 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA High-Dimensional Feature Selection Algorithm Based on Multiobjective Differential Evolution
May 09, 2025



Multiobjective feature selection seeks to determine the most discriminative feature subset by simultaneously optimizing two conflicting objectives: minimizing the number of selected features and the classification error rate. The goal is to enhance the model's predictive performance and computational efficiency. However, feature redundancy and interdependence in high-dimensional data present considerable obstacles to the search efficiency of optimization algorithms and the quality of the resulting solutions. To tackle these issues, we propose a high-dimensional feature selection algorithm based on multiobjective differential evolution. First, a population initialization strategy is designed by integrating feature weights and redundancy indices, where the population is divided into four subpopulations to improve the diversity and uniformity of the initial population. Then, a multiobjective selection mechanism is developed, in which feature weights guide the mutation process. The solution quality is further enhanced through nondominated sorting, with preference given to solutions with lower classification error, effectively balancing global exploration and local exploitation. Finally, an adaptive grid mechanism is applied in the objective space to identify densely populated regions and detect duplicated solutions. Experimental results on 11 UCI datasets of varying difficulty demonstrate that the proposed method significantly outperforms several state-of-the-art multiobjective feature selection approaches regarding feature selection performance.
ASAP: Advancing Semantic Alignment Promotes Multi-Modal Manipulation Detecting and Grounding
Dec 17, 2024



We present ASAP, a new framework for detecting and grounding multi-modal media manipulation (DGM4).Upon thorough examination, we observe that accurate fine-grained cross-modal semantic alignment between the image and text is vital for accurately manipulation detection and grounding. While existing DGM4 methods pay rare attention to the cross-modal alignment, hampering the accuracy of manipulation detecting to step further. To remedy this issue, this work targets to advance the semantic alignment learning to promote this task. Particularly, we utilize the off-the-shelf Multimodal Large-Language Models (MLLMs) and Large Language Models (LLMs) to construct paired image-text pairs, especially for the manipulated instances. Subsequently, a cross-modal alignment learning is performed to enhance the semantic alignment. Besides the explicit auxiliary clues, we further design a Manipulation-Guided Cross Attention (MGCA) to provide implicit guidance for augmenting the manipulation perceiving. With the grounding truth available during training, MGCA encourages the model to concentrate more on manipulated components while downplaying normal ones, enhancing the model's ability to capture manipulations. Extensive experiments are conducted on the DGM4 dataset, the results demonstrate that our model can surpass the comparison method with a clear margin.
An Adaptive Balance Search Based Complementary Heterogeneous Particle Swarm Optimization Architecture
Dec 17, 2024



A series of modified cognitive-only particle swarm optimization (PSO) algorithms effectively mitigate premature convergence by constructing distinct vectors for different particles. However, the underutilization of these constructed vectors hampers convergence accuracy. In this paper, an adaptive balance search based complementary heterogeneous PSO architecture is proposed, which consists of a complementary heterogeneous PSO (CHxPSO) framework and an adaptive balance search (ABS) strategy. The CHxPSO framework mainly includes two update channels and two subswarms. Two channels exhibit nearly heterogeneous properties while sharing a common constructed vector. This ensures that one constructed vector is utilized across both heterogeneous update mechanisms. The two subswarms work within their respective channels during the evolutionary process, preventing interference between the two channels. The ABS strategy precisely controls the proportion of particles involved in the evolution in the two channels, and thereby guarantees the flexible utilization of the constructed vectors, based on the evolutionary process and the interactions with the problem's fitness landscape. Together, our architecture ensures the effective utilization of the constructed vectors by emphasizing exploration in the early evolutionary process while exploitation in the later, enhancing the performance of a series of modified cognitive-only PSOs. Extensive experimental results demonstrate the generalization performance of our architecture.
