 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREVEAL: Reference-Grounded Reasoning for Multimodal Manipulation Detection
May 27, 2026Multimodal manipulation detection aims to simultaneously identify forged image--text pairs and localize tampered regions, yet existing methods typically rely on memorizing isolated artifacts and struggle with imperceptible manipulation traces or domain shifts. Inspired by human comparative reasoning, we reformulate this task as a reference-grounded verification problem, where authenticity is assessed by comparing a query against retrieved authentic evidence. We propose REVEAL Reference-Enabled Verification for Evidence Analysis and Localization), a framework explicitly designed for this comparative paradigm. To support this paradigm, we construct a large-scale reference library comprising 170K authentic news image--text pairs featuring over 40K public figures. Technically, REVEAL employs a difference-aware fusion mechanism to capture fine-grained discrepancies between the query and retrieved evidence. Furthermore, we introduce a task-decoupled Mixture-of-Experts (MoE) architecture to jointly execute instance-level detection and fine-grained grounding, effectively mitigating optimization conflicts between these heterogeneous objectives. Extensive experiments demonstrate that REVEAL significantly outperforms state-of-the-art methods, and notably enables \emph{training-free domain adaptation} by simply updating the reference library, offering a robust and practical solution for detecting evolving misinformation. Code is available at https://anonymous.4open.science/r/REVEAL-Reference-A006.
CanonSLR: Canonical-View Guided Multi-View Continuous Sign Language Recognition
Apr 20, 2026Continuous Sign Language Recognition (CSLR) has achieved remarkable progress in recent years; however, most existing methods are developed under single-view settings and thus remain insufficiently robust to viewpoint variations in real-world scenarios. To address this limitation, we propose CanonSLR, a canonical-view guided framework for multi-view CSLR. Specifically, we introduce a frontal-view-anchored teacher-student learning strategy, in which a teacher network trained on frontal-view data provides canonical temporal supervision for a student network trained on all viewpoints. To further reduce cross-view semantic discrepancy, we propose Sequence-Level Soft-Target Distillation, which transfers structured temporal knowledge from the frontal view to non-frontal samples, thereby alleviating gloss boundary ambiguity and category confusion caused by occlusion and projection variation. In addition, we introduce Temporal Motion Relational Enhancement to explicitly model motion-aware temporal relations in high-level visual features, strengthening stable dynamic representations while suppressing viewpoint-sensitive appearance disturbances. To support multi-view CSLR research, we further develop a universal multi-view sign language data construction pipeline that transforms original single-view RGB videos into semantically consistent, temporally coherent, and viewpoint-controllable multi-view sign language videos. Based on this pipeline, we extend PHOENIX-2014T and CSL-Daily into two seven-view benchmarks, namely PT14-MV and CSL-MV, providing a new experimental foundation for multi-view CSLR. Extensive experiments on PT14-MV and CSL-MV demonstrate that CanonSLR consistently outperforms existing approaches under multi-view settings and exhibits stronger robustness, especially on challenging non-frontal views.
Pretrain-then-Adapt: Uncertainty-Aware Test-Time Adaptation for Text-based Person Search
Apr 07, 2026Text-based person search faces inherent limitations due to data scarcity, driven by stringent privacy constraints and the high cost of manual annotation. To mitigate this, existing methods usually rely on a Pretrain-then-Finetune paradigm, where models are first pretrained on synthetic person-caption data to establish cross-modal alignment, followed by fine-tuning on labeled real-world datasets. However, this paradigm lacks practicality in real-world deployment scenarios, where large-scale annotated target-domain data is typically inaccessible. In this work, we propose a new Pretrain-then-Adapt paradigm that eliminates reliance on extensive target-domain supervision through an offline test-time adaptation manner, enabling dynamic model adaptation using only unlabeled test data with minimal post-train time cost. To mitigate overconfidence with false positives of previous entropy-based test-time adaptation, we propose an Uncertainty-Aware Test-Time Adaptation (UATTA) framework, which introduces a bidirectional retrieval disagreement mechanism to estimate uncertainty, i.e., low uncertainty is assigned when an image-text pair ranks highly in both image-to-text and text-to-image retrieval, indicating high alignment; otherwise, high uncertainty is detected. This indicator drives offline test-time model recalibration without labels, effectively mitigating domain shift. We validate UATTA on four benchmarks, i.e., CUHK-PEDES, ICFG-PEDES, RSTPReid, and PAB, showing consistent improvements across both CLIP-based (one-stage) and XVLM-based (two-stage) frameworks. Ablation studies confirm that UATTA outperforms existing offline test-time adaptation strategies, establishing a new benchmark for label-efficient, deployable person search systems. Our code is available at https://github.com/nkuzjh/UATTA.
