learns to produce a condensed frame for each selected video. Specifically, FrameMaker is mainly composed of two crucial components: Frame Condensing and Instance-Specific Prompt. The former is to reduce the memory cost by preserving only one condensed frame instead of the whole video, while the latter aims to compensate the lost spatio-temporal details in the Frame Condensing stage. By this means, FrameMaker enables a remarkable reduction in memory but keep enough information that can be applied to following incremental tasks. Experimental results on multiple challenging benchmarks, i.e., HMDB51, UCF101 and Something-Something V2, demonstrate that FrameMaker can achieve better performance to recent advanced methods while consuming only 20% memory. Additionally, under the same memory consumption conditions, FrameMaker significantly outperforms existing state-of-the-arts by a convincing margin.