CodeV: Empowering LLMs for Verilog Generation through Multi-Level Summarization
Jul 16, 2024The increasing complexity and high costs associated with modern processor design have led to a surge in demand for processor design automation. Instruction-tuned large language models (LLMs) have demonstrated remarkable performance in automatically generating code for general-purpose programming languages like Python. However, these methods fail on hardware description languages (HDLs) like Verilog due to the scarcity of high-quality instruction tuning data, as even advanced LLMs like GPT-3.5 exhibit limited performance on Verilog generation. Regarding this issue, we observe that (1) Verilog code collected from the real world has higher quality than those generated by LLMs. (2) LLMs like GPT-3.5 excel in summarizing Verilog code rather than generating it. Based on these observations, this paper introduces CodeV, a series of open-source instruction-tuned Verilog generation LLMs. Instead of generating descriptions first and then getting the corresponding code from advanced LLMs, we prompt the LLM with Verilog code and let the LLM generate the corresponding natural language description by multi-level summarization. Experimental results show that CodeV relatively surpasses the previous open-source SOTA by 14.4% (BetterV in VerilogEval) and 11.3% (RTLCoder in RTLLM) respectively, and also relatively outperforms previous commercial SOTA GPT-4 by 22.1% in VerilogEval.
A Dual-Channel Particle Swarm Optimization Algorithm Based on Adaptive Balance Search
Jun 25, 2024The balance between exploration (Er) and exploitation (Ei) determines the generalization performance of the particle swarm optimization (PSO) algorithm on different problems. Although the insufficient balance caused by global best being located near a local minimum has been widely researched, few scholars have systematically paid attention to two behaviors about personal best position (P) and global best position (G) existing in PSO. 1) P's uncontrollable-exploitation and involuntary-exploration guidance behavior. 2) G's full-time and global guidance behavior, each of which negatively affects the balance of Er and Ei. With regards to this, we firstly discuss the two behaviors, unveiling the mechanisms by which they affect the balance, and further pinpoint three key points for better balancing Er and Ei: eliminating the coupling between P and G, empowering P with controllable-exploitation and voluntary-exploration guidance behavior, controlling G's full-time and global guidance behavior. Then, we present a dual-channel PSO algorithm based on adaptive balance search (DCPSO-ABS). This algorithm entails a dual-channel framework to mitigate the interaction of P and G, aiding in regulating the behaviors of P and G, and meanwhile an adaptive balance search strategy for empowering P with voluntary-exploration and controllable-exploitation guidance behavior as well as adaptively controlling G's full-time and global guidance behavior. Finally, three kinds of experiments on 57 benchmark functions are designed to demonstrate that our proposed algorithm has stronger generalization performance than selected state-of-the-art algorithms.
Feature Selection Based on Orthogonal Constraints and Polygon Area
Feb 25, 2024The goal of feature selection is to choose the optimal subset of features for a recognition task by evaluating the importance of each feature, thereby achieving effective dimensionality reduction. Currently, proposed feature selection methods often overlook the discriminative dependencies between features and labels. To address this problem, this paper introduces a novel orthogonal regression model incorporating the area of a polygon. The model can intuitively capture the discriminative dependencies between features and labels. Additionally, this paper employs a hybrid non-monotone linear search method to efficiently tackle the non-convex optimization challenge posed by orthogonal constraints. Experimental results demonstrate that our approach not only effectively captures discriminative dependency information but also surpasses traditional methods in reducing feature dimensions and enhancing classification performance.