Can Video Diffusion Models Predict Past Frames? Bidirectional Cycle Consistency for Reversible Interpolation
Apr 02, 2026Video frame interpolation aims to synthesize realistic intermediate frames between given endpoints while adhering to specific motion semantics. While recent generative models have improved visual fidelity, they predominantly operate in a unidirectional manner, lacking mechanisms to self-verify temporal consistency. This often leads to motion drift, directional ambiguity, and boundary misalignment, especially in long-range sequences. Inspired by the principle of temporal cycle-consistency in self-supervised learning, we propose a novel bidirectional framework that enforces symmetry between forward and backward generation trajectories. Our approach introduces learnable directional tokens to explicitly condition a shared backbone on temporal orientation, enabling the model to jointly optimize forward synthesis and backward reconstruction within a single unified architecture. This cycle-consistent supervision acts as a powerful regularizer, ensuring that generated motion paths are logically reversible. Furthermore, we employ a curriculum learning strategy that progressively trains the model from short to long sequences, stabilizing dynamics across varying durations. Crucially, our cyclic constraints are applied only during training; inference requires a single forward pass, maintaining the high efficiency of the base model. Extensive experiments show that our method achieves state-of-the-art performance in imaging quality, motion smoothness, and dynamic control on both 37-frame and 73-frame tasks, outperforming strong baselines while incurring no additional computational overhead.
Look, Compare and Draw: Differential Query Transformer for Automatic Oil Painting
Mar 29, 2026This work introduces a new approach to automatic oil painting that emphasizes the creation of dynamic and expressive brushstrokes. A pivotal challenge lies in mitigating the duplicate and common-place strokes, which often lead to less aesthetic outcomes. Inspired by the human painting process, \ie, observing, comparing, and drawing, we incorporate differential image analysis into a neural oil painting model, allowing the model to effectively concentrate on the incremental impact of successive brushstrokes. To operationalize this concept, we propose the Differential Query Transformer (DQ-Transformer), a new architecture that leverages differentially derived image representations enriched with positional encoding to guide the stroke prediction process. This integration enables the model to maintain heightened sensitivity to local details, resulting in more refined and nuanced stroke generation. Furthermore, we incorporate adversarial training into our framework, enhancing the accuracy of stroke prediction and thereby improving the overall realism and fidelity of the synthesized paintings. Extensive qualitative evaluations, complemented by a controlled user study, validate that our DQ-Transformer surpasses existing methods in both visual realism and artistic authenticity, typically achieving these results with fewer strokes. The stroke-by-stroke painting animations are available on our project website.
Process Over Outcome: Cultivating Forensic Reasoning for Generalizable Multimodal Manipulation Detection
Mar 02, 2026Recent advances in generative AI have significantly enhanced the realism of multimodal media manipulation, thereby posing substantial challenges to manipulation detection. Existing manipulation detection and grounding approaches predominantly focus on manipulation type classification under result-oriented supervision, which not only lacks interpretability but also tends to overfit superficial artifacts. In this paper, we argue that generalizable detection requires incorporating explicit forensic reasoning, rather than merely classifying a limited set of manipulation types, which fails to generalize to unseen manipulation patterns. To this end, we propose REFORM, a reasoning-driven framework that shifts learning from outcome fitting to process modeling. REFORM adopts a three-stage curriculum that first induces forensic rationales, then aligns reasoning with final judgments, and finally refines logical consistency via reinforcement learning. To support this paradigm, we introduce ROM, a large-scale dataset with rich reasoning annotations. Extensive experiments show that REFORM establishes new state-of-the-art performance with superior generalization, achieving 81.52% ACC on ROM, 76.65% ACC on DGM4, and 74.9 F1 on MMFakeBench.
OmniVL-Guard: Towards Unified Vision-Language Forgery Detection and Grounding via Balanced RL
Feb 12, 2026Existing forgery detection methods are often limited to uni-modal or bi-modal settings, failing to handle the interleaved text, images, and videos prevalent in real-world misinformation. To bridge this gap, this paper targets to develop a unified framework for omnibus vision-language forgery detection and grounding. In this unified setting, the {interplay} between diverse modalities and the dual requirements of simultaneous detection and localization pose a critical ``difficulty bias`` problem: the simpler veracity classification task tends to dominate the gradients, leading to suboptimal performance in fine-grained grounding during multi-task optimization. To address this challenge, we propose \textbf{OmniVL-Guard}, a balanced reinforcement learning framework for omnibus vision-language forgery detection and grounding. Particularly, OmniVL-Guard comprises two core designs: Self-Evolving CoT Generatio and Adaptive Reward Scaling Policy Optimization (ARSPO). {Self-Evolving CoT Generation} synthesizes high-quality reasoning paths, effectively overcoming the cold-start challenge. Building upon this, {Adaptive Reward Scaling Policy Optimization (ARSPO)} dynamically modulates reward scales and task weights, ensuring a balanced joint optimization. Extensive experiments demonstrate that OmniVL-Guard significantly outperforms state-of-the-art methods and exhibits zero-shot robust generalization across out-of-domain scenarios.