Fusion-S2iGan: An Efficient and Effective Single-Stage Framework for Speech-to-Image Generation
May 17, 2023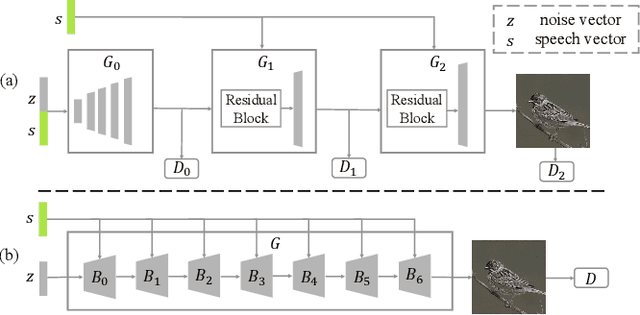
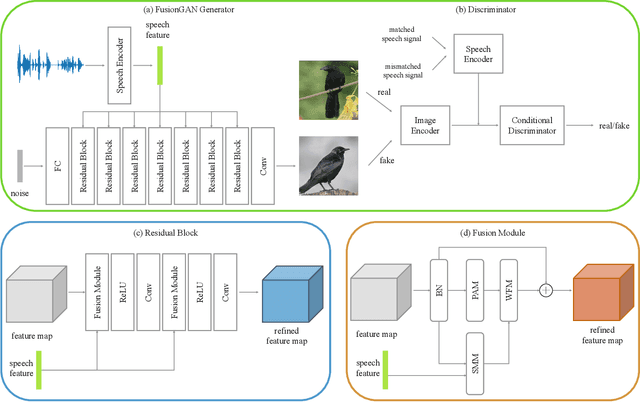
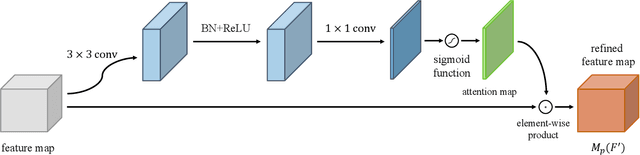
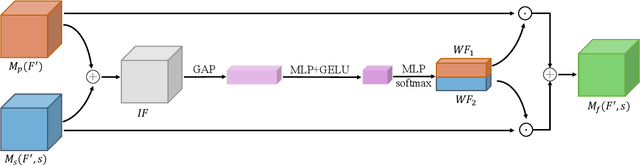
The goal of a speech-to-image transform is to produce a photo-realistic picture directly from a speech signal. Recently, various studies have focused on this task and have achieved promising performance. However, current speech-to-image approaches are based on a stacked modular framework that suffers from three vital issues: 1) Training separate networks is time-consuming as well as inefficient and the convergence of the final generative model strongly depends on the previous generators; 2) The quality of precursor images is ignored by this architecture; 3) Multiple discriminator networks are required to be trained. To this end, we propose an efficient and effective single-stage framework called Fusion-S2iGan to yield perceptually plausible and semantically consistent image samples on the basis of given spoken descriptions. Fusion-S2iGan introduces a visual+speech fusion module (VSFM), constructed with a pixel-attention module (PAM), a speech-modulation module (SMM) and a weighted-fusion module (WFM), to inject the speech embedding from a speech encoder into the generator while improving the quality of synthesized pictures. Fusion-S2iGan spreads the bimodal information over all layers of the generator network to reinforce the visual feature maps at various hierarchical levels in the architecture. We conduct a series of experiments on four benchmark data sets, i.e., CUB birds, Oxford-102, Flickr8k and Places-subset. The experimental results demonstrate the superiority of the presented Fusion-S2iGan compared to the state-of-the-art models with a multi-stage architecture and a performance level that is close to traditional text-to-image approaches.
Optimized latent-code selection for explainable conditional text-to-image GANs
Apr 27, 2022
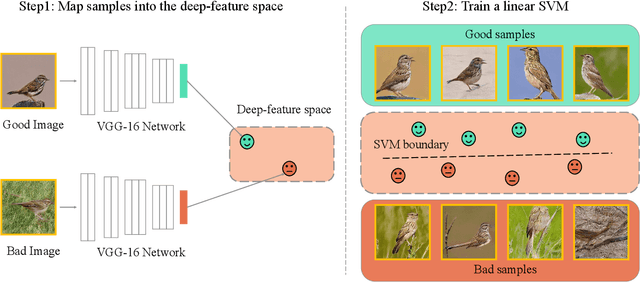


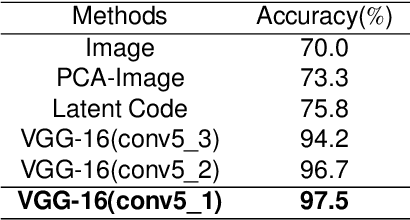
The task of text-to-image generation has achieved remarkable progress due to the advances in the conditional generative adversarial networks (GANs). However, existing conditional text-to-image GANs approaches mostly concentrate on improving both image quality and semantic relevance but ignore the explainability of the model which plays a vital role in real-world applications. In this paper, we present a variety of techniques to take a deep look into the latent space and semantic space of the conditional text-to-image GANs model. We introduce pairwise linear interpolation of latent codes and `linguistic' linear interpolation to study what the model has learned within the latent space and `linguistic' embeddings. Subsequently, we extend linear interpolation to triangular interpolation conditioned on three corners to further analyze the model. After that, we build a Good/Bad data set containing unsuccessfully and successfully synthetic samples and corresponding latent codes for the image-quality research. Based on this data set, we propose a framework for finding good latent codes by utilizing a linear SVM. Experimental results on the recent DiverGAN generator trained on two benchmark data sets qualitatively prove the effectiveness of our presented techniques, with a better than 94\% accuracy in predicting ${Good}$/${Bad}$ classes for latent vectors. The Good/Bad data set is publicly available at https://zenodo.org/record/5850224#.YeGMwP7MKUk.
OptGAN: Optimizing and Interpreting the Latent Space of the Conditional Text-to-Image GANs
Feb 25, 2022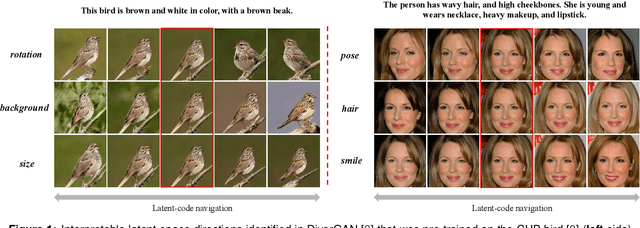

Text-to-image generation intends to automatically produce a photo-realistic image, conditioned on a textual description. It can be potentially employed in the field of art creation, data augmentation, photo-editing, etc. Although many efforts have been dedicated to this task, it remains particularly challenging to generate believable, natural scenes. To facilitate the real-world applications of text-to-image synthesis, we focus on studying the following three issues: 1) How to ensure that generated samples are believable, realistic or natural? 2) How to exploit the latent space of the generator to edit a synthesized image? 3) How to improve the explainability of a text-to-image generation framework? In this work, we constructed two novel data sets (i.e., the Good & Bad bird and face data sets) consisting of successful as well as unsuccessful generated samples, according to strict criteria. To effectively and efficiently acquire high-quality images by increasing the probability of generating Good latent codes, we use a dedicated Good/Bad classifier for generated images. It is based on a pre-trained front end and fine-tuned on the basis of the proposed Good & Bad data set. After that, we present a novel algorithm which identifies semantically-understandable directions in the latent space of a conditional text-to-image GAN architecture by performing independent component analysis on the pre-trained weight values of the generator. Furthermore, we develop a background-flattening loss (BFL), to improve the background appearance in the edited image. Subsequently, we introduce linear interpolation analysis between pairs of keywords. This is extended into a similar triangular `linguistic' interpolation in order to take a deep look into what a text-to-image synthesis model has learned within the linguistic embeddings. Our data set is available at https://zenodo.org/record/6283798#.YhkN_ujMI2w.