Tears or Cheers? Benchmarking LLMs via Culturally Elicited Distinct Affective Responses
Jan 19, 2026Culture serves as a fundamental determinant of human affective processing and profoundly shapes how individuals perceive and interpret emotional stimuli. Despite this intrinsic link extant evaluations regarding cultural alignment within Large Language Models primarily prioritize declarative knowledge such as geographical facts or established societal customs. These benchmarks remain insufficient to capture the subjective interpretative variance inherent to diverse sociocultural lenses. To address this limitation, we introduce CEDAR, a multimodal benchmark constructed entirely from scenarios capturing Culturally \underline{\textsc{E}}licited \underline{\textsc{D}}istinct \underline{\textsc{A}}ffective \underline{\textsc{R}}esponses. To construct CEDAR, we implement a novel pipeline that leverages LLM-generated provisional labels to isolate instances yielding cross-cultural emotional distinctions, and subsequently derives reliable ground-truth annotations through rigorous human evaluation. The resulting benchmark comprises 10,962 instances across seven languages and 14 fine-grained emotion categories, with each language including 400 multimodal and 1,166 text-only samples. Comprehensive evaluations of 17 representative multilingual models reveal a dissociation between language consistency and cultural alignment, demonstrating that culturally grounded affective understanding remains a significant challenge for current models.
TDEdit: A Unified Diffusion Framework for Text-Drag Guided Image Manipulation
Sep 26, 2025This paper explores image editing under the joint control of text and drag interactions. While recent advances in text-driven and drag-driven editing have achieved remarkable progress, they suffer from complementary limitations: text-driven methods excel in texture manipulation but lack precise spatial control, whereas drag-driven approaches primarily modify shape and structure without fine-grained texture guidance. To address these limitations, we propose a unified diffusion-based framework for joint drag-text image editing, integrating the strengths of both paradigms. Our framework introduces two key innovations: (1) Point-Cloud Deterministic Drag, which enhances latent-space layout control through 3D feature mapping, and (2) Drag-Text Guided Denoising, dynamically balancing the influence of drag and text conditions during denoising. Notably, our model supports flexible editing modes - operating with text-only, drag-only, or combined conditions - while maintaining strong performance in each setting. Extensive quantitative and qualitative experiments demonstrate that our method not only achieves high-fidelity joint editing but also matches or surpasses the performance of specialized text-only or drag-only approaches, establishing a versatile and generalizable solution for controllable image manipulation. Code will be made publicly available to reproduce all results presented in this work.
Beyond Artificial Misalignment: Detecting and Grounding Semantic-Coordinated Multimodal Manipulations
Sep 16, 2025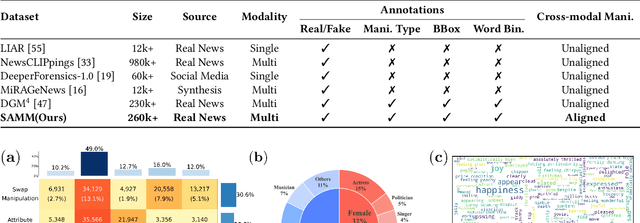
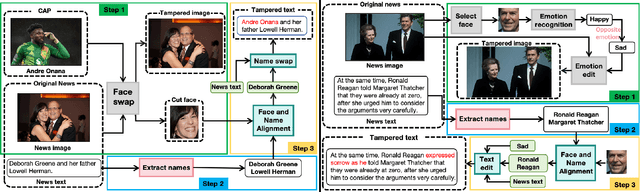
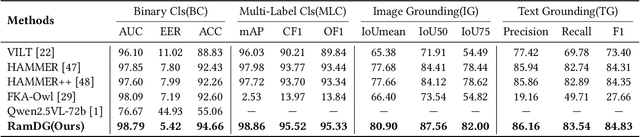
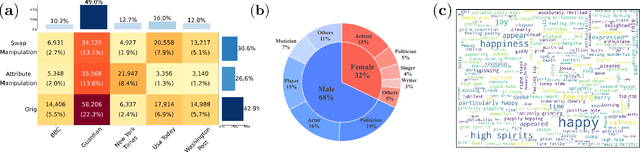
The detection and grounding of manipulated content in multimodal data has emerged as a critical challenge in media forensics. While existing benchmarks demonstrate technical progress, they suffer from misalignment artifacts that poorly reflect real-world manipulation patterns: practical attacks typically maintain semantic consistency across modalities, whereas current datasets artificially disrupt cross-modal alignment, creating easily detectable anomalies. To bridge this gap, we pioneer the detection of semantically-coordinated manipulations where visual edits are systematically paired with semantically consistent textual descriptions. Our approach begins with constructing the first Semantic-Aligned Multimodal Manipulation (SAMM) dataset, generated through a two-stage pipeline: 1) applying state-of-the-art image manipulations, followed by 2) generation of contextually-plausible textual narratives that reinforce the visual deception. Building on this foundation, we propose a Retrieval-Augmented Manipulation Detection and Grounding (RamDG) framework. RamDG commences by harnessing external knowledge repositories to retrieve contextual evidence, which serves as the auxiliary texts and encoded together with the inputs through our image forgery grounding and deep manipulation detection modules to trace all manipulations. Extensive experiments demonstrate our framework significantly outperforms existing methods, achieving 2.06\% higher detection accuracy on SAMM compared to state-of-the-art approaches. The dataset and code are publicly available at https://github.com/shen8424/SAMM-RamDG-CAP.