DiverGAN: An Efficient and Effective Single-Stage Framework for Diverse Text-to-Image Generation
Nov 17, 2021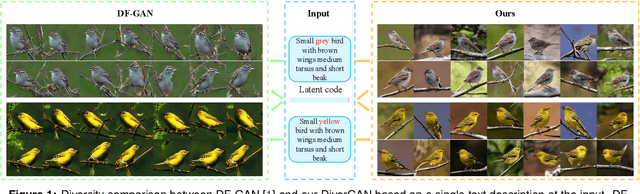
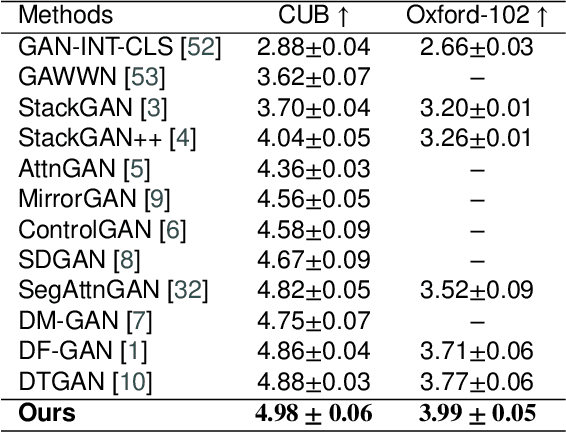
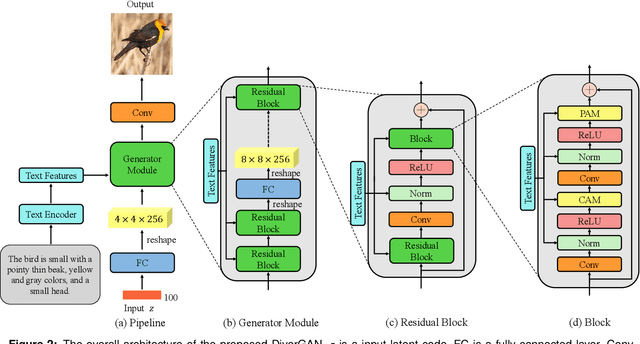
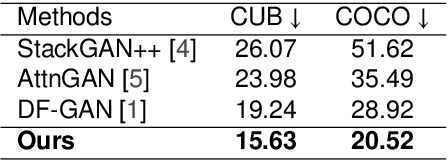
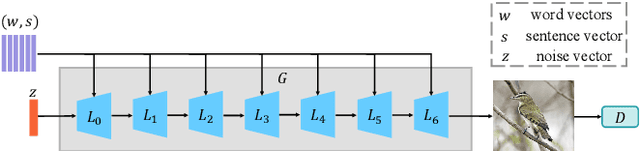
In this paper, we present an efficient and effective single-stage framework (DiverGAN) to generate diverse, plausible and semantically consistent images according to a natural-language description. DiverGAN adopts two novel word-level attention modules, i.e., a channel-attention module (CAM) and a pixel-attention module (PAM), which model the importance of each word in the given sentence while allowing the network to assign larger weights to the significant channels and pixels semantically aligning with the salient words. After that, Conditional Adaptive Instance-Layer Normalization (CAdaILN) is introduced to enable the linguistic cues from the sentence embedding to flexibly manipulate the amount of change in shape and texture, further improving visual-semantic representation and helping stabilize the training. Also, a dual-residual structure is developed to preserve more original visual features while allowing for deeper networks, resulting in faster convergence speed and more vivid details. Furthermore, we propose to plug a fully-connected layer into the pipeline to address the lack-of-diversity problem, since we observe that a dense layer will remarkably enhance the generative capability of the network, balancing the trade-off between a low-dimensional random latent code contributing to variants and modulation modules that use high-dimensional and textual contexts to strength feature maps. Inserting a linear layer after the second residual block achieves the best variety and quality. Both qualitative and quantitative results on benchmark data sets demonstrate the superiority of our DiverGAN for realizing diversity, without harming quality and semantic consistency.